











基于HttpRunner接口自动化开源框架二次开发,下阶段更新UI自动化平台前端页面
Ui自动化应具备哪些功能呢?
Po模式,全称PageObject(页面对象);UI自动化PO模式应把一个页面分为三层,对象库层、操作层、业务层。(这里只实现操作层)业务层可在debugtalk中拓展
- 收集每个test运行日志
- 页面报错截图
- WebDriver、BasePage可全局调用
- BrowserDriver配置
- 继承HttpRunner所有特性
- 先实现以上几个功能,有需求后面再继续扩展
重新封装runner. _run_test方法
def _run_test(self, test_dict):
""" run single teststep.
Args:
test_dict (dict): teststep info
{
"name": "teststep description",
"skip": "skip this test unconditionally",
"times": 3,
"variables": [], # optional, override
"page": {
"url": "http://baidu.com",
"step":[{"by":'',"locator":'',"fun_name":'',"locator_desc":'':,"kwargs":{}}]
},
"extract": {}, # optional
"validate": [], # optional
"setup_hooks": [], # optional
"teardown_hooks": [] # optional
}
Raises:
exceptions.ParamsError
exceptions.ValidationFailure
exceptions.ExtractFailure
"""
# check skip
self._handle_skip_feature(test_dict)
# prepare
test_dict = utils.lower_test_dict_keys(test_dict)
test_variables = test_dict.get("variables", {})
self.session_context.init_test_variables(test_variables)
# teststep name
self.meta_datas = {"log": "", "err_shot": "", "at_time": 0} # Collect test logs
test_name = self.session_context.eval_content(test_dict.get("name", ""))
_log = f"====== Start the test, the use case is {test_name} ======\n"
logger.log_info(_log)
self.meta_datas["log"] += _log
# parse test page
raw_page = test_dict.get('page', {})
parsed_test_page = self.session_context.eval_content(raw_page)
self.session_context.update_test_variables("page", parsed_test_page)
self.session_context.update_test_variables("driver", self.driver)
# prepend url with base_url unless it's already an absolute URL
url = parsed_test_page.pop('url')
base_url = self.session_context.eval_content(test_dict.get("base_url", ""))
parsed_url = utils.build_url(base_url, url)
# setup hooks
setup_hooks = test_dict.get("setup_hooks", [])
if setup_hooks:
self.do_hook_actions(setup_hooks, "setup")
try:
step = parsed_test_page.pop('step')
parsed_test_page.setdefault("verify", self.verify)
# group_name = parsed_test_request.pop("group", None)
except KeyError:
raise exceptions.ParamsError("URL or Step missed!")
# page
valid_bys = ["XPATH", "ID", "LINK_TEXT", "PARTIAL_LINK_TEXT", "NAME", "TAG_NAME", "CLASS_NAME", "CSS_SELECTOR"]
index = 1 # Number of steps
eo = BasePage(self.driver)
logger.log_info('Open page,Url:%s' % parsed_url)
self.driver.get(parsed_url)
start_at = eo.get_time # start_at
for item in step:
_log = '====== execution step, id:%s ====== \n' % index
logger.log_info(_log)
self.meta_datas["log"] += _log
if item["by"].upper() not in valid_bys:
err_msg = u"by locator strategies! => {}\n".format(item["by"])
err_msg += "Available of supported locator strategies: {}".format("/".join(valid_bys))
self.meta_datas["log"] += err_msg
logger.log_error(err_msg)
raise exceptions.ParamsError(err_msg)
try:
eo.sys_method__run(item["by"].upper(), item["locator"], item["fun_name"],
item["locator_desc"], item["kwargs"])
self.meta_datas[
"log"] += f"Step details,{item['fun_name']} the operation,operation elements are {item['locator']}\n"
except (TimeoutException, NoSuchElementException, InvalidSelectorException) as err:
