










目录
摘要:
在现实场景中识别面部表情的最新趋势是在局部部署基于注意的卷积神经网络(CNN),以表示面部区域的重要性,并将其与全局面部特征和/或其他补充上下文信息相结合,以提高性能。然而,在存在遮挡和姿势变化的情况下,不同通道的响应不同,并且通道的响应强度在空间位置上也不同。此外,现代面部表情识别(FER)体系结构依赖于外部来源,如landmark来定义注意力。landmark探测器的故障将对FER产生级联效应。此外,没有强调为计算补充上下文信息而输入的特征的相关性。利用上述观察结果,本文提出了一种用于FER的端到端架构,该架构通过一种新的空间通道注意网(SCAN)获得每个空间位置的每个通道的局部和全局注意,而无需从地标检测器中寻找任何信息。SCAN由补充上下文信息(CCI)分支进行补充。此外,使用有效通道注意(ECA),还关注了特征输入对CCI的相关性。所提出的结构学习到的表示对遮挡和姿势变化具有鲁棒性。在2019冠状病毒疾病模型中,在实验室和野生数据集(AFFETNET、FALPLUS、RAF-DB、FED RO、SKO、CK+、OLU-CASIA和JAFFE)上,证明了该模型的鲁棒性和优越性能,以及与掩蔽人脸相似的构造的面具数据集。代码可在以下网址公开获取:
本文主要贡献:
- 一个称为SCAN的局部-全局注意分支,通过计算所有参考的局部patch和整个输入的每个通道每个空间位置的注意权重,使FER模型对遮挡和姿势变换具有鲁棒性。还演示了local注意分支可以在所有local patch之间共享,而不会有任何显著性能下降。这使得local patch分支变得轻量级。
- 一个增强的补充上下文信息分支,称为CCI,由ECA增强,为SCAN提供更丰富的补充信息。
- FER端到端架构,不依赖于外部资源(如landmark detectors)来定义注意力。
- 在各种数据集上,无论是在实验室还是在野外的情况下,验证了所提出的架构,性能优于最近的方法。此外,在几个构建的COVID-19场景中的类似蒙面人脸的蒙面人脸数据集上,与基线和最先进的方法进行比较。
提出的模型:
动机:
提出的模型是由[30],[48],[13]中详细描述的基于注意力的FER和[43]中的关键观察所驱动的。在这些基于注意的模型中,注意块类型的一般描述如图1所示。
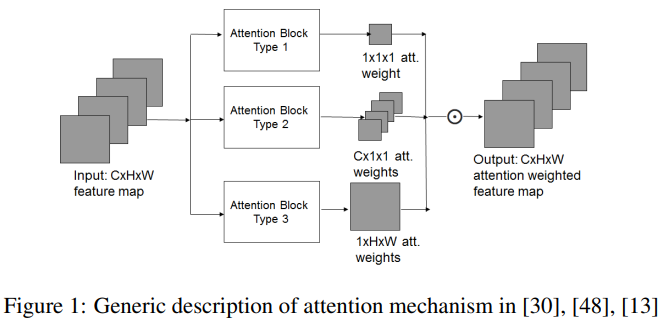
[30],[48],[13]分别采用了三种类型的注意块。从图1可以注意到,无论是在空间和通道维度上的注意权重是恒定的(类型1,[30]),还是在空间维度上的注意权重是恒定的(类型2,[48]),或在通道维度上的注意权重是恒定的(类型3,[13])。然而,它已经在[43]中说明,在存在遮挡时,不同的通道反应不同,并且进一步,对于给定的输入刺激,每个通道在空间位置上表现出不同的强度。
例如,图2显示了ResNet-50中Conv_3x块输出的干净图像与其被遮挡图像之间响应中值相对差值的8个选定通道。中值是从100对干净的和被遮挡的图像样本中计算出来的,这些图像的遮挡固定在整个样本的同一位置。显然,一些通道对遮挡显示最小的反应,而其他通道在遮挡区域周围显示不同的反应。(这一段话没看明白,没理解啥意思)

