






本文思路:对于推荐系统,往往一个地方有用户评论,以及图片信息,还会有视频信息,涉及多种形式的视觉,声学和文本信息,这个时候融合多个模型的特征进行推荐。同时,多任务学习(MTL)模型也可以关注。
最直接的就是对多模态抽取特征,然后多模态融合,参加到推荐系统中。
-
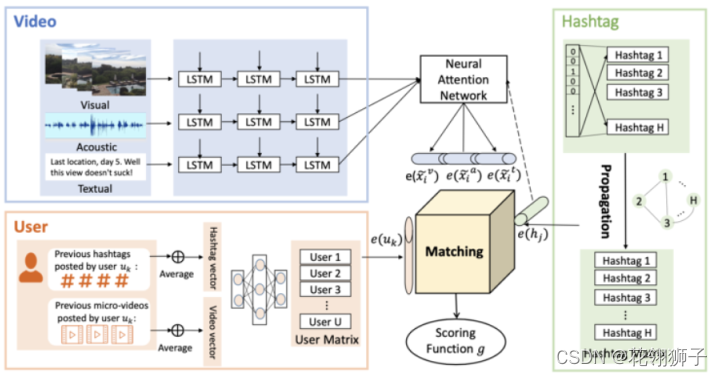
论文:Hashtag Our Stories: Hashtag Recommendation for Micro-Videos via Harnessing Multiple Modalities
-
地址:https://www.sciencedirect.com/science/article/abs/pii/S0950705120303798
-
代码:https://tagrec.wixsite.com/logo
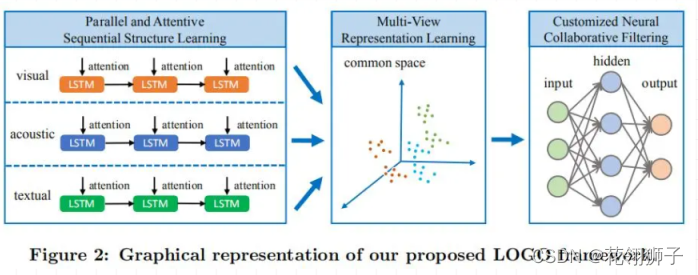
分为三个步骤:
1.抽取特征:对视觉,声音,文本三个模态都用LSTM+attention进行模态抽取。
2.共同空间投影:投影到同一空间之后以弥合不同模态之间的表达图。
3.NCF推荐:直接使用NCF推荐。
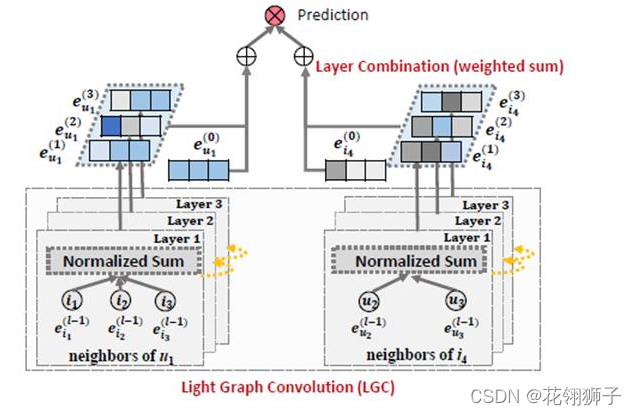
思路:在lightgcn中,一般在GCN应用的场景中每个节点会带有很多的其他属性,lightgcn中只是对项目和用户的 最终表示进行内积,得到预测。可以考虑在最下面层卷积的时候添加一个新的三层用来进行多模态特征提取,得到同样的嵌入,然后对三个嵌入进行一个加权和进行预测。
class LOGO(nn.Module):
def __init__(self, img_in, img_h, au_in, au_h, text_in, text_h, common_size):
super(LOGO, self).__init__()
self.ilstm = ImageLSTM(img_in, img_h)
self.alstm = AudioLSTM(au_in, au_h)
self.tlstm = TextLSTM(text_in, text_h)
# map into the common space
self.ilinear = MLP(img_h, common_size)
self.alinear = MLP(au_h, common_size)
self.tlinear = MLP(text_h, common_size)
def forward(self, image, audio, text):
# lstm + attention
h_i = self.ilstm(image) # batch*img_h
h_a = self.alstm(audio) # batch*au_h
h_t = self.tlstm(text) # batch*text_h
# map into the common space
x_i = self.ilinear(h_i) # batch*common_size
x_a = self.alinear(h_a) # batch*common_size
x_t = self.tlinear(h_t) # batch*common_size
# return three kind of features
return x_i, x_a, x_t---------------------------------------------------------------------------------------------
DMRL(博士论文中第一节)
针对POI推荐模型中存在数据稀疏,冷启动等问题,提出DMRL模型。这个模型针对用户行为的时空特点,建立了一个与时间相关的一个用户偏好模型,能够更好的捕捉用户行为。 并且为了缓解数据稀疏问题,该模型引入了 POI 的语义信息,并使用 BPR 框架来学习隐式交互。

