






Abstract
由于视频帧之间存在较大的局部冗余和复杂的全局依赖性,从高维视频中学习丰富的多尺度时空语义是一项具有挑战性的任务。这项研究的最新进展主要由 3D 卷积神经网络和视觉 Transformer 驱动。尽管 3D 卷积可以有效地聚合局部上下文以抑制来自小型 3D 邻域的局部冗余,但由于感受野有限,它缺乏捕获全局依赖性的能力。或者,Vision Transformers 可以通过自我注意机制有效地捕获远程依赖,但在减少局部冗余方面存在限制,通过在每一层中的所有标记之间进行盲目相似性比较。
基于这些观察,我们提出了一种新颖的统一变换器(UniFormer),它以简洁的变换器格式无缝集成了 3D 卷积和时空自注意力的优点,并在计算和精度之间取得了较好的平衡。与传统的转换器不同,我们的关系聚合器可以通过分别在浅层和深层学习局部和全局token的亲和力来解决时空冗余和依赖性。我们对流行的视频基准进行了广泛的实验,例如 Kinetics-400、Kinetics-600 和 Something-Something V1&V2。仅通过 ImageNet-1K 预训练,我们的 UniFormer 在 Kinetics-400/Kinetics-600 上实现了 82.9%/84.8% 的 top-1 准确率,同时比其他最先进的方法需要少 10 倍的 GFLOP。对于Something-Something V1 和 V2,我们的 UniFormer 分别实现了 60.9% 和 71.2% 的 top-1 准确度。
Introduction
学习时空表示是视频理解的一项基本任务。基本上,有两个截然不同的挑战。一方面,视频包含很大的时空冗余度,目标在局部相邻帧上的运动是微妙的。另一方面,视频包含复杂的时空相关性,因为跨长距离帧的目标关系是动态的。
视频分类的进步主要是由3D卷积神经网络(Tranetal.,2015;Carreira&Zisserman,2007b;Feichtenhofer等人,2019年)和时空transformer(Bertasius等人,2021年;Arnab等人,2021年)推动的。不幸的是,这两个框架都侧重于上述挑战之一。3D卷积可以通过处理来自小的3D邻域(例如,3×3×3)的每个像素的上下文来捕捉详细的和局部的时空-时间特征。因此,它可以减少相邻帧之间的时空冗余。然而,由于有限的接受野,3D卷积在学习长距离依赖方面存在困难(Wanget等人,2018年;Li等人,2020a)。或者,vision transformer在视觉标记中的自我注意的帮助下,擅长捕捉长距离依赖(Dosovitski等人,2021)。最近,这种设计被引入到通过时空注意机制进行视频分类(Berta-sius等人,2021年)。然而,我们观察到,vision transformer在对浅层的局部时空特征进行编码时往往效率低下。我们以著名的典型的TimeSformer(Bertasius等人,2021年)为例。如图1所示,TimeSformer确实学习了早期层的细节视频表征,但具有非常冗余的空间和时间注意,具体而言,空间注意主要集中在相邻的标记(主要在3×3局部区域)上,而不从同一帧中的其余标记学习。类似地,时间注意大多只聚合相邻帧中的标记,而忽略远距离帧中的其余标记。更重要的是,这种局部表示是通过所有层的全局令牌到令牌相似度比较来学习的,需要很大的计算量。这一事实明显降低了这种视频transoformer的计算精度平衡(图2)。
为了解决这些困难,我们提出了将三维卷积和时空自我注意有效地统一在一种简洁的变换格式中,因此我们将其命名为网络统一变换(Uniformer),它可以在效率和有效性之间达到较好的平衡。具体地说,我们的UniFormer由三个核心模块组成,即动态位置嵌入(DPE)、多头关系聚合器(MHRA)和前馈网络(FFN)。我们的UniFormer与传统视频transformer之间的关键区别在于我们的关系聚合器的独特设计。
首先,我们提出的关系聚合器不是在所有层都使用自我注意机制,而是分别处理视频冗余和依赖。在浅层,我们的聚合器通过一个小的可学习参数矩阵来学习局部关系,这可以通过在一个小的3D邻域中聚合相邻标记的上下文来极大地减少计算负担。在深层,我们的聚合器通过相似性比较来学习全局关系,可以灵活地从视频中的远程帧建立远程令牌依赖关系。Mparison,它可以灵活地从视频中的远程帧建立远程令牌依赖关系。
第二,不同于传统变换(Bertasius等人,2021;Arnabet等人,2021)中的空间和时间注意分离,我们的关系聚集器在所有层次上联合编码时空上下文,从而以联合学习的方式进一步提高视频表示。
