






来源:https://www.bilibili.com/video/BV1Bb4y1L7FT?p=1&vd_source=f66cebc7ed6819c67fca9b4fa3785d39
文章目录
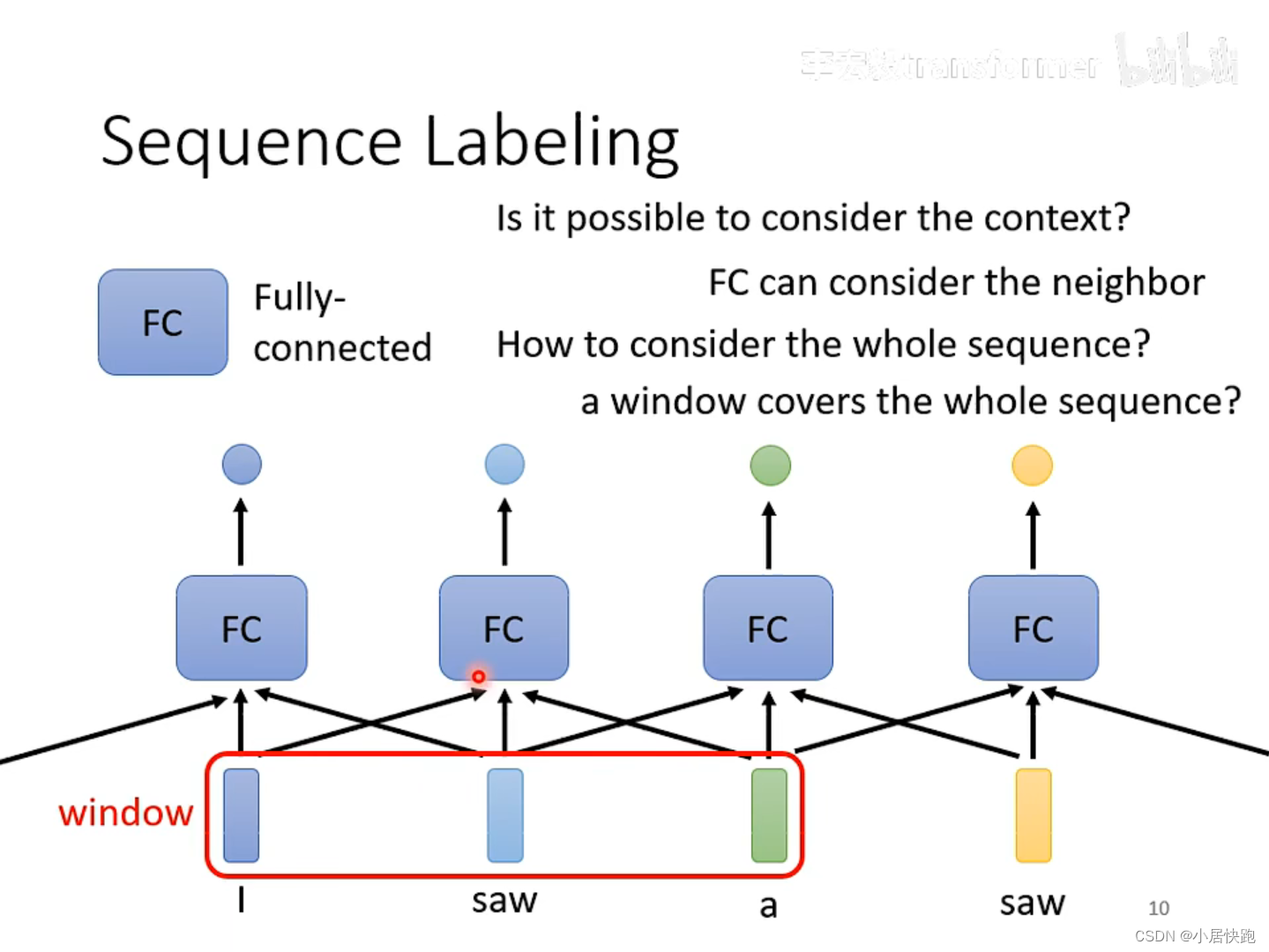
self-attention要解决的问题:输入的sequence是变长的、长度不等。
引言
如何解决输入同样的saw,第一个输出v.第二个输出n.?
使用FC可以考虑上下文的资讯。
如何考虑一整个sequence的资讯呢?
