






目录
1. 概述
本文是作者自学深度学习的第3篇章(学习资料为李沐老师的深度学习课程),对多层感知机(MLP)的网络架构、矩阵表达、激活函数、权重衰退、丢弃法(dropout)等内容进行了整理和归纳。
2. 网络架构
多层感知机通常被认为是神经网络的代表,和单层神经网络不同,多层感知机往往具有多个隐藏层,以此来提升模型的表达能力,其网络架构如下

其中 x = {x1, x2, x3, x4}表示1个样本的输入,特征大小为 4,h = {h1, h2, h3, h4, h5}表示隐藏层的神经元,个数为5。o = {o1, o2, o3} 表示数据的输出,如在分类模型中,o1-o3可以分别表示猫、狗、鸡的概率。
3. 矩阵表达
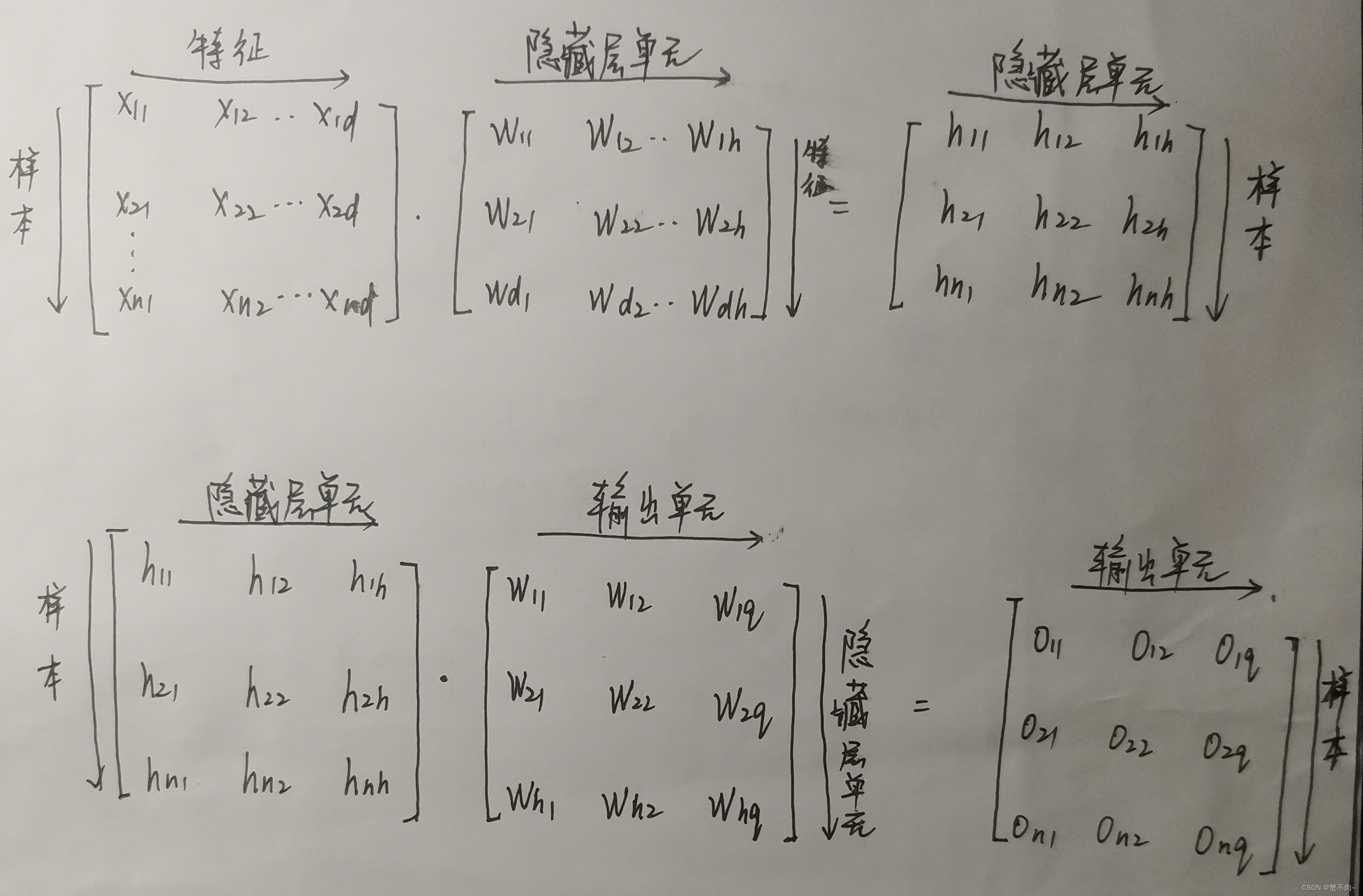
对于上图具有单隐藏层的网络,我们可以使用如下方式表示:
- 其中,X为特征矩阵,行数 = 样本数,列数 = 特征数。
- W(1)为输入层到隐藏层的权重矩阵,行数 = 特征数,列数 = 隐藏层神经元数。
- H为隐藏层矩阵,行数 = 样本数,列数 = 隐藏层神经元个数。
- W(2)为隐藏层到输出层的权重矩阵,行数 = 隐藏层神经元个数,列数 = 输出神经元个数。
- O为输出矩阵,行数 = 样本数, 列数 = 输出神经元个数。
- b为偏置项。
4. 激活函数
理论上可以证明,上述MLP模型和单层神经网络等价,为了使得多层感知机具有更好的表达能力,考虑使用激活函数 给模型添加非线性性,则模型可以表示为
即将第1隐藏层的输出经过非线性变换后在输入到下一层网络。 常见的激活函数如下:
- ReLu
- sigmoid
- tanh
5. 权重衰退
为了避免过拟合问题,常引入正则化技术,所谓正则化就是使得模型的权重系数尽量集中在原点附近,常用的做法是将权重的范数添加到损失函数中,以L2范数为例,损失函数可以定义为:
对权重w求偏导可得:
则有权重更新:
即每次迭代后,w都会进行一定程度的衰退。
6. 丢弃法(dropout)
除了正则化方法之外,丢弃法也是避免模型过拟合的常用方法之一,其网络结构如下所示:
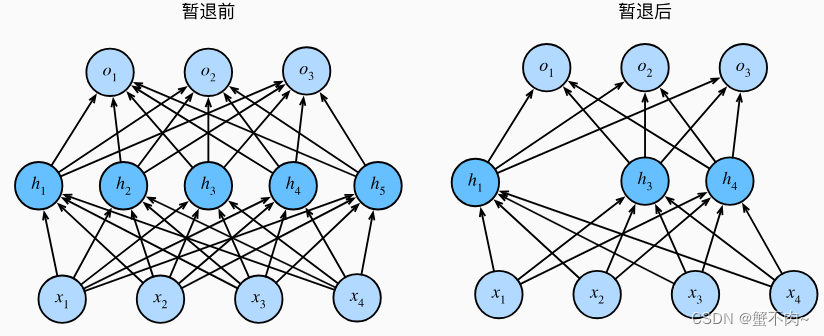
即以一定的概率对隐藏层的输出置为0(即丢弃),使得模型整体更为稳定,具体而言,模型以下述方式进行丢弃:
![]()
注意到经过丢弃后,隐藏层期望不变,即。















 1万+
1万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