最后,我们通过以分层方式逐步集成UniFormer块来构建我们的模型。在这种情况下,我们扩大了局部和全局UniFormer块的协作能力,以实现视频中高效的时空表示学习。我们在流行的视频基准上进行了广泛的实验,例如Kineticss-400(Carreira&Zisserman,2017a)、Kinetics-600(Carreira等人,2018)和Something-Something V1&V2(GoYal等人,2007b)。
Method
1.Overview of uniformer block
为了克服时空冗余和依赖的问题,我们提出了一种新颖而简洁的统一转换器(UniFormer),如图3所示。我们使用一种基本的transformer格式然而是专门为高效的时空表征学习而设计的。具体来说,我们的UniFormer块由三个关键模块组成:动态位置嵌入(DPE)、多头关系聚合器(MHRA)和前馈网络(FFN)。
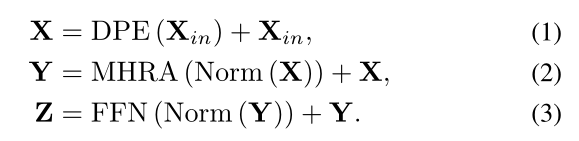

考虑到输入的令牌张量(帧体积)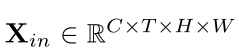 ,我们首先引入DPE来动态地将3D位置信息集成到所有tokens(Eq.1),它有效地利用了tokens的时空顺序进行视频建模。然后,我们利用MHRA来聚合每个令牌及其上下文tokens(Eq.2)。与常规的多头自关注(MHSA)不同,MHRA通过在浅层和深层灵活地设计token亲和性学习,巧妙地解决了局部视频冗余和全局视频依赖问题。最后,我们添加了具有两个线性层的FFN,以逐点增强每个token(Eq.3)。
,我们首先引入DPE来动态地将3D位置信息集成到所有tokens(Eq.1),它有效地利用了tokens的时空顺序进行视频建模。然后,我们利用MHRA来聚合每个令牌及其上下文tokens(Eq.2)。与常规的多头自关注(MHSA)不同,MHRA通过在浅层和深层灵活地设计token亲和性学习,巧妙地解决了局部视频冗余和全局视频依赖问题。最后,我们添加了具有两个线性层的FFN,以逐点增强每个token(Eq.3)。
2.Multi-head Relation Aggregator
如上所述,我们应该解决大的局部冗余度和复杂的全局依赖,高效和有效的时空表示学习。不幸的是,流行的3D CNN和时空转换器只关注这两个挑战中的一个。为此,我们设计了一种替代的关系聚合器(RA),它可以灵活地将3D卷积和时空自我注意以简洁的变换格式统一起来,分别解决了浅层和深层的视频冗余和依赖问题。具体来说,我们的MHRA通过多头融合进行token关系学习:
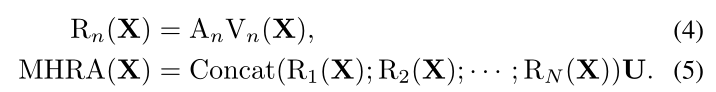
输入tensor
X
i
n
∈
R
C
×
T
×
H
×
W
X_{in}∈R^{C×T×H×W}
Xin∈RC×T×H×W ,首先将其reshape成一个sequence
X
∈
R
L
×
C
X∈R^{L×C}
X∈RL×C ,L=T×H×W,
R
n
R^n
Rn是第n个头上的关系聚合器RA,
U
∈
R
C
×
C
U∈R^{C×C}
U∈RC×C是一个可学习的参数矩阵来聚合N个head,每个RA包含token的上下文编码和亲和力学习。通过一个线性变换,可以将原始token转换为上下文
V
n
(
x
)
∈
R
L
×
c
/
n
V_n(x)∈R^{L×c/n}
Vn(x)∈RL×c/n,随后RA可以在token亲和力
A
n
(
x
)
∈
R
L
×
L
A_n(x)∈R^{L×L}
An(x)∈RL×L的指导下总结上下文,RA中的关键就是如何学习视频中的
A
n
A_n
An。
Local MHRA
在浅层,我们的目标是从小的3D邻域的局部时空环境中学习详细的视频表示。巧合的是,这与3D卷积滤波器的设计具有相似的见解。因此,我们将token亲和力设计为在局部3D邻域中操作的可学习参数矩阵,即,给定一个anchor token
X
i
X_i
Xi ,RA学习该token与small tube
Ω
i
t
×
h
×
w
Ω_i^{t×h×w}
Ωit×h×w中的其他token之间的局部时空亲和力。
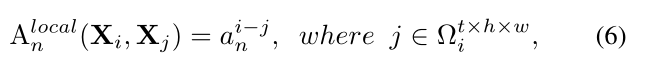
其中
A
n
∈
R
t
×
h
×
w
A_n∈R^{t×h×w}
An∈Rt×h×w,
X
j
X_j
Xj代表
Ω
i
t
×
h
×
w
Ω_i^{t×h×w}
Ωit×h×w中的任意相邻token,(i-j)代表相邻token的index,决定了聚合的权重。在浅层中,相邻token之间的视频内容变化很小,使用局部算子对细节特征进行编码对于减少冗余度具有重要意义。因此,token亲和力被设计为可局部学习的参数矩阵,其值仅取决于token之间的相对3D位置。
