







先自我介绍一下,小编浙江大学毕业,去过华为、字节跳动等大厂,目前在阿里
深知大多数程序员,想要提升技能,往往是自己摸索成长,但自己不成体系的自学效果低效又漫长,而且极易碰到天花板技术停滞不前!
因此收集整理了一份《2024年最新Linux运维全套学习资料》,初衷也很简单,就是希望能够帮助到想自学提升又不知道该从何学起的朋友。

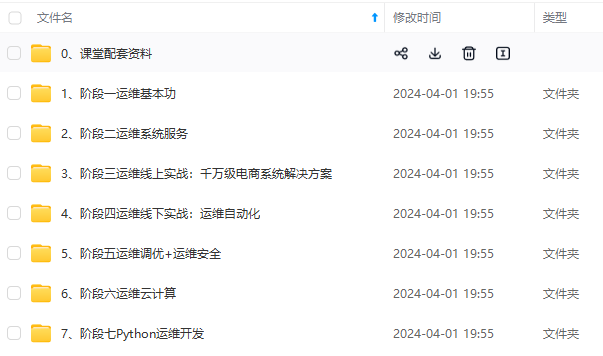


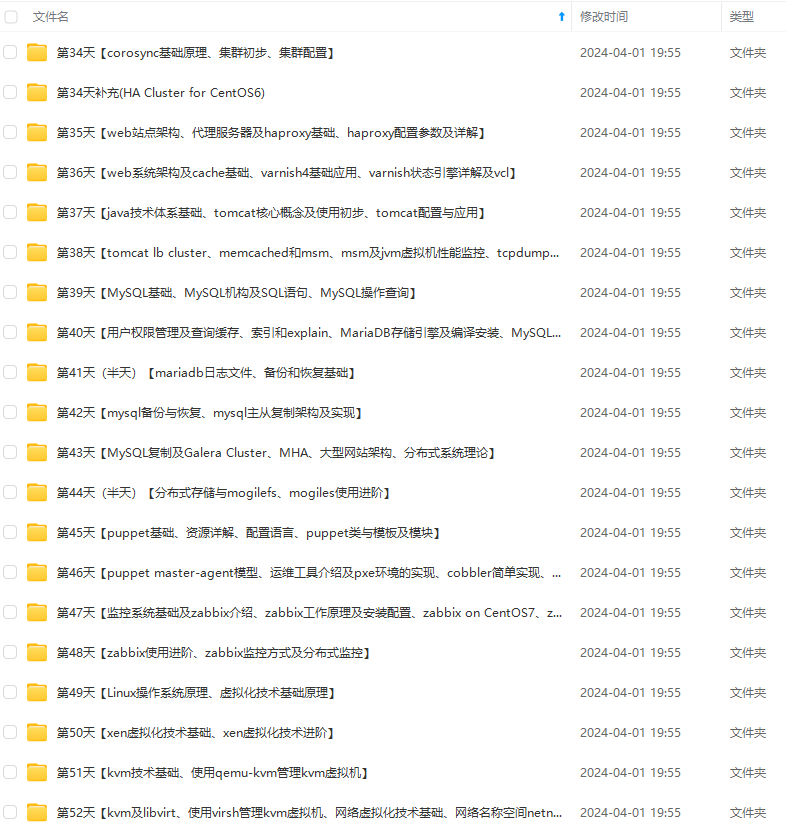
既有适合小白学习的零基础资料,也有适合3年以上经验的小伙伴深入学习提升的进阶课程,涵盖了95%以上运维知识点,真正体系化!
由于文件比较多,这里只是将部分目录截图出来,全套包含大厂面经、学习笔记、源码讲义、实战项目、大纲路线、讲解视频,并且后续会持续更新
程序员必备:常见算法与应用综述
算法是计算机科学的核心,是解决问题的关键。在程序员的日常工作中,算法无处不在。本文将以“程序员常用的几种算法”为主题,从多个维度介绍程序员常用的算法,并分析其适用场景、优缺点以及发展趋势。
排序算法
排序算法是程序员最常用的算法之一,主要用于对一组数据进行排序。以下是一些常见的排序算法:
- 冒泡排序(Bubble Sort)
冒泡排序是一种简单的排序算法,通过重复交换相邻元素的位置,直到没有需要交换的元素为止。其时间复杂度为O(n^2),空间复杂度为O(1)。冒泡排序适用于小规模数据排序,但不适合大规模数据排序。 - 选择排序(Selection Sort)
选择排序是一种简单的排序算法,通过重复选择剩余元素中的最小(或最大)元素,放到已排序序列的末尾。其时间复杂度为O(n^2),空间复杂度为O(1)。选择排序不适合大规模数据排序。 - 插入排序(Insertion Sort)
插入排序是一种简单的排序算法,通过将未排序序列中的元素插入到已排序序列的正确位置,直到整个序列排序完成。其时间复杂度为O(n^2),空间复杂度为O(1)。插入排序适用于小规模数据排序,但不适合大规模数据排序。 - 快速排序(Quick Sort)
快速排序是一种高效的排序算法,通过选择一个基准元素,将序列分为两个子序列,一个比基准元素小,一个比基准元素大,然后递归地对这两个子序列进行快速排序。其时间复杂度平均为O(n log n),空间复杂度为O(log n)。快速排序适用于大规模数据排序。 - 归并排序(Merge Sort)
归并排序是一种高效的排序算法,通过将序列分为两个子序列,对这两个子序列进行归并排序,然后将排序好的两个子序列合并为一个序列。其时间复杂度为O(n log n),空间复杂度为O(n)。归并排序适用于大规模数据排序。 - 堆排序(Heap Sort)
