





1 简介
本文根据2022年2月《UNIFORMER: UNIFIED TRANSFORMER FOR EFFICIENT
SPATIOTEMPORAL REPRESENTATION LEARNING》翻译总结的。
从一个高维度的视频中学习丰富且多尺度的时空语义信息是一个非常有挑战的任务,因为视频中帧与帧之间有大量的局部冗余(local redundancy)和复杂的全局依赖( global dependency)。相邻帧之间目标移动是微小的。但长范围内的帧中的目标又是动态相关的。
最近的研究主要集中再3D卷积神经网络和视觉transformer。虽然3D卷积可以在一个小的3D领域内(如3*3*3)可以捕捉详细的局部时空特征,减少了相邻帧之间的时空冗余,即有效处理局部信息来控制局部冗余,但因为受限制的接受域,缺乏捕捉全局依赖的能力。而视觉transformer通过自注意力机制可以捕捉长范围的依赖,但又在每个层中所有token的盲目相似比较导致其不能很好的减少局部冗余。如下表所示:
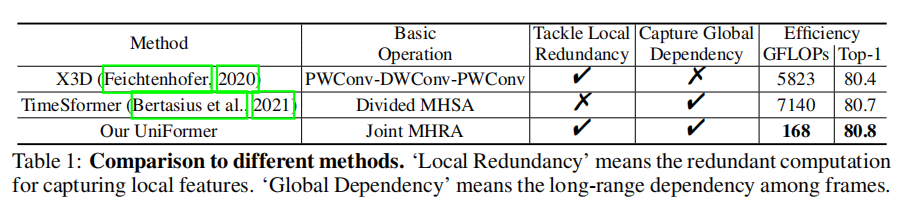
基于此我们提出了Unifified transFormer (UniFormer) ,集成了3D卷积和transformer,在计算量和准确度之间取得了较好的平衡。可以同时处理时空冗余和依赖。代码详见https://github.com/Sense-X/UniFormer.
2 方法
整个模型包括4阶段(stage),每个阶段是一个UniFormer模块,其channel分别为64、128、320、512。每个UniFormer模块包括3部分,分别为:Dynamic Position Embedding (DPE)、Multi-Head Relation Aggregator (MHRA)、Feed-Forward Network (FFN)。前两个阶段(shallow浅)学习局部关系(local),减少计算负担;后两个阶段(deep)学习全局关系(global)。
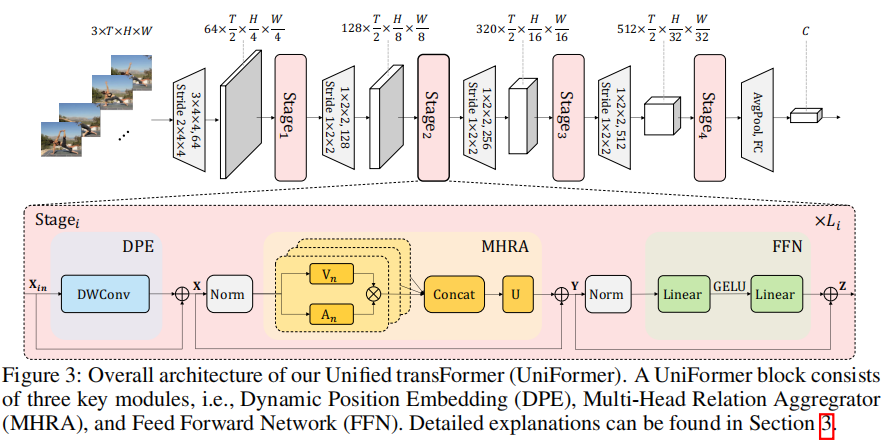
整体架构的公式如下:
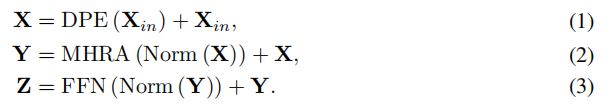
2.1 Multi-Head Relation Aggregator (MHRA)
采用多头混合:
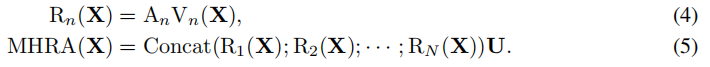
其中A是token亲和度(token affifinity),下面会分为local和global的。V指线性transformer。U是一个可以学习的参数矩阵,来集成N个头(R)。
local MHRA
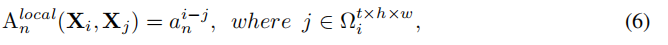
其中i,j指领域token的index。整个A是一个局部可以学习的参数矩阵。
整个模型的前两个阶段采用local MHRA.
global MHRA
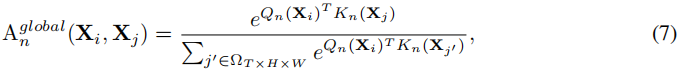
其中Q、K是两个不同的线性转换。
整个模型的后两个阶段采用global MHRA.
local MHRA采用BN,global MHRA采用LN。
2.2 Dynamic Position Embedding (DPE)
DPE可以保持转换不变性,是友好的对于不同的裁剪长度。
我们将conditional position encoding (CPE) 进行扩展,来设计DPE。公式如下:
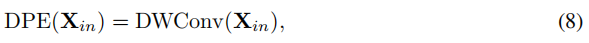
其中DWConv表示简单的3D深度方向卷积,其采用0 padding。
3 实验
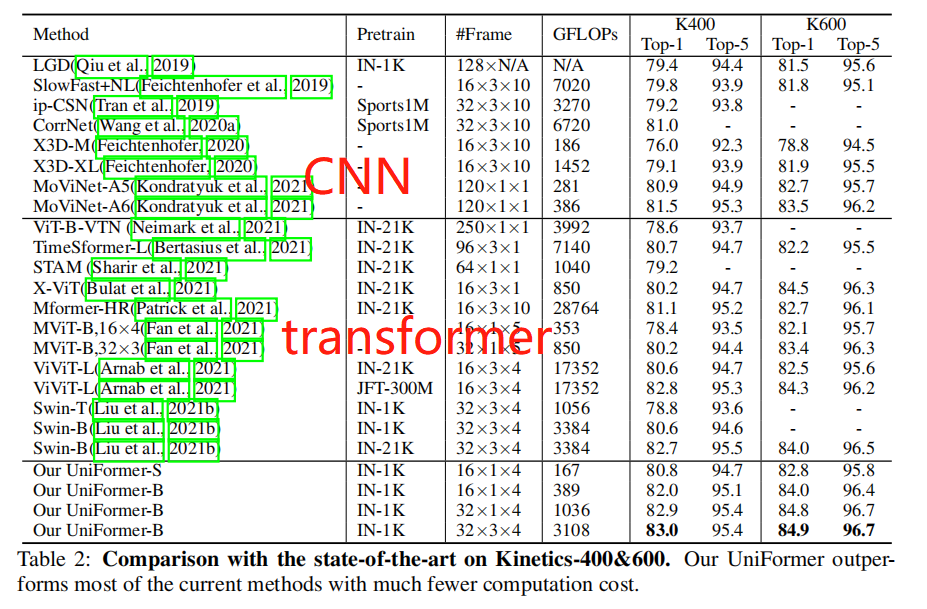
在Kinetics-400&600数据集上,可以看到我们的模型好于3D CNN和transformer。
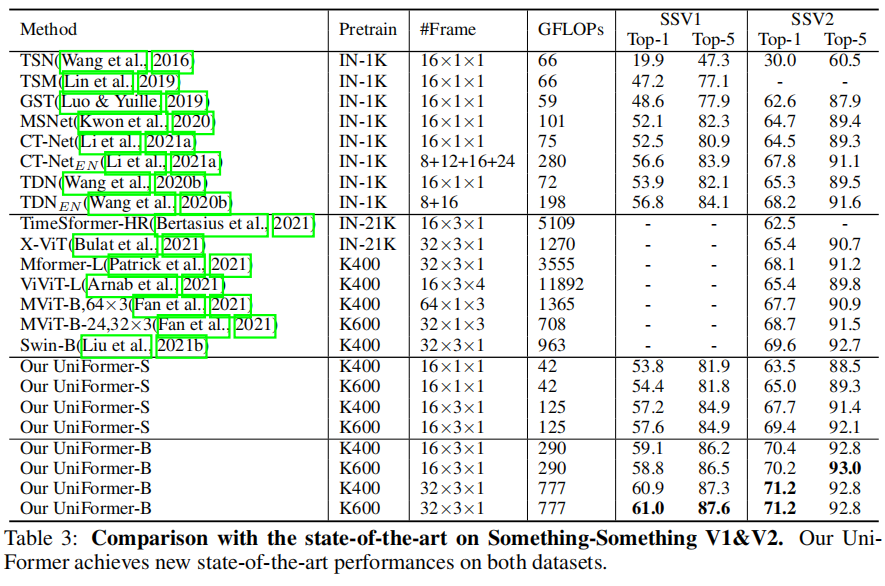
Something-Something V1&V2数据集上,CNN类的模型不能很好的捕捉长依赖,效果价差。而UNIFORMER依然较好,如下表:

















 774
774

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