Comparison to 3D Convolution Block
有趣的是,我们发现我们的local MHRA可以被解释为MobileNet块的时空延伸。具体地说,线性变换V(·)可以实例化为逐点卷积(PWConv)。此外,local token亲和力
A
n
l
o
c
a
l
A_n^{local}
Anlocal是在每个输出通道(或head)
V
n
(
x
)
V_n(x)
Vn(x)上运算的时空矩阵,因此关系聚集器
R
n
(
x
)
=
A
n
l
o
c
a
l
V
n
(
x
)
R_n(x)=A_n^{local}V_n(x)
Rn(x)=AnlocalVn(x)可以解释为深度卷积(DWConv)。最后,所有头部被一个线性矩阵U连接和融合,该矩阵也可以被实例化为逐点卷积(PWConv)。因此,可以在MobileNet块中以PWConv-DWConv-PWConv的方式重新制定这个local MHRA。在实验中,我们灵活地将local MHRA实例化为通道分离的时空卷积,从而使UniFormer能够继承轻量级视频分类的计算效率。与MobileNet块不同,UniFormer块被设计为通用的transformer格式,因此在MHRA之后插入额外的FFN,从而可以在每个时空位置进一步混合token上下文以提高分类精度。
Global MHRA
在更深的层面上,我们专注于捕捉全球视频片段中的长程token依赖。这自然与自我注意的设计有相似的见解。因此,我们通过比较全局视图中所有token之间的内容相似度来设计token亲和力: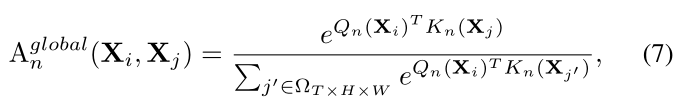
其中
X
j
X_j
Xj是全局3D tube中的任意token,尺寸是T×H×W,
Q
n
(
⋅
)
Q_n(·)
Qn(⋅)和
K
n
(
⋅
)
K_n(·)
Kn(⋅)是两种不同的线性转换层。大多数video transformer在所有阶段都采用自我注意,这引入了大量的计算量。为了减少点积计算,以前的工作倾向于将空间和时间注意力分开,但它恶化了标记之间的时空关系。相比之下,我们的MHRA在早期层进行局部关系聚集,大大节省了token比较的计算量。因此,我们不是分散时空注意力,而是在我们的MHRA中联合编码所有阶段的时空关系,以达到更好的计算和精度平衡。
Comparison to Transformer Block
在深层,我们的UniFormer模块配备了全局MHRA
A
n
g
l
o
b
a
l
A_n^{global}
Anglobal(公式7)。它可以被实例化为时空自我注意,其中Qn(·)、Kn(·)和Vn(·)成为转换器中的Q、K和V。因此,它可以有效地学习长期依赖。与之前的video transformer中的空间和时间分解不同,我们的全局MHRA基于联合时空学习来生成更具区分性的视频表示。此外,我们采用动态位置嵌入(DPE,参见第3.3节)来克服排列不变性,它可以保持平移不变性,并且对不同的输入片段长度是友好的。
3.Dynamic Position Embedding
由于视频既是空间变量又是时间变量,因此有必要对token表示的时空位置信息进行编码。 以前的方法主要采用图像任务的绝对或相对位置嵌入来解决这个问题(Bertasius et al., 2021; Arnab et al., 2021)。但是,当使用较长的输入clips进行测试时,应该将绝对值内插到目标微调输入大小。 此外,相对版本由于缺乏绝对位置信息而修改了自注意力并且性能更差(Islam et al., 2020)。
为了克服上述为题,我们扩展了条件位置编码CPE来设计我们的动态位置编码DPE: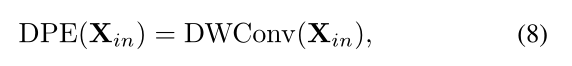
其中,DWConv表示具有零填充的简单3D深度卷积。由于卷积的共享参数和局部性,DPE可以克服排列不变性,并且对任意输入长度都是友好的。此外,在CPE中已经证明,零填充有助于边界上的token知道它们的绝对位置,因此所有的token都可以通过查询它们的邻居来逐步编码它们的时空位置信息。
Model Architecture
我们分层地堆叠UniFormer块来构建我们的时空学习网络。如图3所示,我们的网络由四个阶段组成,通道编号分别为64、128、320和512。根据这些阶段UniFormer块的数量,我们提供了两种模型变体:UniFormer-S的{3,4,8,3}和UniFormer-B的{5,8,20,7}。在前两个阶段,我们利用具有local token亲和力的MHRA(Eq.6)减少短期时空冗余度。tube尺寸设置为5×5×5,头数N等于相应的通道数。在最后两个阶段,我们应用具有global token亲和力(Eq.7)捕获长期依赖,其头部维度为64。我们将BN用于local MHRA,将LN用于global MHRA。