堆排序是一种高效的排序算法,通过将序列构建为一个堆,然后将堆顶元素与堆底元素交换,重复这个过程直到堆为空。其时间复杂度为O(n log n),空间复杂度为O(1)。堆排序适用于大规模数据排序。
搜索算法
搜索算法是程序员用于在数据集合中查找特定元素的算法。以下是一些常见的搜索算法:
- 线性搜索(Linear Search)
线性搜索是一种简单的搜索算法,通过遍历整个数据集合,直到找到目标元素或遍历完整个集合。其时间复杂度为O(n),空间复杂度为O(1)。线性搜索适用于小规模数据搜索,但不适合大规模数据搜索。 - 二分搜索(Binary Search)
二分搜索是一种高效的搜索算法,通过将数据集合分为两个子集合,然后判断目标元素在哪个子集合中,重复这个过程直到找到目标元素或确定目标元素不存在。其时间复杂度为O(log n),空间复杂度为O(1)。二分搜索适用于有序数据集合搜索。 - 哈希搜索(Hash-based Search)
哈希搜索是一种高效的搜索算法,通过计算目标元素的哈希值,然后在哈希表中查找对应的元素。其时间复杂度为O(1),空间复杂度为O(n)。哈希搜索适用于大规模数据搜索,但需要解决哈希冲突的问题。
字符串处理算法
字符串处理算法是程序员用于处理字符串的算法。以下是一些常见的字符串处理算法:
- KMP算法(Knuth-Morris-Pratt)
KMP算法是一种高效的字符串匹配算法,通过计算部分匹配表(PMT),然后使用PMT来判断模式串是否在文本串中。其时间复杂度为O(n),空间复杂度为O(n)。KMP算法适用于大规模文本匹配。 - 后缀数组(Suffix Array)
后缀数组是一种高效的字符串排序算法,通过将字符串的所有后缀进行排序,然后存储排序后的后缀数组。其时间复杂度为O(n log^2 n),空间复杂度为O(n)。后缀数组适用于大规模字符串排序。 - AC自动机(Aho-Corasick Automaton)
AC自动机是一种高效的字符串匹配算法,通过构建一个自动机来匹配字符串中的模式。其时间复杂度为O(n),空间复杂度为O(n)。AC自动机适用于大规模字符串匹配。
图算法
图算法是程序员用于解决图论问题的算法。以下是一些常见的图算法:
- 深度优先搜索(DFS)
深度优先搜索是一种用于遍历或搜索图的算法,通过从一个节点开始,沿着一条路径深入到不能再深入为止,然后回溯到上一个节点,继续沿着另一条路径深入。其时间复杂度为O(V+E),空间复杂度为O(V),其中V是节点数,E是边数。深度优先搜索适用于各种图论问题。 - 广度优先搜索(BFS)
广度优先搜索是一种用于遍历或搜索图的算法,通过从一个节点开始,沿着一条路径扩展到其所有邻接节点,然后再对这些邻接节点进行扩展。其时间复杂度为O(V+E),空间复杂度为O(V),其中V是节点数,E是边数。广度优先搜索适用于各种图论问题。 - 最短路径算法(如Dijkstra、Bellman-Ford、Floyd-Warshall)
