






第P7周:咖啡豆识别
- 🍨 本文为🔗365天深度学习训练营 中的学习记录博客
- 🍦 参考文章:Pytorch实战 | 第P7周:咖啡豆识别(训练营内部成员可读)
- 🍖 原作者:K同学啊|接辅导、项目定制
本周主要学习如何降低模型参数量,但是尽可能的减少准确率的降低。
import torch.nn.functional as F
class vgg16(nn.Module):
def __init__(self):
super(vgg16, self).__init__()
# 卷积块1
self.block1 = nn.Sequential(
nn.Conv2d(3, 64, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1)),
nn.ReLU(),
nn.Conv2d(64, 64, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1)),
nn.ReLU(),
nn.MaxPool2d(kernel_size=(2, 2), stride=(2, 2))
)
# 卷积块2
self.block2 = nn.Sequential(
nn.Conv2d(64, 128, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1)),
nn.ReLU(),
nn.Conv2d(128, 128, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1)),
nn.ReLU(),
nn.MaxPool2d(kernel_size=(2, 2), stride=(2, 2))
)
# 卷积块3
self.block3 = nn.Sequential(
nn.Conv2d(128, 256, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1)),
nn.ReLU(),
nn.Conv2d(256, 256, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1)),
nn.ReLU(),
nn.Conv2d(256, 256, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1)),
nn.ReLU(),
nn.MaxPool2d(kernel_size=(2, 2), stride=(2, 2))
)
# 卷积块4
self.block4 = nn.Sequential(
nn.Conv2d(256, 512, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1)),
nn.ReLU(),
nn.Conv2d(512, 512, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1)),
nn.ReLU(),
nn.Conv2d(512, 512, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1)),
nn.ReLU(),
nn.MaxPool2d(kernel_size=(2, 2), stride=(2, 2))
)
# 卷积块5
self.block5 = nn.Sequential(
nn.Conv2d(512, 512, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1)),
nn.ReLU(),
nn.Conv2d(512, 512, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1)),
nn.ReLU(),
nn.Conv2d(512, 512, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1)),
nn.ReLU(),
nn.MaxPool2d(kernel_size=(2, 2), stride=(2, 2)),
nn.Conv2d(512, 256, kernel_size=(1, 1))
)
# 全连接网络层,用于分类
self.classifier = nn.Sequential(
nn.Linear(in_features=256*7*7, out_features=4096),
nn.ReLU(),
nn.Linear(in_features=4096, out_features=4096),
nn.ReLU(),
nn.Linear(in_features=4096, out_features=4)
)
def forward(self, x):
x = self.block1(x)
x = self.block2(x)
x = self.block3(x)
x = self.block4(x)
x = self.block5(x)
x = torch.flatten(x, start_dim=1)
x = self.classifier(x)
return x
device = "cuda" if torch.cuda.is_available() else "cpu"
print("Using {} device".format(device))
model = vgg16().to(device)
model
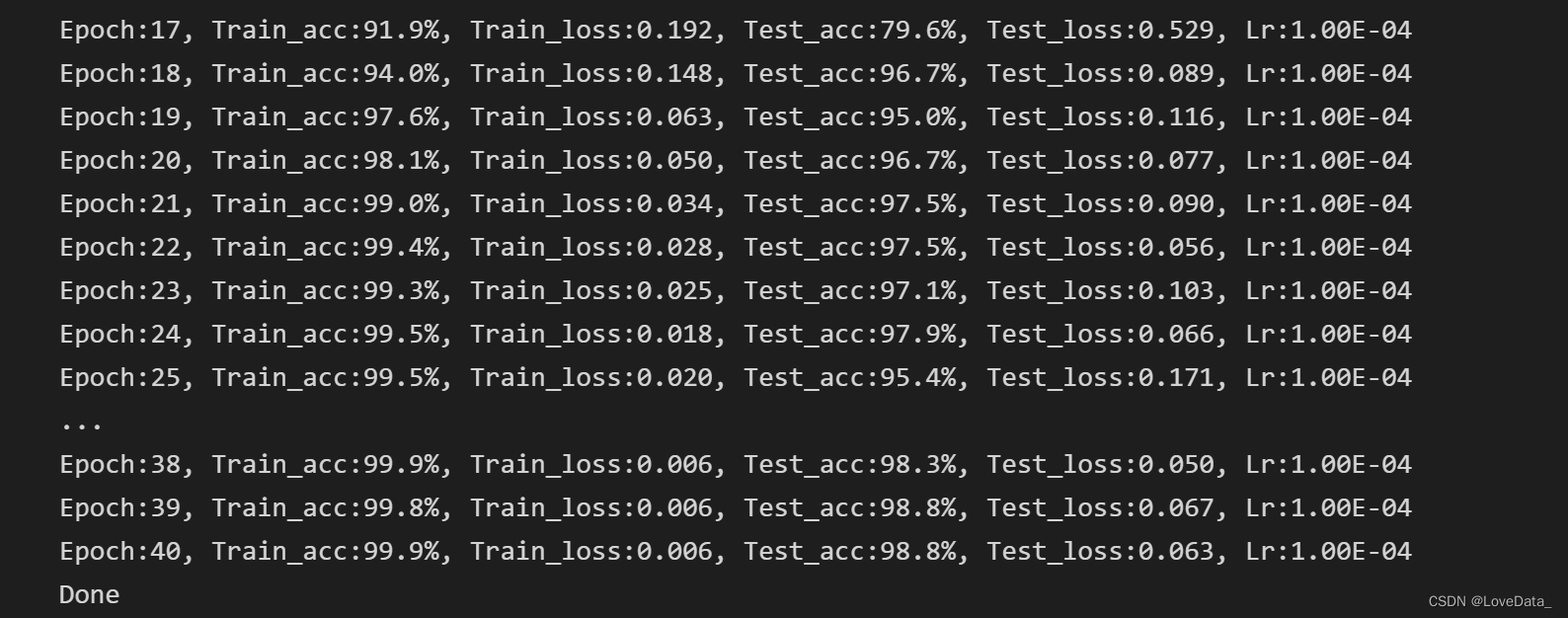
策略:发现在flatten层的时候参数量出现了很大的上升,尝试在该层之前加入1x1卷积,把维度降低成256*7*7
改变后模型准确率并未降低,验证集上准确率达98.8%
















 4万+
4万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