DPE的核大小为3×3×3(T×H×W),各层FFN的展开比为4。在第一级之前,我们采用了3×4×4卷积,跨度为2×4×4,这意味着空间和时间维度都是下采样的。在其他阶段之前,我们采用1×2×2的卷积,步长为1×2×2。最后,利用时空平均合并和全连通层来输出最终的预测。
Comparison to Convolution+Transformer Network
先前的研究已经证明,自我注意可以进行卷积,但他们建议取代卷积,而不是将它们结合起来。最近的工作试图将卷积引入vision transformer,但他们主要集中在图像识别上,没有任何时空上的考虑来进行视频理解。此外,在以前的video transformer中,这种组合几乎是直接的,例如,使用transformer作为全局关注(Wang等人,2018年)或使用卷积作为patch stem(Liu等人,2020b)。相比之下,我们的UniFormer通过一个有洞察力的统一框架解决了视频冗余和依赖性问题(表1)。通过局部和全局token亲和力学习,我们可以在视频分类的计算量和准确率之间取得较好的平衡。
Framework
在这一部分中,我们主要为各种下游任务开发可视化框架。具体地说,我们首先开发了一些用于图像分类的可视化主干,通过分层堆叠我们的局部和全局统一块来考虑计算和精度平衡。然后,我们将上述主干扩展到其他具有代表性的视觉任务,包括视频分类和密集预测(即目标检测、语义分割和人体姿势估计)。我们的UniFormer的这种通用性和灵活性显示了它在计算机视觉研究和其他方面的宝贵潜力。
Dense Predection
密集的预测任务是验证我们的识别主干的通用性所必需的。因此,我们采用我们的UniFormer Backbone来执行一些流行的密集任务,如对象检测、实例分割、语义分割和人体姿势估计。然而,直接使用我们的主干是不合适的,因为大多数密集预测任务的输入分辨率都很高,例如,在COCO目标检测数据集中,图像的大小为1333×800。当然,将这样的图像输入到我们的分类骨干中将不可避免地导致巨大的计算量,特别是在最后两个阶段操作全局UniFormer块的自我注意时。以h×w个视觉符号为例,给出了符号相似度比较中的Matmul运算(等式7)导致O(W2h2)复杂性,这对于最密集的任务是令人望而却步的。
为此,我们建议针对不同的下游任务调整全局UniFormerblock。首先,我们分析了我们的UniFormer-S在不同输入分辨率下的FLOPS。如图4所示,清楚地表明Stage3中的关系聚合器(RA)计算量很大,例如对于1008×1008的图像,RA在Stage3中的Matmul操作甚至占据了UniFormer-S全部Flop的50%以上,而Stage4中的Flop仅为Stage3中的1/28。因此,我们主要对Stage3中的RA进行修改,以减少计算量。
受[56]、[68]的启发,我们建议将全局MHRA应用于预定义的窗口(例如,14×14),而不是将其用于高分辨率的整个图像。这种运算可以有效地减少计算量。然而,由于token交互不足,它无疑会降低模型的性能。为了弥补这一差距,我们在阶段3将窗口块和全局UniFormer块整合在一起,其中混合组由三个窗口块和一个全局块组成。在这种情况下,在我们的UniFormer-Small/Base主干的阶段3中有2/5的混合组。
在此设计的基础上,根据训练和测试图像的输入分辨率,介绍了各种密集任务的具体backbone设置。对于目标检测和实例分割,输入的图像通常很大(例如1333×800),因此我们在阶段3采用了混合块风格。相比之下,用于姿态估计的输入相对较小,例如384×288,因此在阶段3中仍然应用全局块来进行训练和测试。
Experiments
为了验证UniFormer用于视觉识别的有效性和效率,我们在ImageNet-1K[21]图像分类、Kinetics-400[10]/600[9]和Something-Something V1&V2[33]视频分类、COCO[55]对象检测、实例分割和姿态估计以及ADE20K[109]语义分割上进行了大量的实验。我们还进行全面的消融研究,以分析我们的UniFormer的每一种设计。
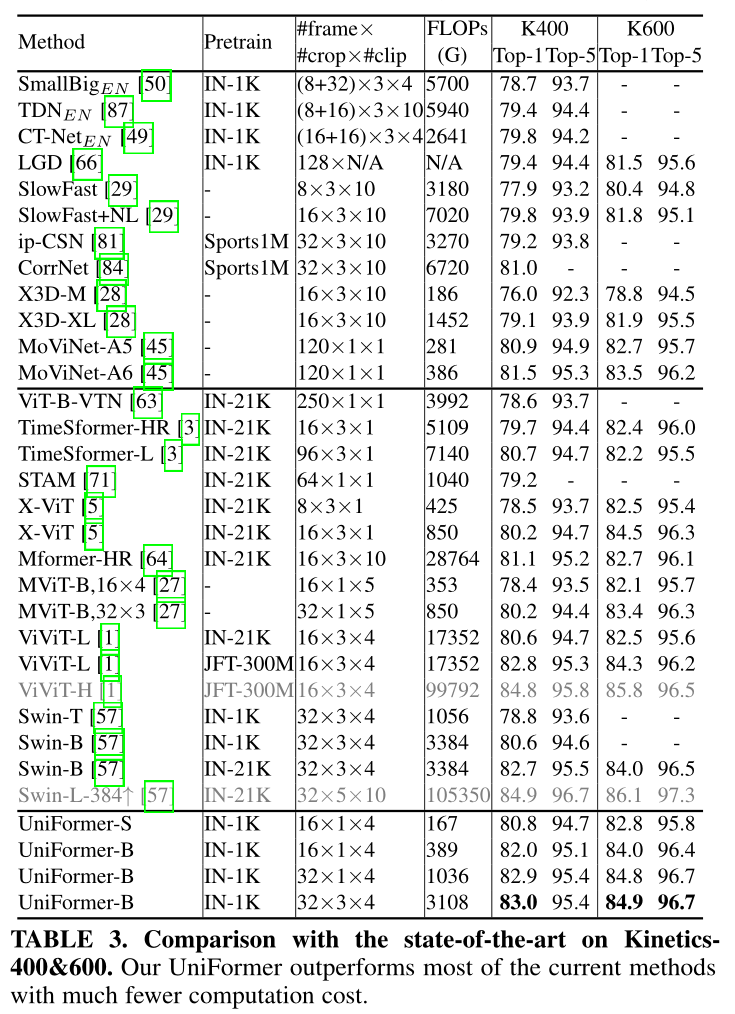
Results on Kinetics
