







 本文深入探讨了搜索算法,包括无信息搜索的深度优先、广度优先、一致代价等策略,以及有信息搜索的贪心和A*搜索。分析了算法的完备性、最优性、时间与空间复杂度,强调了目标检测时机的重要性。
本文深入探讨了搜索算法,包括无信息搜索的深度优先、广度优先、一致代价等策略,以及有信息搜索的贪心和A*搜索。分析了算法的完备性、最优性、时间与空间复杂度,强调了目标检测时机的重要性。
一、问题形式和搜索框架
(一)、问题的组成部分
搜索问题包含五个基本组成部分:初始状态、可能行动、转移模型、目标测试、路径消耗。
(二)、基本搜索框架
搜索问题包含两个基本的搜索框架,即树搜索和图搜索。
树搜索伪代码:

边界是用于存放当前所有待扩展的叶结点的集合。REMOVE-FRONT为以某种策略从边界
中选择叶结点进行扩展(扩展的意思是访问到当前结点并将其后继结点加入边界),扩展操作用EXPAND函数实现。不同的搜索算法不同之处在于:从边界选择结点的策略不同。特别注意:目标检测GOAL-TEST判断需要根据算法的不同决定是在扩展时进行,而是在选择后进行(在所有算法介绍完后我们会比较这一点)。
图搜索伪代码:

集合用于存放当前已被扩展过的结点。
两个搜索算法最主要的区别是:树搜索允许对某一结点重复扩展,而图搜索在树搜索上进行改进,不会对结点进行重复扩展,即在扩展结点前判断该结点是否已被访问过。
(三)、算法的性能
完备性:当问题有解时,算法是否能保证找到解。
最优性:算法是否能找到最优解。
时间复杂度:找到解花费的时间。
空间复杂度:算法需要的内存。
复杂度通常由以下三个量来表达:——分支因子:任何结点的最多后继数;
——目标结点所在的最浅深度;
——状态空间中路径的最大长度(可能是无穷),即树的最大深度。
(以下我们讨论完备性和最优性时,没有特别说明这是在图搜索算法还是树搜索算法中时,就是都满足。)
二、无信息搜索(Uninformed Search)
无信息搜索(也称盲目搜索)策略,是指除了问题定义中提供的状态信息外没有任何附加信息,该类算法要做的是生成后继结点并判断是否是目标状态。
(一)、深度优先搜索(Depth-First Search)
深度优先搜索总是扩展搜索树的当前边界结点中最深的结点。并且一个节省内存的做法是:已被探索并且在边界中没有后代的结点可以从内存中删除。
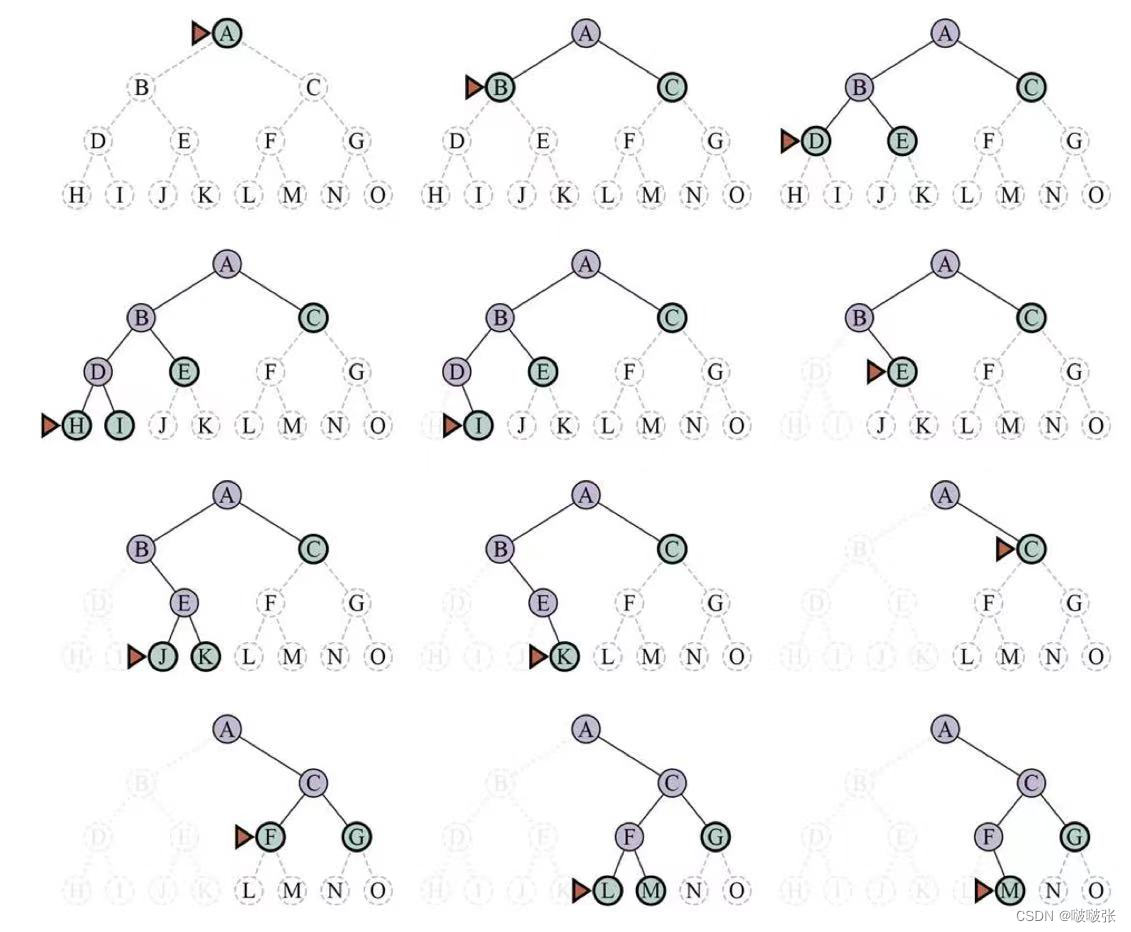
完备性:DFS在树搜索算法框架下是不完备的。这是因为如果当前搜索空间状态图中存在回路,那么DFS将会陷入无限循环,永远无法找到解。但是如果在图搜索算法框架下
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章
















 4885
4885











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









