







继续记录机器学习中关于模型的学习,若有不足之处,还望指正。
目录
2、逻辑回归的模型:p是因变量Y=1的概率,X1、X2、X3.......XK是自变量。
模型及算法
机器学习的算法有:
(1)有监督学习:朴素贝叶斯、线性回归、决策树、神经网络、逻辑回归、支持向量机、集成算法等。
(2)无监督学习:聚类分析、关联规则、序列模式。
【注】在学习模型过程中要抓住核心所在,毕竟它是不变的。
五、逻辑回归
1、逻辑回归的简述?
逻辑回归模型的核心是找到一组最优的参数,使得预测值与实际值之间的误差最小。
| 模型及算法 | 作用 | 基本思想 | 优点 | 缺点 |
| 逻辑回归 | 用于预测二元变量的监督学习算法 | 通过对变量之间的线性关系进行建模,并使用逻辑函数将结果映射到0和1之间,来预测目标变量的值 | 预测结果是界于 0 和 1 之间的概率;可以适用于连续性和类别性自变量;容易使用和解释。适用于大多数数据集 | 对非线性关系的建模能力较弱,对异常值和噪声敏感 |
逻辑回归是用来解决分类问题用的,与线性回归不同的是:逻辑回归输出的不是具体的值,而是一个概率。
逻辑回归不同于线性回归,其既不假定自变量和因变量存在线性关系,也不假设因变量和误差变量是正态分布。
2、逻辑回归的模型:
p是因变量Y=1的概率,X1、X2、X3.......XK是自变量。
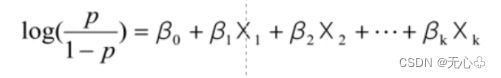
【注】逻辑回归和神经网络的一点不同之处就是,逻辑回归需要挑选字段。通常逻辑回归的字段选择方式有3种:前向递增法、后向递减法、逐步回归法。
在回归的方法中,反复将贡献度最大的变量放入模型中的方法是向前选择法。
3、逻辑回归与多重线性回归的练习与区别?
Logistic 回归与多重线性回归实际上有很多相同之处,最大的区别就在于它们的因变量不同,其他的基本都差不多。正是因为如此,这两种回归可以归于同一个家族,即广义线性模型。 这一家族中的模型形式基本上都差不多,不同的就是因变量不同。
x 如果是连续的,就是多重线性回归; x 如果是二项分布,就是 Logistic 回归; x 如果是 Poisson 分布,就是 Poisson 回归; x 如果是负二项分布,就是负二项回归。
4、代码部分
from sklearn.linear_model import LogisticRegression
from sklearn.model_selection import train_test_split
# 分割目标变量和特征变量
X = data.iloc[:, :-1].values
y = data.iloc[:, -1].values
# 划分训练集和测试集
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=42)
# 创建逻辑回归模型
log_reg = LogisticRegression()
# 训练模型
log_reg.fit(X_train, y_train)
# 预测结果
y_pred = log_reg.predict(X_test)
六、支持向量机(SVM)
1、支持向量机是什么?
支持向量机一种当下比较热门的线性/非线性分类方法,在机器学习中属于一个重要分类算法,用于数据的分类。
【注】它可以根据核函数不同的选择,则构建出不同的模型
| 模型及算法 | 作用 | 基本思想 | 优点 | 缺点 |
| 支持向量机 | 用于预测离散或连续变量的监督学习算法 | 通过将数据集映射到高维空间,并找到一个最优的超平面,使得不同类别的数据点之间的间隔最大化,来实现分类或回归 | 能够处理非线性关系和高维数据,具有较高的准确性和鲁棒性 | 对大规模数据集的处理能力较差,需要较长的训练时间和较大的存储空间 |
2、如何处理线性不可分数据?
要想处理线性不可分的数据,就需要把输入空间的数据对应到特征空间中。相当于进行了坐标变换,从而在更高的维度上使数据变成线性可分的。相对于神经网络来说,这个对应过程就类似于从输入层映射到隐藏层。在做完转换之后,在高维度特征空间中,支持向量机会找出一个最佳的线 性分割超平面来将这两个类别的数据值组分割开来,此分割超平面也可称为决策边界。