在表3中,我们将我们的UniFormer与Kinetics-400和Kinetics-600上的最先进方法进行了比较。第一部分展示了之前使用CNN的作品。与配备非本地块的SlowFast[29]相比[90],我们的UniFormer-S16f需要少42倍的gflop,但在两个数据集上都获得了1.0%的性能提升(80.8% vs. 79.8%和82.8% vs. 81.8%)。即使与MoViNet[45]相比,这是一个强大的基于cnn的模型,通过广泛的神经结构搜索,我们的模型获得了更好的结果(82.0% vs. 81.5%),输入帧更少(16f×4 vs. 120 f)。
注意力机制
class Attention(nn.Module):
def __init__(self, dim, num_heads=8, qkv_bias=False, qk_scale=None, attn_drop=0., proj_drop=0.):
super().__init__()
self.num_heads = num_heads
head_dim = dim // num_heads
# NOTE scale factor was wrong in my original version, can set manually to be compat with prev weights
self.scale = qk_scale or head_dim ** -0.5
self.qkv = nn.Linear(dim, dim * 3, bias=qkv_bias)
self.attn_drop = nn.Dropout(attn_drop)
self.proj = nn.Linear(dim, dim)
self.proj_drop = nn.Dropout(proj_drop)
def forward(self, x):
B, N, C = x.shape
qkv = self.qkv(x).reshape(B, N, 3, self.num_heads, C // self.num_heads).permute(2, 0, 3, 1, 4)
q, k, v = qkv[0], qkv[1], qkv[2] # make torchscript happy (cannot use tensor as tuple)
attn = (q @ k.transpose(-2, -1)) * self.scale
attn = attn.softmax(dim=-1)
attn = self.attn_drop(attn)
x = (attn @ v).transpose(1, 2).reshape(B, N, C)
x = self.proj(x)
x = self.proj_drop(x)
return x
patch embeded模块
class PatchEmbed(nn.Module):
""" Image to Patch Embedding
"""
def __init__(self, img_size=224, patch_size=16, in_chans=3, embed_dim=768, std=False):
super().__init__()
img_size = to_2tuple(img_size)
patch_size = to_2tuple(patch_size)
num_patches = (img_size[1] // patch_size[1]) * (img_size[0] // patch_size[0])
self.img_size = img_size
self.patch_size = patch_size
self.num_patches = num_patches
self.norm = nn.LayerNorm(embed_dim)
if std:
self.proj = conv_3xnxn_std(in_chans, embed_dim, kernel_size=patch_size[0], stride=patch_size[0])
else:
self.proj = conv_1xnxn(in_chans, embed_dim, kernel_size=patch_size[0], stride=patch_size[0])
def forward(self, x):
B, C, T, H, W = x.shape
# FIXME look at relaxing size constraints
# assert H == self.img_size[0] and W == self.img_size[1], \
# f"Input image size ({H}*{W}) doesn't match model ({self.img_size[0]}*{self.img_size[1]})."
x = self.proj(x)
B, C, T, H, W = x.shape
