






包含self-attention和卷积在内的分类架构,跟我另一篇UniNeXt: Exploring A Unified Architecture for Vision Recognition对比一下
重点在stage部分,Dynamic Position Embedding (DPE)、Multi-Head Relation Aggregator (MHRA) ,从图上看前馈网络 (FFN)没有做改变
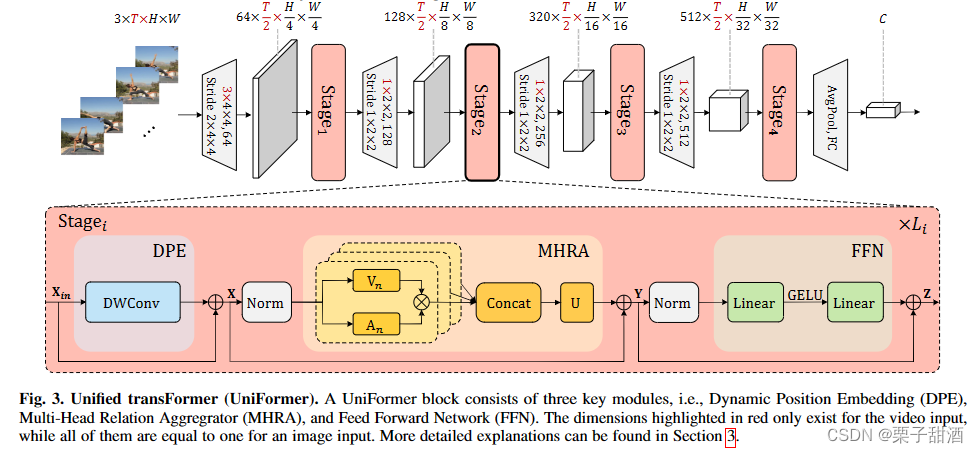
DPE动态位置聚合器,一个dw卷积,负责位置标记,利用了卷积的性质。
MHRA多头关系聚合器,传统的 CNN 和 ViT 专注于解决局部冗余或全局依赖,导致准确性不理想或/和不必要的计算。为了克服这些困难,引入了一个通用关系聚合器(RA),它优雅地统一了卷积和自注意力以进行令牌关系学习。AV和concat组成特别的自注意力机制,V跟vit的V一样是X的线性变化,U是一个可学习参数矩阵用于整合多个头。A包含了A_local和A_global,A_local中,a可学习参数,i-j相对位置,作者把这个过程类似dw卷积,X到V的线性变换是逐点卷积,AV是深度卷积,U又是一个逐点卷积。A_global跟普通多头注意力是非常类似的,只是抛弃了softmax使用了指数形式,同样可以获得相似度分数,作者觉得点积运算会破坏时空关系。
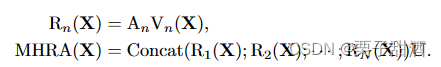
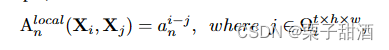
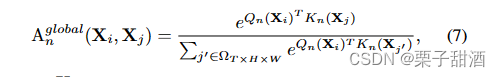
文章的核心是MHRA,我觉得很巧妙,但当我打开code,这个求A_global不是和vit一样的吗???
class Attention(nn.Module):
def __init__(self, dim, num_heads=8, qkv_bias=False, qk_scale=None, attn_drop=0., proj_drop=0.):
super().__init__()
self.num_heads = num_heads
head_dim = dim // num_heads
# NOTE scale factor was wrong in my original version, can set manually to be compat with prev weights
self.scale = qk_scale or head_dim ** -0.5
self.qkv = nn.Linear(dim, dim * 3, bias=qkv_bias)
self.attn_drop = nn.Dropout(attn_drop)
self.proj = nn.Linear(dim, dim)
self.proj_drop = nn.Dropout(proj_drop)
def forward(self, x):
B, N, C = x.shape
qkv = self.qkv(x).reshape(B, N, 3, self.num_heads, C // self.num_heads).permute(2, 0, 3, 1, 4)
q, k, v = qkv[0], qkv[1], qkv[2] # make torchscript happy (cannot use tensor as tuple)
attn = (q @ k.transpose(-2, -1)) * self.scale
attn = attn.softmax(dim=-1)
attn = self.attn_drop(attn)
x = (attn @ v).transpose(1, 2).reshape(B, N, C)
x = self.proj(x)
x = self.proj_drop(x)
return x














 2876
2876











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