【注】(1)找到一个最大的边界将红蓝两点分隔开。
(2)留下在边界上的点或者最靠近边界的点,其余的点可以不要,也就是说:只留下关键点。
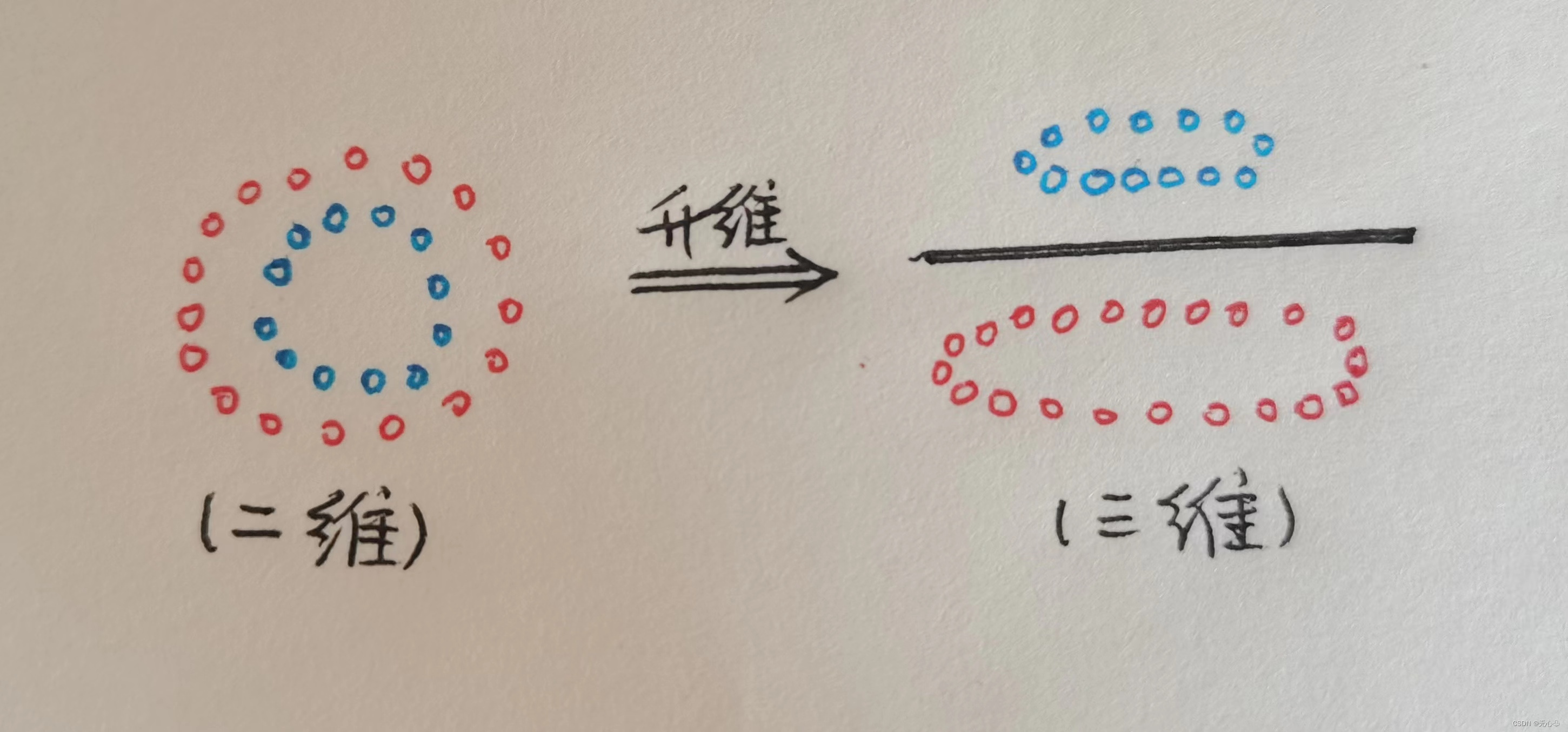
【注】当不好区分数据时,选择升维(低维难以区分时,可以用高维区分),同时也要考虑返还为低维。
3、支持向量机的特点?
除了可以选择不同的函数外,支持向量机另一个特点就是增加了对数据的选择。支持向量机会挑选一些关键的数据进行建模,这些关键的数据就是所谓的支持向量
优点:虽然SVM的训练时间可能会比较长,但是由于它能够建构复杂的非线性决策边界,所以SVM通常具有极高的正确率。另外,在进行建模的时候,SVM并不是使用全量数据,而是从数据中挑选出支持向量,再建立模型,所以SVM出现过度拟合的情况比较少。
4、代码部分
-
##导入数据 from sklearn.datasets import load_iris iris=load_iris() x1=iris.data y1=iris.target ##划分数据集 from sklearn.model_selection import train_test_split x_train,x_test,y_train,y_test=train_test_split(x1,y1,test_size=0.2,random_state=0) ##导入模型,调用逻辑回归LogisticRegression()函数 from sklearn.linear_model import LogisticRegression lr=LogisticRegression(penalty='l2',solver='newton-cg',multi_class='multinomial') #1.penalty: str类型,正则化项的选择。正则化主要有两种:l1和l2,默认为l2正则化。 #2.newton-cg:利用损失函数二阶导数矩阵即海森矩阵来迭代优化损失函数。 #3.”multinomial':直接采用多分类逻辑回归策略。 lr.fit(x_train,y_train)
总结
在逻辑回归和支持向量机的学习中,还包括各种各样的知识,要知道掌握核心,才能将每个模型贯彻起来,SVM实现多分类可以采用直接法或间接法。















 24万+
24万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