x = x.flatten(2).transpose(1, 2)
x = self.norm(x)
x = x.reshape(B, T, H, W, -1).permute(0, 4, 1, 2, 3).contiguous()
return x
uniformer
class Uniformer(nn.Module):
""" Vision Transformer
A PyTorch impl of : `An Image is Worth 16x16 Words: Transformers for Image Recognition at Scale` -
https://arxiv.org/abs/2010.11929
"""
def __init__(self, cfg):
super().__init__()
depth = cfg.UNIFORMER.DEPTH
num_classes = cfg.MODEL.NUM_CLASSES
img_size = cfg.DATA.TRAIN_CROP_SIZE
in_chans = cfg.DATA.INPUT_CHANNEL_NUM[0]
embed_dim = cfg.UNIFORMER.EMBED_DIM
head_dim = cfg.UNIFORMER.HEAD_DIM
mlp_ratio = cfg.UNIFORMER.MLP_RATIO
qkv_bias = cfg.UNIFORMER.QKV_BIAS
qk_scale = cfg.UNIFORMER.QKV_SCALE
representation_size = cfg.UNIFORMER.REPRESENTATION_SIZE
drop_rate = cfg.UNIFORMER.DROPOUT_RATE
attn_drop_rate = cfg.UNIFORMER.ATTENTION_DROPOUT_RATE
drop_path_rate = cfg.UNIFORMER.DROP_DEPTH_RATE
split = cfg.UNIFORMER.SPLIT
std = cfg.UNIFORMER.STD
self.use_checkpoint = cfg.MODEL.USE_CHECKPOINT
self.checkpoint_num = cfg.MODEL.CHECKPOINT_NUM
logger.info(f'Use checkpoint: {self.use_checkpoint}')
logger.info(f'Checkpoint number: {self.checkpoint_num}')
self.num_classes = num_classes
self.num_features = self.embed_dim = embed_dim # num_features for consistency with other models
norm_layer = partial(nn.LayerNorm, eps=1e-6)
self.patch_embed1 = SpeicalPatchEmbed(
img_size=img_size, patch_size=4, in_chans=in_chans, embed_dim=embed_dim[0])
self.patch_embed2 = PatchEmbed(
img_size=img_size // 4, patch_size=2, in_chans=embed_dim[0], embed_dim=embed_dim[1], std=std)
self.patch_embed3 = PatchEmbed(
img_size=img_size // 8, patch_size=2, in_chans=embed_dim[1], embed_dim=embed_dim[2], std=std)
self.patch_embed4 = PatchEmbed(
img_size=img_size // 16, patch_size=2, in_chans=embed_dim[2], embed_dim=embed_dim[3], std=std)
self.pos_drop = nn.Dropout(p=drop_rate)
dpr = [x.item() for x in torch.linspace(0, drop_path_rate, sum(depth))] # stochastic depth decay rule
num_heads = [dim // head_dim for dim in embed_dim]
self.blocks1 = nn.ModuleList([
CBlock(