最短路径算法是用于找出图中两个节点之间的最短路径。Dijkstra算法适用于有向无环图(DAG),Bellman-Ford算法适用于有向图,Floyd-Warshall算法适用于无向图。这些算法的时间复杂度分别为O(V2)、O(V*E)、O(V3)。最短路径算法适用于各种路径规划问题。 - 最小生成树算法(如Prim、Kruskal)
最小生成树算法是用于找出图中的最小生成树,即包含图中所有节点的最小边权连通子图。Prim算法适用于加权无向图,Kruskal算法适用于加权有向图。这些算法的时间复杂度分别为O(V^2)、O(E*log V)。最小生成树算法适用于各种网络设计问题。
动态规划算法
动态规划算法是程序员用于解决优化问题的算法。以下是一些常见的动态规划算法:
- 背包问题(Knapsack Problem)
背包问题是动态规划的经典问题,用于找出如何在不超过背包重量限制的情况下,最大化背包中物品的价值。动态规划算法可以解决0-1背包问题、完全背包问题和多重背包问题。其时间复杂度为O(n*W),空间复杂度为O(W),其中n是物品数,W是背包重量。背包问题适用于资源分配和优化问题。 - 最长公共子序列(LCS)
最长公共子序列是用于找出两个序列中的最长公共子序列。动态规划算法可以解决该问题,其时间复杂度为O(nm),空间复杂度为O(nm),其中n和m分别是两个序列的长度。最长公共子序列适用于文本编辑和基因序列分析。 - 最长递增子序列(LIS)
最长递增子序列是用于找出一个序列中的最长递增子序列。动态规划算法可以解决该问题,其时间复杂度为O(n^2),空间复杂度为O(n)。最长递增子序列适用于序列排列和游戏理论。
数学算法
先自我介绍一下,小编浙江大学毕业,去过华为、字节跳动等大厂,目前在阿里
深知大多数程序员,想要提升技能,往往是自己摸索成长,但自己不成体系的自学效果低效又漫长,而且极易碰到天花板技术停滞不前!
因此收集整理了一份《2024年最新Linux运维全套学习资料》,初衷也很简单,就是希望能够帮助到想自学提升又不知道该从何学起的朋友。


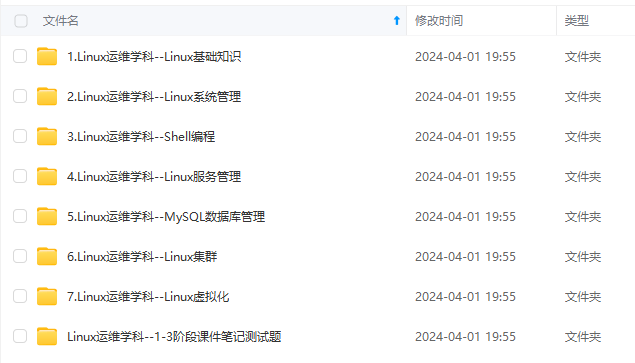


既有适合小白学习的零基础资料,也有适合3年以上经验的小伙伴深入学习提升的进阶课程,涵盖了95%以上运维知识点,真正体系化!
由于文件比较多,这里只是将部分目录截图出来,全套包含大厂面经、学习笔记、源码讲义、实战项目、大纲路线、讲解视频,并且后续会持续更新
将部分目录截图出来,全套包含大厂面经、学习笔记、源码讲义、实战项目、大纲路线、讲解视频,并且后续会持续更新**















 7844
7844











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