图2 通道对遮挡的响应。最左上方是被遮挡图像的一个样本。其他8幅图像显示了在100对清洁和遮挡的样本中8个通道响应的中位数相对变化热图
Spatio-Channel Attention Net(SCAN)
基于上述观察,本工作提出了一个注意块,为给定的输入特征图提供每个通道每个空间位置的注意。这个注意力块被称为空间-通道注意力网。SCAN的输入输出流水线如图3所示。在数学上,设P为SCAN的C × H × W维输入特征映射。设f为模拟SCAN的非线性函数。在本文中,f被定义为一个“相同”的卷积操作,其输出通道数与输入通道数相同,然后是参数ReLU (PReLU)激活、批处理归一化(BN)和sigmoid激活(σ)。设OP为SCAN计算的输入特征图的注意权重。
(1),其中,Conv是“相同的”卷积操作,它取一个C × H × W输入特征图,输出C × H × W注意权值。
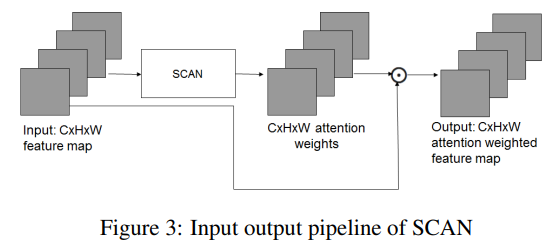
在计算注意权重之后,对输入的特征图进行加权。设WP表示加权输入特征图。然后,(2)
是按元素计算的乘法运算符。为了方便起见,假设这个元素相乘与SCAN合并。因此SCAN的输出为输入P的WP。需要注意的是,输入P可以是一个feature map的局部patch,也可以是提供全局上下文的整个feature map。因此,SCAN被称为局部-全局注意分支。
当一个特征映射中的多个patch输入到SCAN时,SCAN中的可学习参数可以在所有输入patch之间共享,或者在各个patch之间保持独立。在这项工作中,共享和独立的SCAN参数集报告了相似的性能。这将在第6节中说明。为了进一步说明,假设参数在各个patch之间是独立的。
Complementary Context Information (CCI) Branch:
SCAN在关注局部和全局相关特征的同时,额外的补充信息肯定会增强模型的辨别能力。(具体指什么补充信息)由于FER采用了来自FR的迁移学习,因此可以很容易地利用FR中丰富的信息来提取互补的上下文信息。特别是,来自FR模型中间层的特征映射信息可以用于此目的。中间层可能包含面部周围部分的特征,如眼睛、鼻子、嘴巴等,这些对FER有用。最后一层通常包含身份特定的特征,这不适用于FER。
中间层的特性可能是冗余的,并且所有的特性对FER来说可能并不重要。为了消除冗余和强调重要的特征,从中间层开始对特征映射应用ECA[49]。ECA是一种不降维的局部跨信道交互机制,它计算信道方面的注意力,在空间维度上保持不变。ECA已经表明维度减少会降低绩效,而跨渠道交互则会提高绩效。值得注意的是,SCAN中也遵循了这一理念。一个自然的问题是,为什么ECA会在这里,为什么不扫描。需要注意的是,这里的目标是获得SCAN提供的补充上下文信息。因此这里不使用SCAN。此外,在使用来自FR模型中间层的信息进行FER之前,需要强调重要的特性,消除冗余。因此,渠道方面的关注在这里就足够了。在这方面,由于ECA已表明它比其他注意方法优越,因此在这里采用它。