把Windows开到sequence中最大的长度。
self-attention
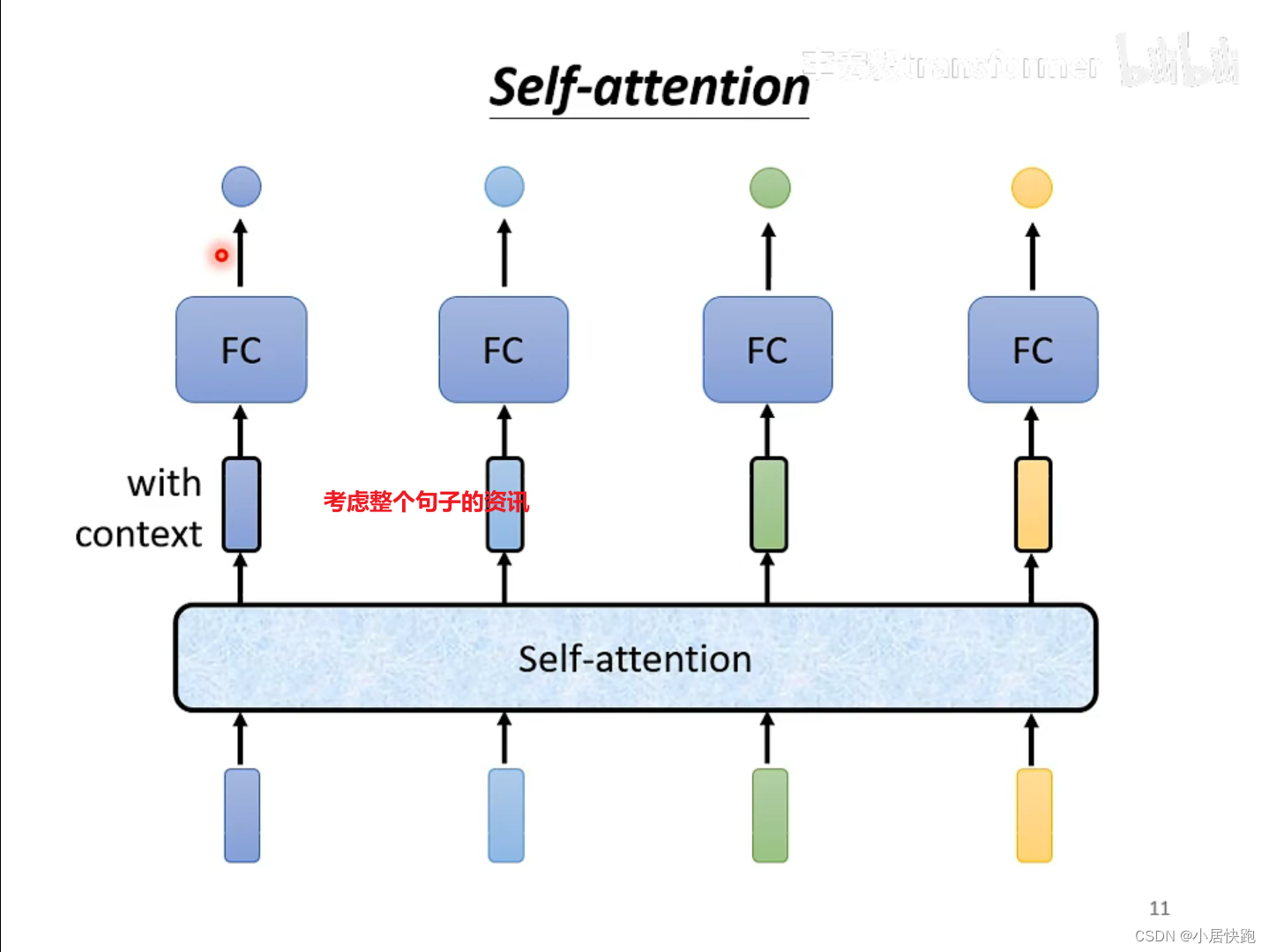
可以将self-attention与FC交替使用:
self-attention处理整个句子的资讯
FC专注于处理某一个位置的资讯、

运作机制
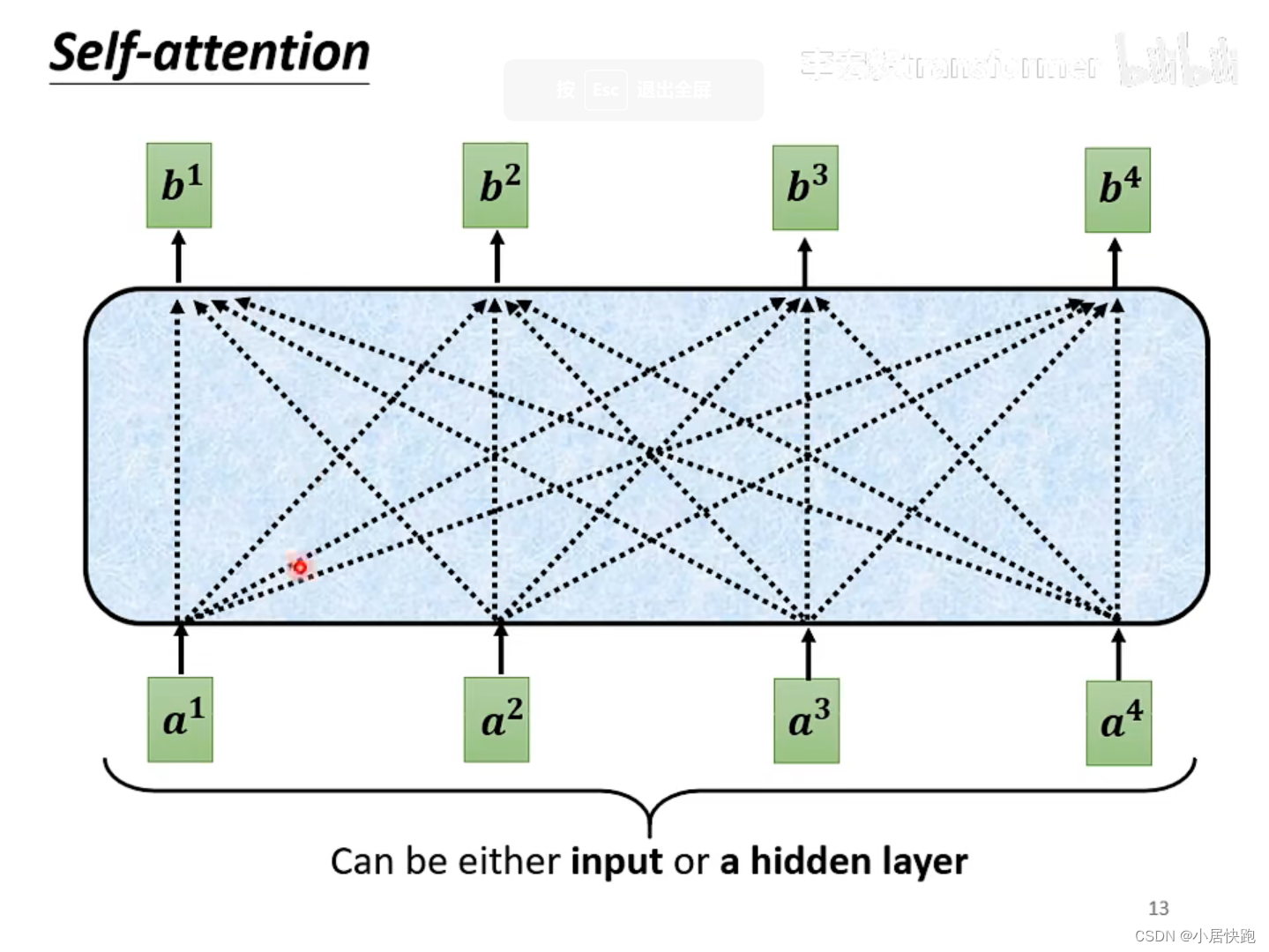
b1是如何产生的
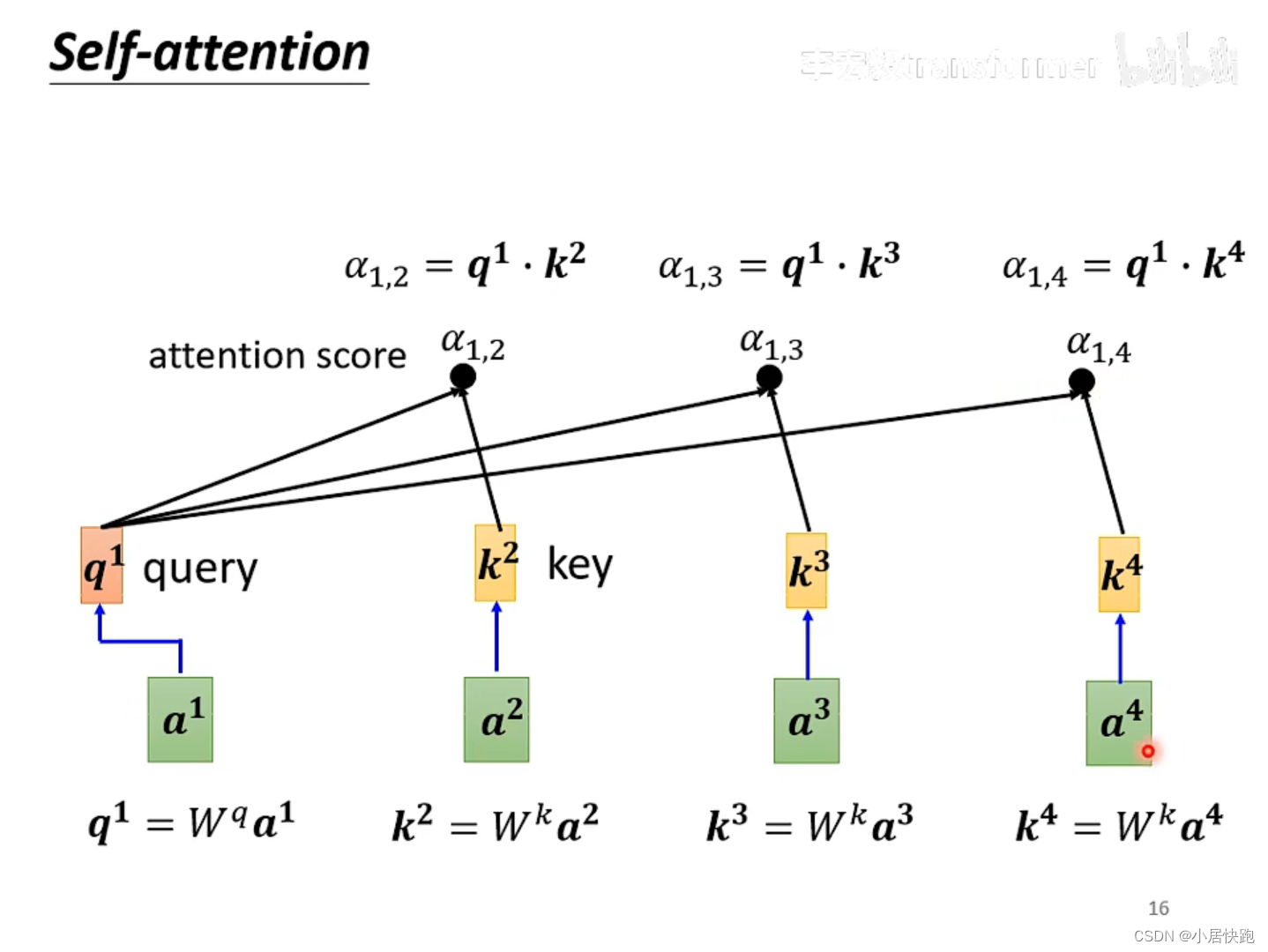
1、计算出attention score
α
\alpha
α:在这个长长的sequence里找出和a1有关联的vector,每个向量与a1的关联性用数值
α
\alpha
α表示。
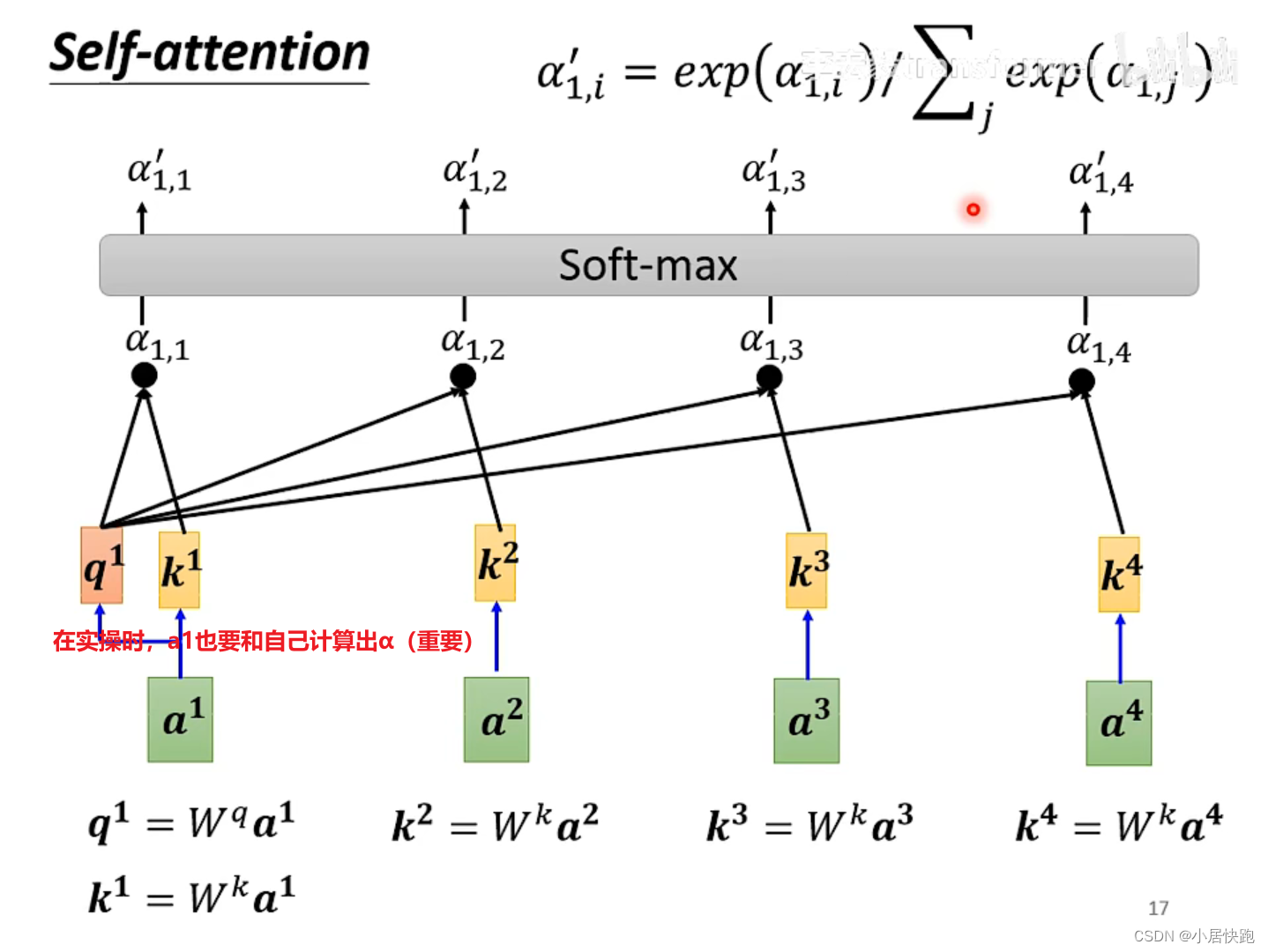
2、根据attention score抽取sequence里的重要资讯,即可计算出b1
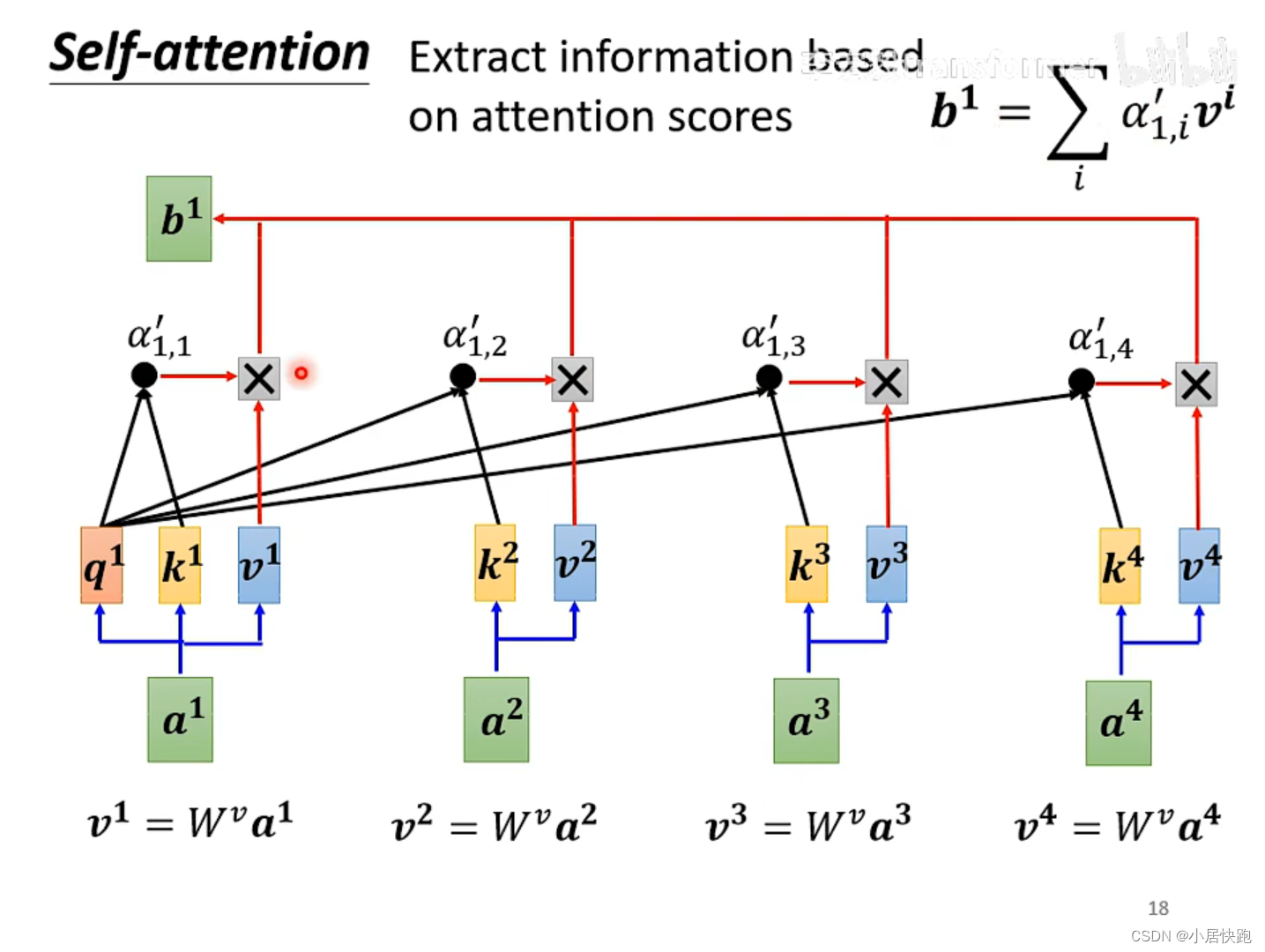
注:b1-b4是同时被产生的
怎么求关联性数值 α \alpha α
两种方法:

最常用的是向量点积法,也是用在transformer里的方法。
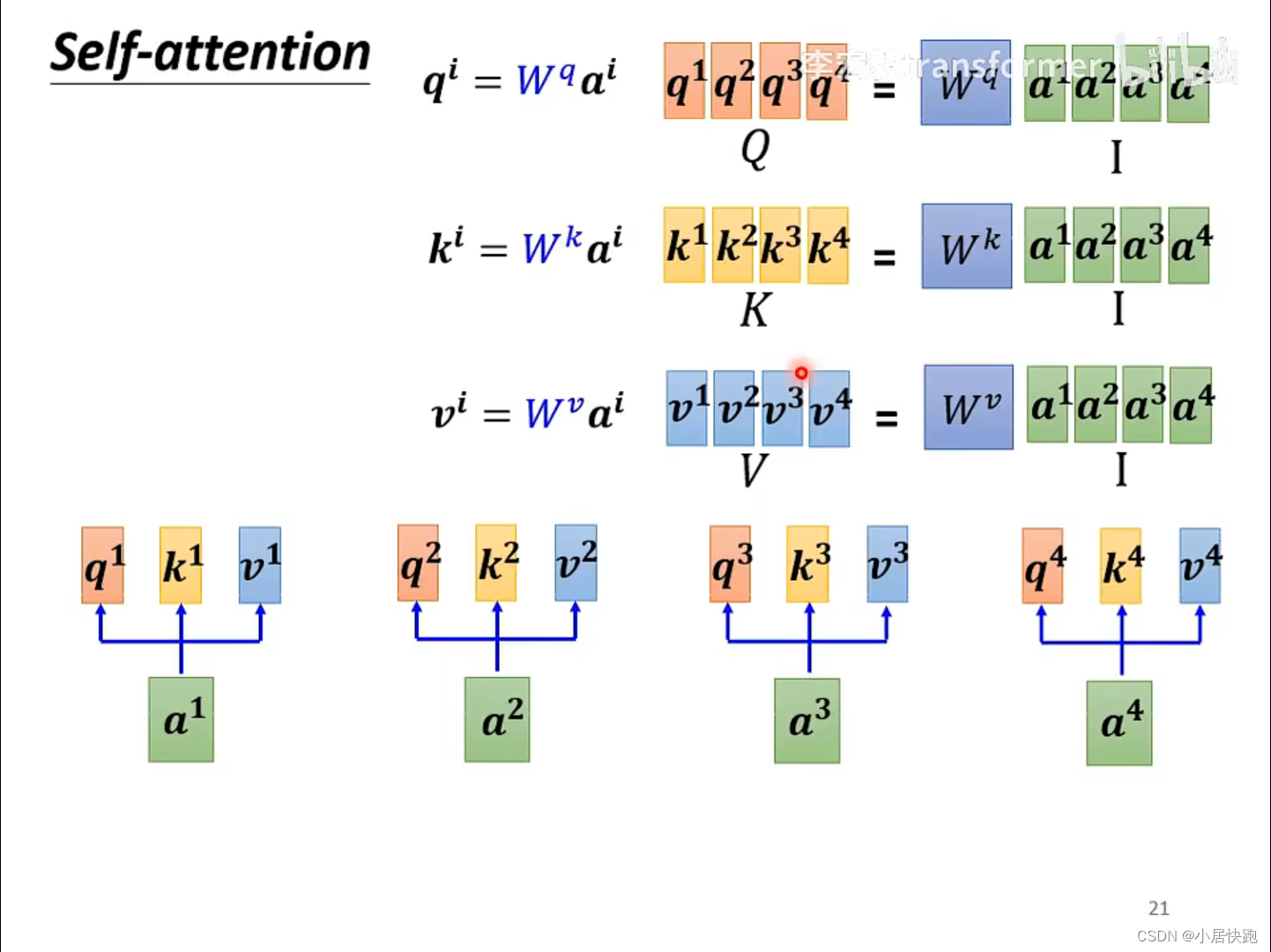
从矩阵乘法的角度再来一次
从A得到Q、K、V
从Q、K得到 α \alpha α矩阵
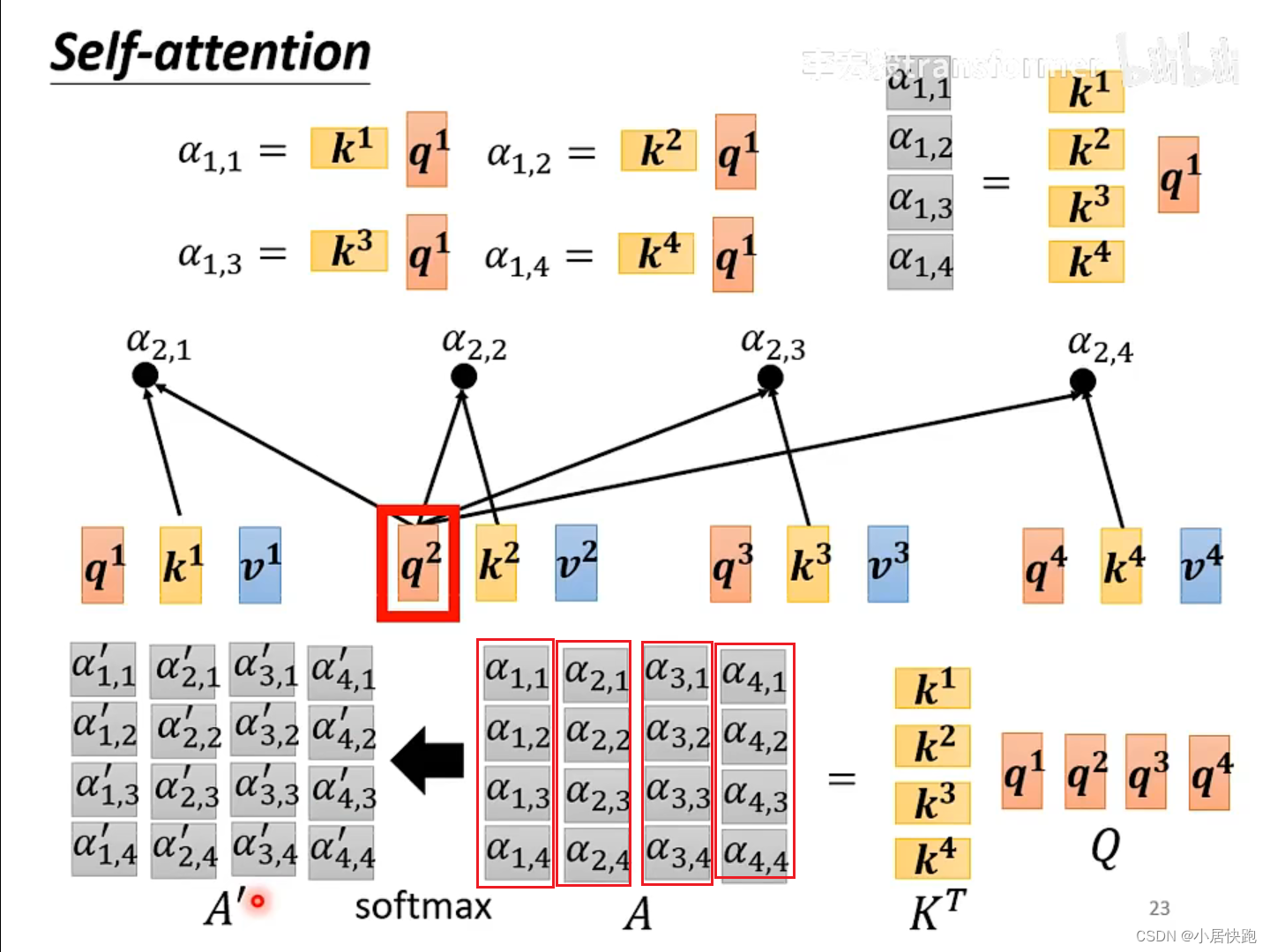
由V和A’得到b1-b4

总结:从I到O就是在做self-attention

在Transformer模型中,Self-Attention的计算涉及到几个关键步骤,这些步骤主要包括计算Query、Key、Value,计算注意力分数,应用softmax进行归一化,以及计算加权的Value。这里提供一个更加详细的计算过程:
假设有一个输入序列的嵌入表示(X),其中包含了(n)个元素,每个元素是一个 d model d_{\text{model}} dmodel维的向量。首先,需要通过三个不同的线性映射(权重矩阵)来计算Query矩阵(Q)、Key矩阵(K)和Value矩阵(V):
Q = X W Q , K = X W K , V = X W V Q = XW^Q, \quad K = XW^K, \quad V = XW^V Q=XWQ,K=XWK,V=XWV
其中, W Q W^Q WQ、 W K W^K WK、 W V W^V WV分别是Query、Key、Value的权重矩阵,它们的维度分别是 d model × d k d_{\text{model}} \times d_k dmodel×dk、 d model × d k d_{\text{model}} \times d_k dmodel×dk和 d model × d v d_{\text{model}} \times d_v dmodel×dv。
接下来,计算注意力分数(也就是Query和Key的点积),并通过softmax进行归一化,以得到注意力权重:
A t t e n t i o n ( Q , K , V ) = softmax ( Q K T d k ) V Attention(Q, K, V) = \text{softmax}\left(\frac{QK^T}{\sqrt{d_k}}\right)V Attention(Q,K,V)=softmax(dkQKT)V
这里, Q K T d k \frac{QK^T}{\sqrt{d_k}} dkQKT计算了Query和Key的点积,并通过 d k \sqrt{d_k} dk进行了缩放,目的是为了控制点积的大小,防止在进行softmax时出现梯度消失或爆炸的问题。softmax函数确保了每一行(对应于每个Query)的所有元素加起来等于1,这样每个元素的输出就是所有Value的加权和,权重由相应的注意力分数决定。
最后,将得到的加权和作为Self-Attention层的输出,可以输入到后续的层(比如前馈全连接层)进行进一步的处理。
需要注意的是,在实际的Transformer模型中,通常使用多头注意力(Multi-head Attention)机制,即上述过程会并行执行多次(每次使用不同的 W Q W^Q WQ、 W K W^K WK、 W V W^V WV权重矩阵),然后将所有头的输出拼接起来,通过另一个线性映射得到最终的输出。这样可以让模型同时从不同的表示子空间中学习信息。
Muti-head Self-attention
几个head,是一个需要调的超参。
为什么要用Muti-head?
使用不同的q代表不同种类的相关性。

多头注意力(Multi-Head Attention)机制是Transformer模型中的一个关键创新,它允许模型同时从不同的表示子空间学习信息。这一机制通过并行地执行多次Self-Attention操作来实现,每个操作被称为一个“头”(Head)。下面是多头注意力的计算过程:
-
线性投影:对于输入序列的嵌入表示(X),首先通过(h)组不同的线性变换(权重矩阵)来分别计算每个头的Query矩阵 Q i Q_i Qi、Key矩阵 K i K_i Ki和Value矩阵 V i V_i Vi:
Q i = X W i Q , K i = X W i K , V i = X W i V Q_i = XW_i^Q, \quad K_i = XW_i^K, \quad V_i = XW_i^V Qi=XWiQ,Ki=XWiK,Vi=XWiV
