










本文代码:https://github.com/kaiwang960112/Self-Cure-Network
本文贡献:
- 创新性地提出了人脸表情识别中的不确定性问题,并提出了一种自修复网络来减少不确定性的影响。
- 精心设计了一个秩正则化来监督SCN学习有意义的重要权值,也为重标记模块提供了参考。
- 在合成的FER数据和一个从互联网上收集的新的真实世界不确定情绪数据集(WebEmotion)上广泛验证了我们的SCN。SCN在RAF-DB上的性能也达到了88.14%,在AffectNet上达到了60.23%,在FERPlus上达到了89.35%,这些都创下了新的记录。
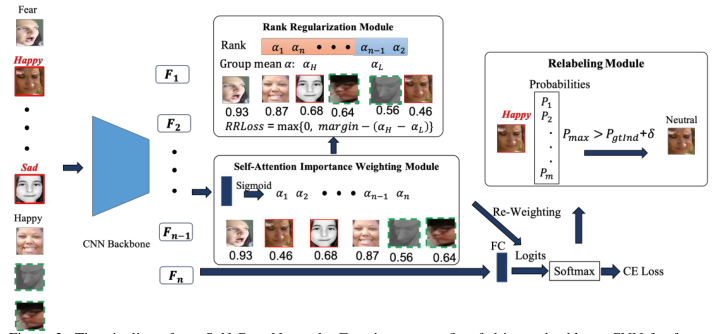
图1 本文总体框架
SCN建立在传统CNN的基础上,由三个关键模块组成:i)自我注意重要性加权,ii)排名正则化,iii)重标签。
人脸图像首先被输入主干CNN进行特征提取。自注意重要性加权模块从面部特征中学习样本权重,进行损失加权。秩正则化模块将样本权值作为输入,通过排序操作和基于边际的损失函数对其进行约束。重新标记模块通过比较最大预测概率和给定标签的概率来寻找可靠的样本。错误标记的样品用红色实心矩形标出,模糊的样品用绿色虚线标出。值得注意的是,SCN主要通过重加权操作来抑制这些不确定性,只对部分不确定样本进行修正。
在给定一批样本不确定的人脸图像的基础上,首先利用主干网络提取人脸的深度特征。自我注意重要性权重模块使用完全连接(FC)层和sigmoid函数为每个图像分配重要性权重。这些权重乘以样本重加权方案的Logit。为了显式降低不确定样本的重要性,进一步引入秩正则化模块对注意权重进行正则化。在秩正则化模块中,首先对学习到的注意权重进行排序,然后将其分为高重要性组和低重要性组。然后,通过基于边际的损失在这些组的平均权重之间添加一个约束,这被称为秩正则化损失(RR-Loss)。为了进一步改进SCN,增加了重标记模块来修改低重要性组中的一些不确定样本。重新贴标签的目的是寻找更多干净的样品,然后提高最终的模型。整个SCN可以以端到端方式训练,并可以轻松地添加到任何CNN主干中。
Self-Attention Importance Weighting:
引入了自我注意重要性加权模块来获取样本对训练的贡献。预计某些样本可能具有较高的重要性权重,而不确定样本的重要性较低。设表示N幅图像的面部特征,自我注意重要性加权模块以F为输入,输出每个特征的重要性权重。具体而言,自我注意重要性加权模块由线性全连接(FC)层和sigmoid激活函数组成,其可表示为:
,其中
是第i个样本的重要权重,
是用于注意的FC层的参数,σ是sigmoid函数。本模块还为其他两个模块提供参考。
Logit-Weighted(加权)交叉熵损失。根据注意权重,我们有两个简单的选择来执行损失权重,这是受到[19]的启发。第一种选择是用每个样品的重量乘以样品损失。在我们的例子中,由于权值是以端到端方式优化的,并且是从CNN特征中学习到的,它们注定是零,因为这个琐碎的解决方案造成了零损失。MentorNet[22]等自定节奏学习方法[213,32]通过交替最小化来解决这个问题,即一次优化一个,另一个保持不变。在本文中,我们选择了[19]的对数加权函数,它被证明是更有效的。对于多类交叉熵损失,我们将加权损失称为Logit-Weighted Cross-Entropy loss (WCE-Loss),其表达式为:,(2)其中
是第j个分类器,从[30]中可以看出,
与α呈正相关。
Rank Regularization:
上述模块中的自我注意权重在(0,1)中可以是任意的。为了明确约束不确定样本的重要性,精心设计了一个排序正则化模块来正则化注意权重。在排序正则化模块中,首先将学习到的注意权重按降序排序,然后将它们按比例β分成两组。排序正则化保证了高重要性群体的平均注意权重高于低重要性群体的平均注意权重。为此,正式定义了秩正则化损失(RR损失),如下所示:,其中
,
,其中
是一个边界,可以是一个固定的超参数或一个可学习的参数,
和
分别是具有β∗N = M样本的高重要性组和具有N−M样本的低重要性组的平均值。训练时,总损失函数为
,其中γ是一个权衡比。
Relabeling:
在排序正则化模块中,每个小批被分为高重要性组和低重要性组。通过实验发现,不确定样本通常具有较低的重要性权重,因此一个直观的想法是设计一个策略来重新标记这些样本。
修改这些注释的主要挑战是知道哪个注释是不正确的。
具体来说,重标记模块只考虑低重要性组中的样本,并对Softmax概率执行。对于每个样本,将最大预测概率与给定标签的概率进行比较。如果最大预测概率大于给定标签的最大预测概率,则将一个样本分配给一个新的伪标签。形式上,重新标记模块可以定义为:其中,y '为新标签,
为阈值,
为最大预测概率,
为给定标签的预测概率。
和
分别为原始给定标签和最大预测的索引。
在系统中,希望不确定的样本获得低重要性的权重,通过重加权来降低其负面影响,然后落入低重要性组,最后通过重标签来修正为特定的样本。这些校正后的样品在下一个时代可能获得重要的权重。期望通过重新加权或重新标记,网络可以自行固化,这就是称之为自固化网络的原因。















 2809
2809











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