本文中提出的CCI分支机构与[13]中的分支机构相似,但事先由ECA强调了特征。第6.7节说明了ECA的影响。CCI分支描述如下:设F为FR训练的基本模型的选定中间层的特征映射,设OF为CCI分支的输出。然后,
(3),其中,PARTITION将ECA加权特征映射划分为k个不重叠的块,GAP为全球平均池化。
是GAP在第i块上的输出,是一个特征向量。在[13]之后,k被选为4。
整个体系架构:
完整的建议架构如图4所示。输入I是一个224 × 224的RGB图像。它由预先训练的ResNet-50模型处理。
对于SCAN分支,来自ResNet-50的Conv_3x块的输出作为输入。这是一张28 × 28 × 512的feature map,用Fu表示。然后,将Fu划分为m个不重叠的块,每个块作为一个局部patch。在这项工作中,m被选择为25,基于在第6.9节报道的消融研究。这会产生25个局部patch(16个6×6的,4个6×4的,4个4×6的,1和4×4)。来自25个局部patch的SCAN输出是跨空间维的全局平均池化,然后跨通道维的最大池化,以512维向量的形式提供局部上下文的总结,用Vl表示。此外,将整个Fu输入SCAN,并将输出进行全局平均池,以另一个512维向量(用Vg表示)的形式捕获全局上下文。Vl和Vg通过一个基于交叉熵损失的表达分类器进行连接和发送,用Lu表示。需要注意的是,通过SCAN进行的整个局部和全局上下文处理没有来自外部地标检测器的任何信息。
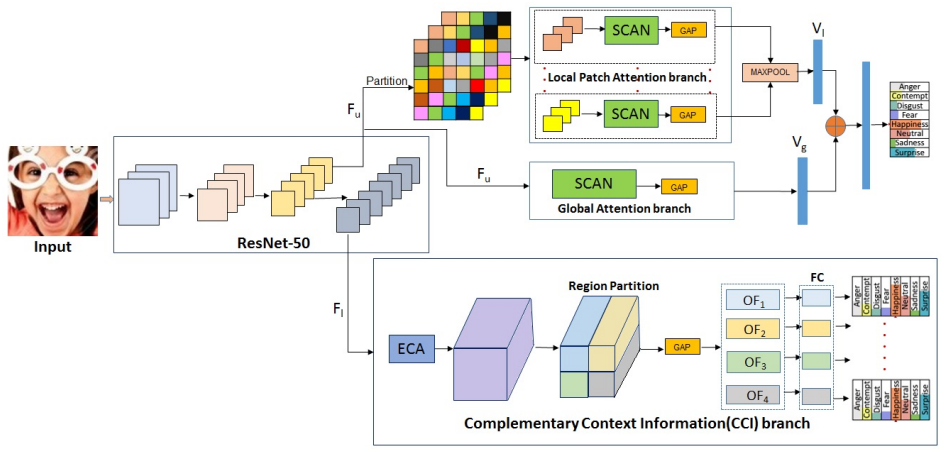
对于CCI分支,ResNet-50的Conv_4x块输出(用Fl表示)作为输入。它的维度为14×14×1024。如式3所示,CCI的输出是k个向量。然后,每个
密集连接到256个节点层,然后通过基于交叉熵损失(Li)的表达式分类器。CCI分支的总损失为
(4),两个分支的总损失为:
(5),
,在这项工作中,将
设置为0.2,基于在6.9中的消融研究。
小白疑问:
1. 为什么文章说SCAN没有用到landmark detectors,那么在局部patch那部分是怎么分为25个不重叠的patch的,依据什么进行分片的。(明白了,直接分的)
2. CCI分支说是补充上下文信息的分支,具体是什么,我理解的应该不是周围环境的这种上下文信息,因为文章说FER采用了来自FR的迁移学习,所以利用FR的丰富的信息来提取互补的上下文信息,FER的中间层的特征映射信息可以用于此目的。中间层可能包含面部周围的特征,如鼻子、眼睛、嘴巴等,这些对FER有用。是对中间层进行一个反向传播,然后主要是用来优化中间层的。
希望大佬可以给解答一下疑问,感谢!















 1万+
1万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