其中,(i = 1, 2, …, h)表示头的索引, W i Q W_i^Q WiQ、 W i K W_i^K WiK、 W i V W_i^V WiV是对应于第(i)个头的权重矩阵。
-
计算注意力:对每个头,分别计算Self-Attention。注意力分数通过Query和Key的点积,然后通过softmax进行归一化得到:
A t t e n t i o n i ( Q i , K i , V i ) = softmax ( Q i K i T d k ) V i Attention_i(Q_i, K_i, V_i) = \text{softmax}\left(\frac{Q_iK_i^T}{\sqrt{d_k}}\right)V_i Attentioni(Qi,Ki,Vi)=softmax(dkQiKiT)Vi
这里, d k d_k dk是Key向量的维度,用于缩放点积的结果。
-
拼接多头输出:将所有头计算得到的注意力输出拼接起来,形成一个较大的矩阵:
C o n c a t ( A t t e n t i o n 1 , A t t e n t i o n 2 , . . . , A t t e n t i o n h ) Concat(Attention_1, Attention_2, ..., Attention_h) Concat(Attention1,Attention2,...,Attentionh)
-
线性映射:最后,将拼接后的矩阵通过另一个线性变换(权重矩阵)来获得最终的多头注意力输出:
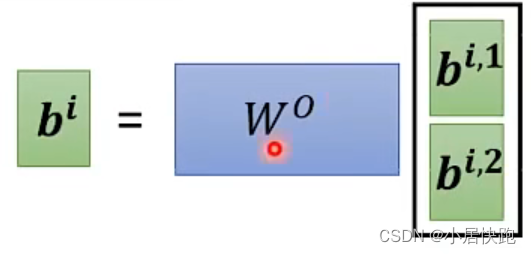