err_msg = f'{item["locator"]}The element search failed, the current page name is being intercepted\n'
self.meta_datas["log"] += err_msg
logger.log_error(err_msg)
self.meta_datas["err_shot"] = eo.screen_shot() # Screenshot page
raise err
finally:
index += 1
# teardown hooks
teardown_hooks = test_dict.get("teardown_hooks", [])
if teardown_hooks:
self.session_context.update_test_variables("driver", self.driver)
self.do_hook_actions(teardown_hooks, "teardown")
# extract
extractors = test_dict.get("extract", {})
self.session_context.update_session_variables(extractors)
# validate
validators = test_dict.get("validate") or test_dict.get("validators") or []
validate_script = test_dict.get("validate_script", [])
if validate_script:
validators.append({
"type": "python_script",
"script": validate_script
})
validator = Validator(self.session_context, None)
try:
validator.validate(validators)
except (exceptions.ParamsError,
exceptions.ValidationFailure, exceptions.ExtractFailure):
err_msg = "{} DETAILED PAGE & Validator {}\n".format("*" * 32, "*" * 32)
err_msg += "url: {}\n".format(parsed_url)
for k, v in parsed_test_page.items():
v = utils.omit_long_data(v)
err_msg += "{}: {}\n".format(k, repr(v))
err_msg += "\n"
logger.log_error(err_msg)
self.meta_datas["log"] += err_msg
raise
finally:
# get page and validate results
end_mes = f"====== End of test, use case time {eo.get_time - start_at} s ======\n"
logger.log_info(end_mes)
self.meta_datas["log"] += end_mes
self.meta_datas["at_time"] = eo.get_time - start_at
self.meta_datas["validators"] = validator.validation_results
新增Object文件
class BasePage(object):
"""公共方法"""
def __init__(self, driver: Chrome):
self.driver = driver
def wait_presence_elem(self, locator, locator_desc=None, timeout=5, frequency=0.2):
"""
等待元素存在,显示等待
:param locator: 元素位置
:param locator_desc: 元素描述
:param timeout: 默认等待时间
:param frequency: 默认间隔时间
:return:
"""
# 开始时间
t1 = self.get_time
wait = WebDriverWait(self.driver, timeout, poll_frequency=frequency)
e = wait.until(EC.presence_of_element_located(locator))
t2 = self.get_time
logger.log_info("{} The element waits for the end, the waiting time is {}".format(locator_desc, (t2 - t1)))
return e
def wait_visible_elem(self, locator, locator_desc=None, timeout=20, frequency=0.2, ):
"""等待元素出现(可见),显示等待"""
# 开始时间
t1 = self.get_time
wait = WebDriverWait(self.driver, timeout, poll_frequency=frequency)
e = wait.until(EC.visibility_of_element_located(locator))
t2 = self.get_time
logger.log_info("{} The element waits for the end, the waiting time is {}".format(locator_desc, t2 - t1))
return e
def find_element(self, locator):
"""
:param locator: 元素定位。以元组的形式。(定位类型、值)
:return: WebElement对象。
"""
logger.log_info("Find element {} ".format(locator))
elem = self.driver.find_element(*locator)
return elem
def screen_shot(self):
"""截图"""
# shot_name = 时间戳字符串 + 后缀名 .png
shot_name = datetime.now().strftime("%Y-%m-%d-%H-%M-%S") + '.png'
shot_file = os.path.join(BASE_DIR, 'media/file/' + shot_name)
try:
self.driver.save_screenshot(shot_file)
logger.log_info("The current page has been intercepted, the file path {}".format(shot_file))
except:
logger.log_error("Failed to take screenshot of WebPage!")
