







引言
现在的模型BERT、RoBERTa、T5存在的问题:句子级的表示能力并没有得到充分的发展,这限制了它们进行密集检索的潜力。
因此产生了开发专门针对检索任务的预训练模型的兴趣。
- 自对比学习:第一种策略是利用自对比学习方法,其中模型被训练以区分正样本和通过数据增强得到的样本。这种方法的一个关键优势是能够通过学习区分相似但不相同的样本来提高模型的区分能力。然而,这种方法的效果严重依赖于数据增强的质量;此外,它通常需要大量的负样本,这可能使得训练过程变得更加复杂和资源密集。
- 自编码:第二种策略依赖于自编码方法,这种方法不受数据增强和负采样限制的影响。自编码策略通过编码-解码工作流来实现,模型学习将输入编码成一个紧凑的表示,然后尝试从这个表示中恢复原始输入。当前的研究工作在于如何设计这一编码-解码流程,以便为面向检索的预训练开发更有效的自编码框架。
现有的方法采用了各种重构任务,如掩码语言模型(MLM)和自回归任务,这些方法在原始句子的恢复方式和训练损失的构建上有很大的区别。例如,自回归依赖于embedding和前缀进行重构,而MLM则利用embedding和掩码上下文。自回归从整个输入token中导出其训练损失,而传统的MLM只从掩码位置(占输入词元的15%)学习。理想情况下,我们期望解码操作足够具有挑战性,这将迫使编码器充分捕获输入的语义信息以确保重构质量。此外,我们也期望实现高数据效率,意味着输入数据可以被充分利用于预训练任务。
自对比学习方法受数据增强质量的限制,而自编码方法虽然克服了这一限制,但如何设计更有效的编码-解码框架仍是一个待解决的问题。
基于自编码的预训练对于两个因素至关重要:
1)重构任务必须对编码质量提出足够的要求;
2)需要充分利用预训练数据。
为了优化这两个方面,提出了RetroMAE模型,该模型通过特定的设计来满足这两个关键因素的要求。
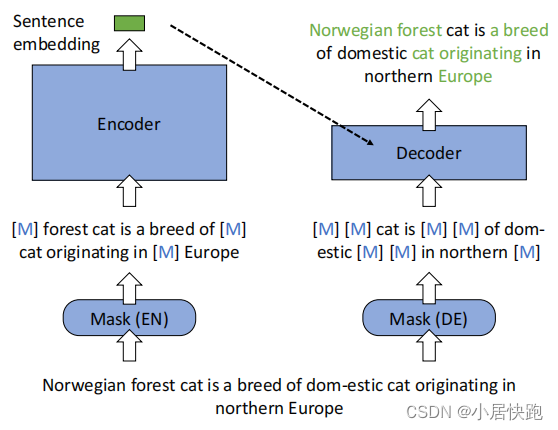
- **创新的MAE工作流:**输入句子在编码器和解码器中通过不同的掩码(mask)被“污染”。sentence
embedding是由编码器处理掩码输入后生成的;然后,基于sentence
embedding和解码器的掩码输入通过MLM恢复原始句子。 - **不对称模型结构:**采用全尺寸BERT类似的transformer作为编码器,和一个单层transformer作为解码器。
- **不对称掩码比例:**编码器采用中等掩码比例(15∼30%),而解码器采用较高的掩码比例(50∼70%)。
RetroMAE模型的设计对于预训练是有益的,主要基于以下几个原因:
- 对编码质量的更高要求:RetroMAE通过对输入进行更激进的掩码处理(相比于传统的掩码语言模型(MLM),后者通常只掩码输入的15%),使得解码过程更加依赖于编码器生成的句子嵌入。在传统的自回归解码过程中,解码器可能会依赖于已经生成的前缀信息来预测下一个词,而RetroMAE通过大量掩码输入,迫使模型更多地依赖于编码器捕获的深层语义信息,从而提高编码的质量和深度。
- 确保训练信号完全来自输入句子:在传统的MLM风格的预训练方法中,训练信号可能只来自于被掩码的15%的输入词。而RetroMAE能够从大多数输入中提取训练信号,因为它对输入进行了更广泛的掩码处理。这意味着模型有更多机会从整个输入句子中学习,而不仅仅是一小部分。
- 增强的解码过程:考虑到解码器仅包含单层,RetroMAE采用了基于两流注意力(two-stream attention)和位置特定的注意力掩码(position-specific attention mask)的增强解码策略。这些技术帮助模型能够利用100%的token进行重构,并且每个token可以为其重构采样一个独特的上下文。这样的设计不仅提高了解码的效率,还增强了模型对于输入句子的理解能力。
两流注意力(Two-Stream Attention)
两流注意力是一种特殊的注意力机制,最初在XLNet中被提出,用于解决自回归语言模型的特定问题。它设计了两种不同的信息流——内容流和查询流:
内容流用于表示位置信息,即在给定上下文中每个词的位置。 查询流则专注于预测的目标词本身,不包含目标词的位置信息。
通过这种设计ÿ
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 786
786

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