M u l t i H e a d A t t e n t i o n ( X ) = C o n c a t ( A t t e n t i o n 1 , A t t e n t i o n 2 , . . . , A t t e n t i o n h ) W O MultiHeadAttention(X) = Concat(Attention_1, Attention_2, ..., Attention_h)W^O MultiHeadAttention(X)=Concat(Attention1,Attention2,...,Attentionh)WO
其中,(W^O)是用于线性映射的权重矩阵。
多头注意力机制通过这种方式能够让模型在不同的表示子空间中捕捉到序列的不同特征,从而提高了模型处理信息的能力。在Transformer模型中,多头注意力不仅被用在编码器(Encoder)和解码器(Decoder)的Self-Attention层,也被用在编码器和解码器之间的注意力层中,以帮助解码器更好地利用编码器的信息。
位置编码

对于位置(pos)(序列中的索引)和维度(i)(向量中的位置),位置编码(PE(pos, i))的计算公式为:
P E ( p o s , 2 i ) = sin ( p o s 1000 0 2 i / d model ) PE(pos, 2i) = \sin\left(\frac{pos}{10000^{2i/d_{\text{model}}}}\right) PE(pos,2i)=sin(100002i/dmodelpos)
P E ( p o s , 2 i + 1 ) = cos ( p o s 1000 0 2 i / d model ) PE(pos, 2i+1) = \cos\left(\frac{pos}{10000^{2i/d_{\text{model}}}}\right) PE(pos,2i+1)=cos(100002i/dmodelpos)
其中:
- (pos)是元素在序列中的位置。
