







 本文详细介绍了Yolov56.0版本中的c3模块,区分了backbone和neck部分的c3,并探讨了bottleneck1和bottleneck2的区别。c3通过一分为二的处理方式,减少计算量并可能提高特征提取效果。
本文详细介绍了Yolov56.0版本中的c3模块,区分了backbone和neck部分的c3,并探讨了bottleneck1和bottleneck2的区别。c3通过一分为二的处理方式,减少计算量并可能提高特征提取效果。
上一篇讲完了conv模块,本篇来介绍一下c3模块
c3:
以yolov5的6.0版本来说,c3分为两种,①backbone部分里面的c3和②neck部分里面的c3
两种的区别主要在于内部的bottleneck模块的类型不同(前者是bottleneck1,后者是bottleneck2)
因此在这里不得不先把两个bottleneck讲一下:
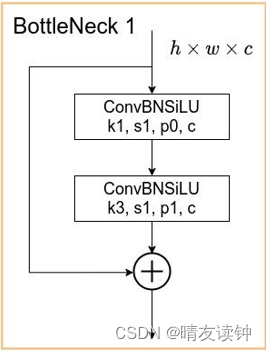
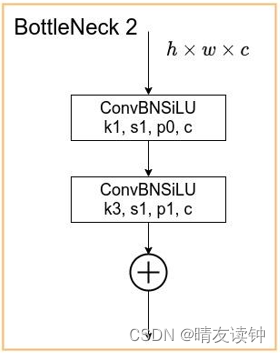
如上两图就是yolov5的6.0版本存在的两种bottleneck,第一种只出现在backbone部分,第二种只出现在neck部分,都由两个conv模块组成,先是k1,s1,p0的conv,然后k3,s1,p1的conv
区别在于最终相加时,bottleneck1会把进行两次conv前的残差结构也加上,而bottleneck2则不会
两种c3除bottleneck之外在个人理解上来看是大差不差的,来看看它的组成——
组成:
3个参数均为k1,s1,p0的的conv模块,1个bottleneck模块(分1和2两种),1个concat模块
运作机制:
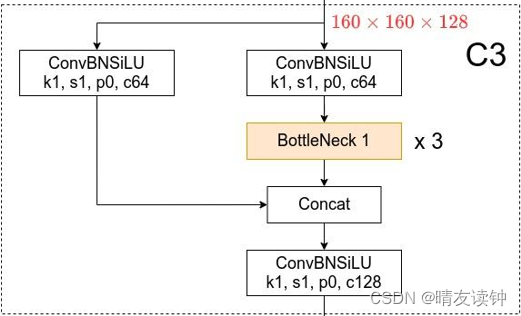
(上图是backbone部分深度为2的c3模块)c3模块会将卷积神经网络中上一层模块输出过来的特征图作为自身的输入,首先把特征图分为两部分,左半部分只经过一个conv模块就等着右半部分处理完后进行融合,右半部分则先经过一个相同的conv模块,然后经过n个bottleneck,最终和左半部分进行融合,融合后再进行一个conv模块就输出特征图,整个过程总结下来就是一分为二走两路,左路不做过多操作,右路经过多个bottleneck模块不断降维升维提取特征,然后又合二为一,再经过一个conv模块后升维输出,因此经过c3模块的特征图,只做特征提取,其长、宽和通道数都是不变的!
关于为什么c3要采取将特征图一分为2来处理,个人猜想首先主要是能够大大减少计算量,因为只取其中一半的特征图走右半部分的conv和bottleneck,其次这种处理方式保留了左半部分没有经过多次升维降维操作(即bottleneck发挥的作用)的特征图,可能有利于提取更多更详细的特征,当然这只是我自己的猜想,具体原因肯定是作者做了多次实验,发现这种方式能够让结果更精确所以采用这种方式,实验结果大于一切

















 20万+
20万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