DMRL构建了时间依赖的用户偏好向量挖掘用户偏好的时间动态性,以正则化项方式引入了兴趣点空间距离信息,构建了时空依赖的用户偏好模型;DMRL构建了深度多模特征提取模型,从兴趣点的视觉图片和群体评论中挖掘兴趣点的内容语义特征,建立了联合学习策略对用户偏好模型和内容特征提取模型进行监督性的学习。为了加速模型的收敛速度,还提出了基于排序的动态采样策略。在foursquare和gowalla上进行实验测评,本文提出的方法在冷启动推荐上优于传统的方法的效果。
本章设计了一个DMRL模型对个性化排序中的内在逻辑关系进行建模。该模型是一 个将兴趣点的多模态内容信息融合到贝叶斯个性化排序学习框架的概率生成模型 。具体来说,DMRL模型首先创建了一个时间依赖的用户偏好模型,利用空间特征化技术解决用户偏好的空间约束问题,使得DMRL模型可以同时挖掘用户行为的时间动态性和空间依赖性。其次,建立了一个深度多模网络,挖掘兴趣点的文本内容特征和视觉特征,以正则化项方式融合到BPR模型框架。由于BPR模型框架可以充分利用观测到的和未观测到的行为数据学习用户与兴趣点的交互关系,因此,深度多模网络模型与BPR框架的融合可以有效的搭建兴趣点的内容信息和隐式反馈之间的桥梁 ,使得我们的模型可以以推荐任务驱动的有监督学习方式提取不同模态数据的语义特征表示。此外,为了加速模型的训练和参数学习,本章设计了基于排序的自适应釆样策略,可极大的加速模型的训练和参数收敛速度
本文的目的是给为用户推荐经过排序的空间兴趣点列表,因此,将研究的问题定义为:对于给定的任意用户签到元组x=(u,t,v)形成一个查询q,目标是从兴趣点集合v中寻找满足查询条件q的topN个兴趣点推荐给目标用户。

融合地理空间信息到简单的用户偏好模型函数中,得到用户拼啊好的模式表达式为:

其中η∈[0,1]为参数权重,用于平衡与目标兴趣点Vj在地理空间上相近的兴趣点对用户偏好的影响程度。η越大,认为空间影响程度越大。为了避免过拟合,p和q都小于C(事先约定超参数)。公式第一项衡量了用户对兴趣点在交互行为上的偏好,第二项衡量了地理空间对用户偏好的影响,在模型中起到正则化作用。
对于多模态信息,该模型分别用LST,自编码和VGC16(预训练的卷积神经网络)得到对应的表示,然后勇敢多模融合从而得到地点多模态的语义信息。多模融合就是分别对文本和图像的表示通过一个线形层,然后将两者拼接起来,再通过一个线性层进行融合。

最后该工作使用了一种基于排序的动态抽样策略,以加快收敛速度,并在模型优化过程中提高模型精度。
数据集
为了验证模型的有效性,本小节利用两个公开的数据集:Foursquare和Yelp进行实验研究。这两个数据集包含了大量的用户签到行为数据,并在较多的研究工作中被采用。
foursquare:有很多来自foursquare上的数据集,本小节米用文献[44]中提供的数据集进行实验分析。该数据集包含了从2012-04-12到2013-02-16期间,美国纽约市的签到行为数据,共包含了1083个用户对3833个兴趣点,共计227428条用户签到行为数据。每个签到记录均包含用户ID、兴趣点ID、兴趣点的经纬度。由于该数据集并不包含用户的评论数据和兴趣点的图片数据,因此,本文利用foursquare提供的API接口通过网络爬虫进行抓取。整个数据集的稀疏度为99.45%。
yelp:本章采用Yelp竞赛的数据集进行实验分析,该数据集包含1300000个用户,1200000个兴趣点,涵盖了4个国家11个城市。每个签到记录均包含用户ID、兴趣点ID、兴趣点的经纬度、兴趣点的评论信息和图片信息、用户的签到行为数据。本章仅利用LasVegas的数据作为实验数据,通过过滤掉少于20个评论的用户,共得到8439个用户、20605个兴趣点、39329条评论数据。该数据集的稀疏度为99.77%。
本章首先对用户的评论文本内容信息进行处理,主要包括移除停用词、数字、标点符号,还移除字符长度小于2个的单词,因为这些单词并不能表达任何有意义的内容,然后利用Porterste_er从剩余的单词中一处后缀。本文剔除少于10个单词的评论,因为这些评论无法充分表达对兴趣点的语义表示。对于图片数据,从每个兴趣点的诸多图片中筛选一张作为兴趣点的视觉数据,并将图片压缩到3x224x224的尺寸。
实验结果:

-------------------------------------------------------------------------------
多模态的几种融合方法:
目前多模态融合主要有三种融合方式:前端融合(数据水平融合),后端融合(决策水平融合),中间融合。
前端融合将多个独立的数据集融合成一个单一的特征向量,然后输入到机器学习分类器中。由于多模态数据的前端融合往往无法充分利用多个模态数据间的互补性,且前端融合的原始数据通常包含大量的冗余信息。因此,多模态前端融合方法常常与特征提取方法相结合以剔除冗余信息,如主成分分析(PCA)、最大相关最小冗余算法(mRMR)、自动解码器(Autoencoders)等。
后端融合则是将不同模态数据分别训练好的分类器输出打分(决策)进行融合。这样做的好处是,融合模型的错误来自不同的分类器,而来自不同分类器的错误往往互不相关、互不影响,不会造成错误的进一步累加。常见的后端融合方式包括最大值融合(max-fusion)、平均值融合(averaged-fusion)、 贝叶斯规则融合(Bayes’rule based)以及集成学习(ensemble learning)等。其中集成学习作为后端融合方式的典型代表,被广泛应用于通信、计算机识别、语音识别等研究领域。
中间融合是指将不同的模态数据先转化为高维特征表达,再于模型的中间层进行融合。以神经网络为例,中间融合首先利用神经网络将原始数据转化成高维 特征表达,然后获取不同模态数据在高维空间上的共性。中间融合方法的一大优势是可以灵活的选择融合的位置
----------------------------------------------------------------------------------------------
Click-Through Rate Prediction with Multi-Modal Hypergraphs
提出了基于超图的多模态推荐框架hyperCTR:
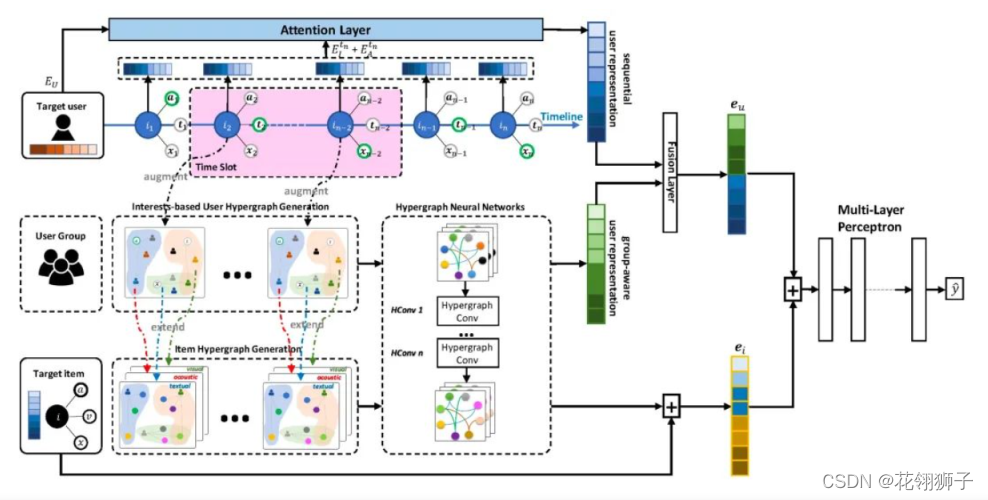
模型主要由四部分组成: 基于时序的用户行为注意力模块,基于兴趣的用户超图生成模块,商品超图构造模块以及预测模块。
基于时序的用户行为注意力模块旨在根据用户的物品交互序列,通过用户、物品和多模态类别的表示,结合 Transformer 的自注意力机制来学习交互序列内部的关系。
基于兴趣的用户超图生成模块,商品超图构造模块是分别根据用户行为以及物品的多模态联系,构建出对应的超图,再在这些超图上使用 HGCN 来学习用户和物品的表征。 最后再将基于时序的用户行为表示和基于超图的用户表示进行融合,最终通过MLP层得到最终的 CTR 预测值。


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