dim=embed_dim[0], num_heads=num_heads[0], mlp_ratio=mlp_ratio, qkv_bias=qkv_bias, qk_scale=qk_scale,
drop=drop_rate, attn_drop=attn_drop_rate, drop_path=dpr[i], norm_layer=norm_layer)
for i in range(depth[0])])
self.blocks2 = nn.ModuleList([
CBlock(
dim=embed_dim[1], num_heads=num_heads[1], mlp_ratio=mlp_ratio, qkv_bias=qkv_bias, qk_scale=qk_scale,
drop=drop_rate, attn_drop=attn_drop_rate, drop_path=dpr[i+depth[0]], norm_layer=norm_layer)
for i in range(depth[1])])
if split:
self.blocks3 = nn.ModuleList([
SplitSABlock(
dim=embed_dim[2], num_heads=num_heads[2], mlp_ratio=mlp_ratio, qkv_bias=qkv_bias, qk_scale=qk_scale,
drop=drop_rate, attn_drop=attn_drop_rate, drop_path=dpr[i+depth[0]+depth[1]], norm_layer=norm_layer)
for i in range(depth[2])])
self.blocks4 = nn.ModuleList([
SplitSABlock(
dim=embed_dim[3], num_heads=num_heads[3], mlp_ratio=mlp_ratio, qkv_bias=qkv_bias, qk_scale=qk_scale,
drop=drop_rate, attn_drop=attn_drop_rate, drop_path=dpr[i+depth[0]+depth[1]+depth[2]], norm_layer=norm_layer)
for i in range(depth[3])])
else:
self.blocks3 = nn.ModuleList([
SABlock(
dim=embed_dim[2], num_heads=num_heads[2], mlp_ratio=mlp_ratio, qkv_bias=qkv_bias, qk_scale=qk_scale,
drop=drop_rate, attn_drop=attn_drop_rate, drop_path=dpr[i+depth[0]+depth[1]], norm_layer=norm_layer)
for i in range(depth[2])])
self.blocks4 = nn.ModuleList([
SABlock(
dim=embed_dim[3], num_heads=num_heads[3], mlp_ratio=mlp_ratio, qkv_bias=qkv_bias, qk_scale=qk_scale,
drop=drop_rate, attn_drop=attn_drop_rate, drop_path=dpr[i+depth[0]+depth[1]+depth[2]], norm_layer=norm_layer)
for i in range(depth[3])])
self.norm = bn_3d(embed_dim[-1])
# Representation layer
if representation_size:
self.num_features = representation_size
self.pre_logits = nn.Sequential(OrderedDict([
('fc', nn.Linear(embed_dim, representation_size)),
('act', nn.Tanh())
]))
else:
self.pre_logits = nn.Identity()
# Classifier head
self.head = nn.Linear(embed_dim[-1], num_classes) if num_classes > 0 else nn.Identity()
self.apply(self._init_weights)
for name, p in self.named_parameters():