return shot_name
def wait_click_elem(self, locator, timeout=0.5, frequency=0.2):
"""等待元素可被点击"""
wait = WebDriverWait(self.driver, timeout, poll_frequency=frequency)
e = wait.until(EC.element_to_be_clickable(locator))
return e
def my_quit(self):
"""关闭浏览器"""
self.driver.quit()
logger.log_info('Step details, close the browser')
def click(self, locator, locator_desc=None):
"""点击元素"""
self.wait_presence_elem(locator, locator_desc).click()
logger.log_info('Step details, By:%s, Click element:%s' % (locator[0], locator[1]))
def send_key(self, locator, value, locator_desc=None):
"""输入内容"""
self.wait_presence_elem(locator, locator_desc).send_keys(value)
logger.log_info('Step details, By:%s, element:%s, input content:%s' % (locator[0], locator[1], value))
self.my_sleep(0.5)
def get_text(self, locator, locator_desc=None):
"""获取文本"""
_text = self.wait_presence_elem(locator, locator_desc).text
logger.log_info('Step details, By:%s, element:%s, Get text:%s' % (locator[0], locator[1], _text))
self.my_sleep(0.5)
return _text
@staticmethod
def my_sleep(times):
"""强制等待"""
time.sleep(times)
logger.log_info(f'Step details, pause for {times}second')
..... 该文件封装web常用操作,自行百度
def sys_method__run(self, by, locator, fun_name, locator_desc=None, kwargs=None):
_tu_locator = (getattr(By, by), locator)
fun = getattr(self, fun_name, None)
if locator:
if not isinstance(kwargs, dict) or not kwargs:
kwargs = dict()
kwargs.update({"locator": _tu_locator})
kwargs.update({"locator_desc": locator_desc})
try:
return fun(**kwargs)
except TypeError as err:
raise err
启动web浏览器文件
class Browser:
def __init__(self, name):
self.name = name
def start_browser(self):
"""firefox"、"chrome"、"ie"、"phantomjs"""
try:
if self.name == "firefox" or self.name == "Firefox" or self.name == "ff":
logger.log_info("start browser name :Firefox")
driver = webdriver.Firefox()
return driver
elif self.name == "chrome" or self.name == "Chrome":
logger.log_info("start browser name :Chrome")
driver = webdriver.Chrome()
return driver
elif self.name == "ie" or self.name == "Ie":
logger.log_info("start browser name :Ie")
driver = webdriver.Ie()
return driver
elif self.name == "phantomjs" or self.name == "Phantomjs":
logger.log_info("start browser name :phantomjs")
driver = webdriver.PhantomJS()
return driver
else:
logger.log_error("Not found this browser,You can use 'firefox', 'chrome', 'ie' or 'phantomjs'")
except Exception as msg:
logger.log_error("An exception occurs when starting the browser \n%s" % str(msg))
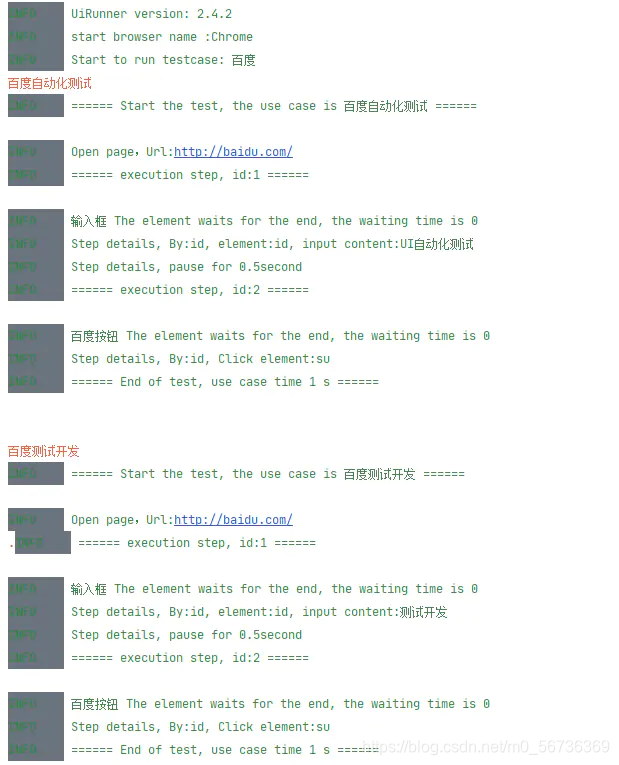
ok、本地启动测试一下

这些资料,对于【软件测试】的朋友来说应该是最全面最完整的备战仓库,这个仓库也陪伴我走过了最艰难的路程,希望也能帮助到你
关注我的微信公众号【伤心的辣条】免费获取~
送上一句话:
世界的模样取决于你凝视它的目光,自己的价值取决于你的追求和心态,一切美好的愿望,不在等待中拥有,而是在奋斗中争取。
我的学习交流群:902061117 群里有技术大牛一起交流分享~
如果我的博客对你有帮助、如果你喜欢我的博客内容,请 “点赞” “评论” “收藏” 一键三连哦!














 2396
2396











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