- (i)是位置向量中的维度索引。
- d model d_{\text{model}} dmodel是模型中嵌入的维度。
位置编码举例:
假设我们想要为一个长度为 seq_length = 4 的序列生成位置编码,并且我们想要的编码维度是 d_model = 8。
初始化位置和维度索引矩阵:
位置矩阵 position (shape: [seq_length, 1]):
[[0],
[1],
[2],
[3]]
维度索引矩阵 i (shape: [1, d_model]):
[[0, 1, 2, 3, 4, 5, 6, 7]]
计算角速率:
使用公式 angle_rates = 1 / (10000^(2 * (i//2) / d_model)) 计算 angle_rates:
angle_rates = 1 / (10000^(2 * ([0, 1, 2, 3, 4, 5, 6, 7]//2) / 8))
angle_rates = 1 / (10000^(2 * [0, 0, 1, 1, 2, 2, 3, 3] / 8))
angle_rates = 1 / (10000^(0, 0, 0.25, 0.25, 0.5, 0.5, 0.75, 0.75))
假设我们计算后得到如下的 angle_rates (shape: [1, d_model]):
[[1.0, 1.0, 0.1778, 0.1778, 0.0316, 0.0316, 0.0056, 0.0056]]
计算角度值:
将 position 矩阵与 angle_rates 矩阵相乘得到 angle_rads:
angle_rads = position * angle_rates
假设我们得到如下的 angle_rads (shape: [seq_length, d_model]):
