






 文章讲述了在使用BorutaPy进行特征选择时,遇到因numpy版本升级导致的AttributeError。提供了解决方案,包括降级numpy版本或直接修改boruta_py.py源码中的类型替换,提醒读者修改后需重启内核。
文章讲述了在使用BorutaPy进行特征选择时,遇到因numpy版本升级导致的AttributeError。提供了解决方案,包括降级numpy版本或直接修改boruta_py.py源码中的类型替换,提醒读者修改后需重启内核。
1代码:
#导包
from boruta import BorutaPy
# estimator表示已创建的模型对象
# n_estimators=800,random_state=66,max_iter=10 可调参数
feature_select = Borutapy(estimator,n_estimators=800,random_state=66,max_iter=10)
# 进行特征选择
feature_select.fit(x,y) # x是数据的特征 ,y是目标值
2报错:
AttributeError: module 'numpy' has no attribute 'int'.
`np.int` was a deprecated alias for the builtin `int`. To avoid this error in existing code, use `int` by itself. Doing this will not modify any behavior and is safe. When replacing `np.int`, you may wish to use e.g. `np.int64` or `np.int32` to specify the precision. If you wish to review your current use, check the release note link for additional information.
The aliases was originally deprecated in NumPy 1.20; for more details and guidance see the original release note at:
https://numpy.org/devdocs/release/1.20.0-notes.html#deprecations
3原因
如果numpy 的版本在1.20以上, 会报错。
查看numpy的版本号:
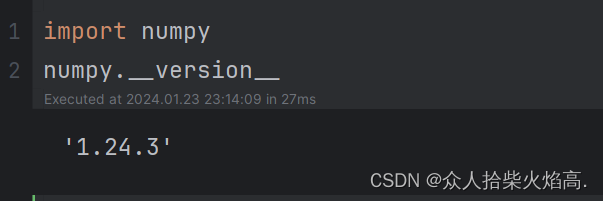
4解决方法
方法1:
把numpy的版本更换为1.20以下
方法2:
可以直接修改boruta.py的源码。
在目录 anaconda3 \Lib\site-packages\boruta中找到 boruta_py.py文件,进行修改。
修改前:np.int → 修改后:np.int64
修改前:np.float → 修改后:np.float64
修改前:np.bool → 修改后:np.bool_
具体如下:
修改之前
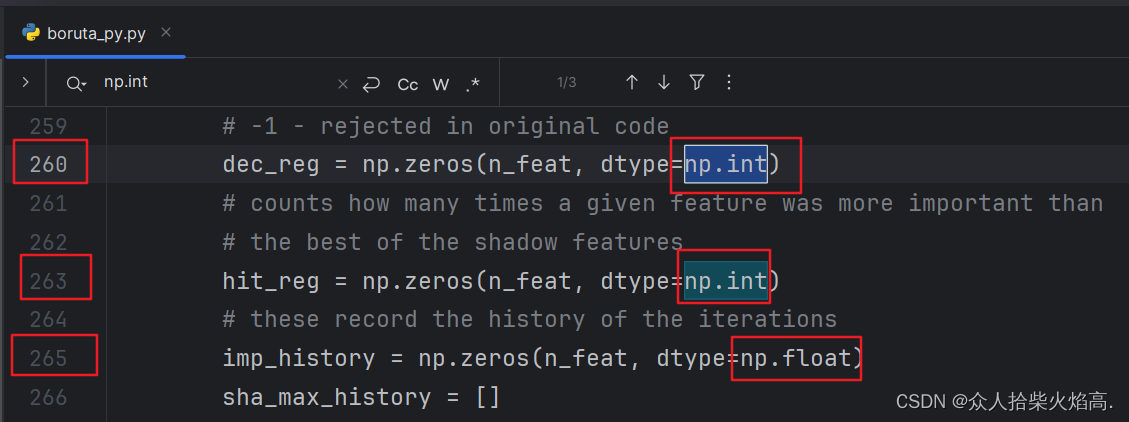
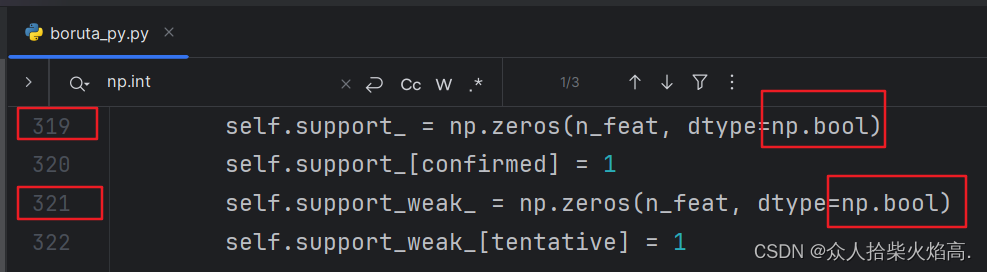
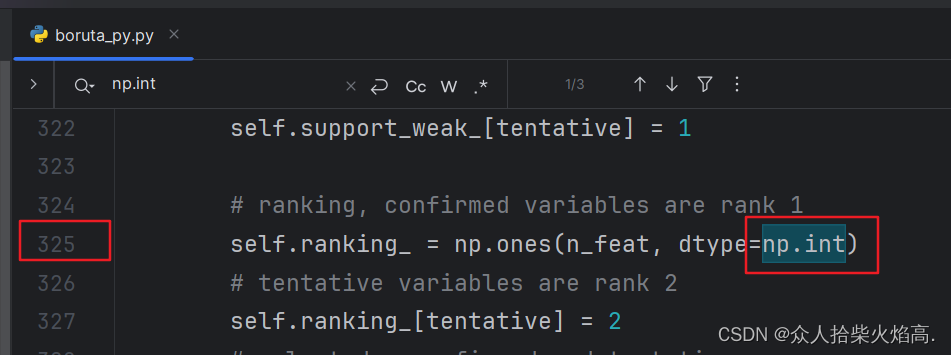
修改之后
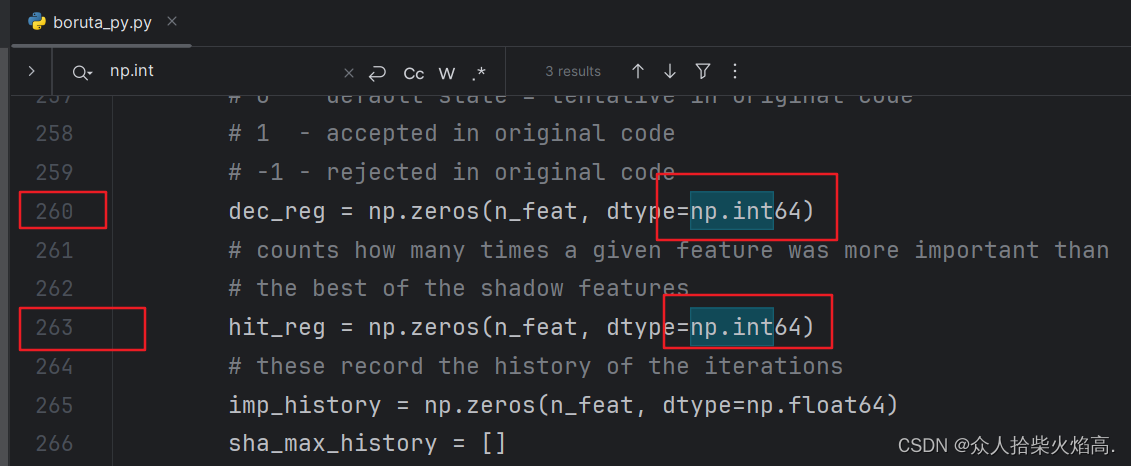
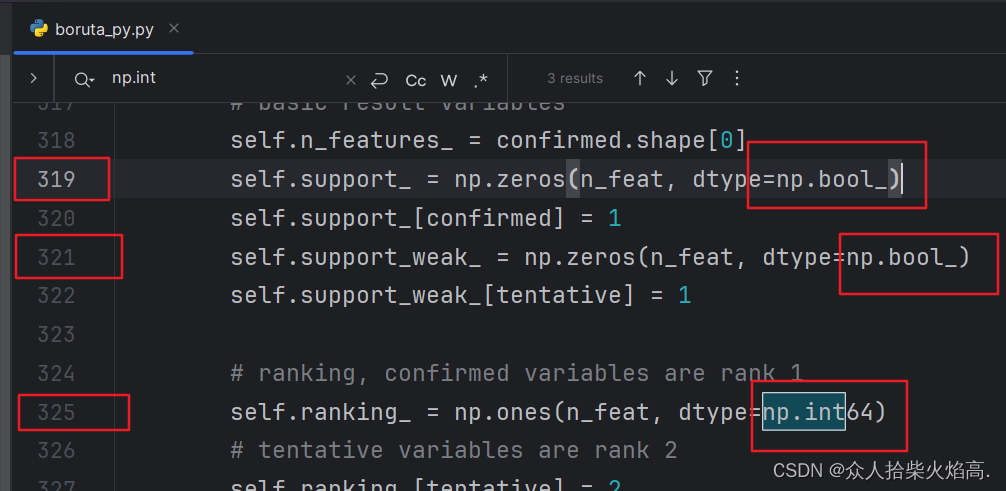
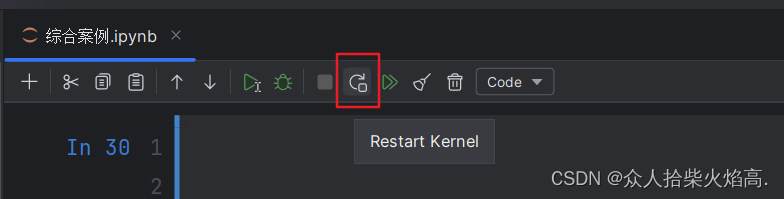
注意:
修改之后需要重启内核!

















 2864
2864

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









