










目录
1. 概述
本文是作者自学深度学习的起始篇章(主要课程资料为李沐大神的深度学习课程),主要介绍了线性回归模型中的一些基本概念:如模型的矩阵表达、损失函数、梯度下降,以及如何从线性回归模型过渡到单层神经网络。
2. 线性回归模型
按照自己的理解而言,线性回归模型主要是用于求解因变量Y,和自变量X之间的线性关系。其中X可以具有多个特征。例如,一间房子的房价可能与房间数、占地面积之间存在某种线性关系,即可以建模为:
其中,price为房价,w表示权重,X_rooms和X_areas表示房间数和占地面积,b表示偏置。
3. 线性回归模型的矩阵表达
实际上,对于线性回归模型,往往需要多个数据样本,即n组【房间数、占地面积】的数据对应n组【房价】,为此我们可以
- 将自变量表示为矩阵X,其行数 = 样本数,列数 = 特征数,
- 将因变量表示为1维列向量Y,其行数 = 样本数,
- 将权重表示为一维横向量W,其列数 = 特征数,
- 将偏置表示为1维列向量b, 其行数 = 样本数,即:

4. 损失函数
在实际中,真实数据 和模型输出结果
存在一定的偏差,我们往往可以用损失函数来衡量预测结果和真实结果之间的偏离程度。在回归模型中,一般用均方误差作为损失函数,其定义如下:
此外,往往可以通过求平均的方式来衡量总体误差,即
5. 随机梯度下降
实际上,线性回归模型可以说是机器/深度学习领域中最为简单的一个模型,有理论证明其存在解析解,但是现实中的绝大部分问题并不存在解析解,因此更为常用的求解方法是通过优化算法近似得到数值解,其中,梯度下降就是在机器学习/深度学习领域中应用最为广泛的优化算法。
具体而言,梯度下降就是按照“梯度下降”的方向更新权重w和偏置b, 使得算法能够尽量快速的收敛,在线性回归模型中,其表达如下:
其中 为学习率,B为样本的抽样数。
6. 从线性回归到单层神经网络
实际上,上述线性回归模型可以用一个单层神经网络来表述,如下图:
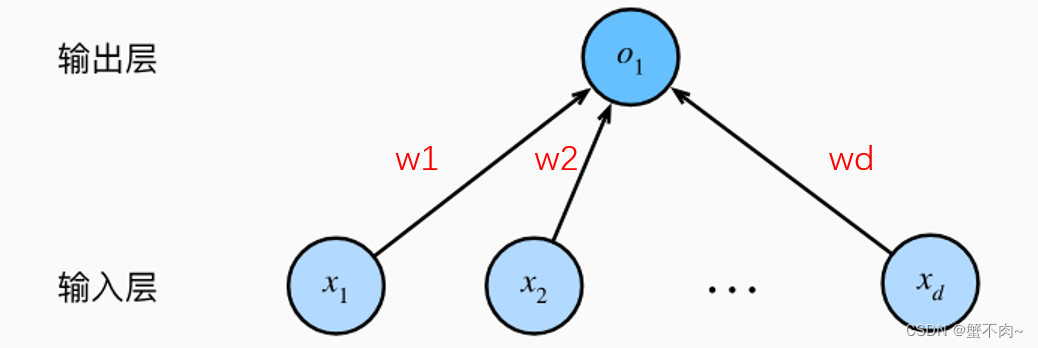
即将输入样本的d维特征,通过不同的权重 w 加权连接到输出端(这里为简单起见,忽略了偏置b)。















 532
532











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