[[0.0000, 0.0000, 0.0000, 0.0000, 0.0000, 0.0000, 0.0000, 0.0000],
[1.0000, 1.0000, 0.1778, 0.1778, 0.0316, 0.0316, 0.0056, 0.0056],
[2.0000, 2.0000, 0.3556, 0.3556, 0.0632, 0.0632, 0.0112, 0.0112],
[3.0000, 3.0000, 0.5334, 0.5334, 0.0948, 0.0948, 0.0168, 0.0168]]
应用正弦和余弦函数:
对偶数索引应用正弦函数,对奇数索引应用余弦函数:
PE(pos, 2i) = sin(angle_rads[:, 2i])
PE(pos, 2i+1) = cos(angle_rads[:, 2i+1])
假设我们得到如下的位置编码 position_encoding (shape: [seq_length, d_model]):
[[0.0000, 1.0000, 0.0000, 1.0000, 0.0000, 1.0000, 0.0000, 1.0000],
[0.8415, 0.5403, 0.1768, 0.9843, 0.0316, 0.9995, 0.0056, 0.9999],
[0.9093, -0.4161, 0.3484, 0.9373, 0.0629, 0.9980, 0.0112, 0.9997],
[0.1411, -0.9900, 0.5121, 0.8590, 0.0941, 0.9955, 0.0168, 0.9994]]















 603
603











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