# fill proj weight with 1 here to improve training dynamics. Otherwise temporal attention inputs
# are multiplied by 0*0, which is hard for the model to move out of.
if 't_attn.qkv.weight' in name:
nn.init.constant_(p, 0)
if 't_attn.qkv.bias' in name:
nn.init.constant_(p, 0)
if 't_attn.proj.weight' in name:
nn.init.constant_(p, 1)
if 't_attn.proj.bias' in name:
nn.init.constant_(p, 0)
def _init_weights(self, m):
if isinstance(m, nn.Linear):
trunc_normal_(m.weight, std=.02)
if isinstance(m, nn.Linear) and m.bias is not None:
nn.init.constant_(m.bias, 0)
elif isinstance(m, nn.LayerNorm):
nn.init.constant_(m.bias, 0)
nn.init.constant_(m.weight, 1.0)
@torch.jit.ignore
def no_weight_decay(self):
return {'pos_embed', 'cls_token'}
def get_classifier(self):
return self.head
def reset_classifier(self, num_classes, global_pool=''):
self.num_classes = num_classes
self.head = nn.Linear(self.embed_dim, num_classes) if num_classes > 0 else nn.Identity()
def inflate_weight(self, weight_2d, time_dim, center=False):
if center:
weight_3d = torch.zeros(*weight_2d.shape)
weight_3d = weight_3d.unsqueeze(2).repeat(1, 1, time_dim, 1, 1)
middle_idx = time_dim // 2
weight_3d[:, :, middle_idx, :, :] = weight_2d
else:
weight_3d = weight_2d.unsqueeze(2).repeat(1, 1, time_dim, 1, 1)
weight_3d = weight_3d / time_dim
return weight_3d
def get_pretrained_model(self, cfg):
if cfg.UNIFORMER.PRETRAIN_NAME:
checkpoint = torch.load(model_path[cfg.UNIFORMER.PRETRAIN_NAME], map_location='cpu')
if 'model' in checkpoint:
checkpoint = checkpoint['model']
elif 'model_state' in checkpoint:
checkpoint = checkpoint['model_state']
state_dict_3d = self.state_dict()
for k in checkpoint.keys():
if checkpoint[k].shape != state_dict_3d[k].shape:
if len(state_dict_3d[k].shape) <= 2:
logger.info(f'Ignore: {k}')
continue
logger.info(f'Inflate: {k}, {checkpoint[k].shape} => {state_dict_3d[k].shape}')
time_dim = state_dict_3d[k].shape[2]
checkpoint[k] = self.inflate_weight(checkpoint[k], time_dim)
if self.num_classes != checkpoint['head.weight'].shape[0]:
del checkpoint['head.weight']
del checkpoint['head.bias']
return checkpoint
else:
return None
def forward_features(self, x):
x = self.patch_embed1(x)
x = self.pos_drop(x)
for i, blk in enumerate(self.blocks1):
if self.use_checkpoint and i < self.checkpoint_num[0]:
x = checkpoint.checkpoint(blk, x)
else:
x = blk(x)
x = self.patch_embed2(x)
for i, blk in enumerate(self.blocks2):
if self.use_checkpoint and i < self.checkpoint_num[1]:
x = checkpoint.checkpoint(blk, x)
else:
x = blk(x)
x = self.patch_embed3(x)
for i, blk in enumerate(self.blocks3):
if self.use_checkpoint and i < self.checkpoint_num[2]:
x = checkpoint.checkpoint(blk, x)
else:
x = blk(x)
x = self.patch_embed4(x)
for i, blk in enumerate(self.blocks4):
if self.use_checkpoint and i < self.checkpoint_num[3]:
x = checkpoint.checkpoint(blk, x)
else:
x = blk(x)
x = self.norm(x)
x = self.pre_logits(x)
return x
def forward(self, x):
x = x[0]
x = self.forward_features(x)
x = x.flatten(2).mean(-1)
x = self.head(x)
return x















 4930
4930











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









