






机器学习简述
1、机器学习也叫数据挖掘,就是从大量的数据中,提取 隐藏在其中的,事先不知道的,但潜在有用的信息的过程。
目标:建立决策模型
2、而在数据库的知识发现KDD的知识发现过程,有以下几个点:
(1)数据清理消除噪声和不一致的数据
这里面所说的数据包含:异常值、离群值、错误值
(2)数据集成多种数据源可以组合在一起
(3)数据选择从数据库中提取与分析任务相关的有用数据
【注】数据宁愿先多后少,也不要先少后多
3、数据挖掘项目生命周期分为6个阶段,它们分别是:
业务理解->数据理解->数据准备->建模->模型评估->模型发布
通俗来说就是:要做什么、需要什么数据以及对所收集的数据进行处理等等。
机器学习----KNN算法
1、KNN算法
(1)算法核心:物以类聚,人以群分。
(2)KNN是一类需要计算样本举例的模型。
【注】当特征值差距较大时,必须进行归一化或者标准化统一量纲。
(3)在训练数据集是只做少量的工作,而在进行分类时才做大量的运算。
2、极值正规化
V=原始值-该属性中的最小值/属性中的最大值-最小值
同一量纲下进行计算
【注】归一化将样本的特征值转化到同一量纲下,并把数据映射到[0,1]区间内。
3、数据归一化的目的就是使特征具有相同的度量尺度。
以葡萄酒数据为例,进行数据归一化:
# 计算最大值和最小值
x_max = data1.max()
x_min = data1.min()
# 进行(0,1)标准化
data2 = (data1 - x_min) / (x_max - x_min)
print(data2)数据预处理
1、通过各类技术手段对数据进行划分、清理、转换和缩减,此种方法叫做数据预处理。
2、在建模之前,拿到的数据不一定是都达到理想状态,而数据中也会包含有噪声和缺失值等影响结果的数据。
(1)噪声:数据中包含错误值和离群值。
【注】离群值就是超过一定范围的数据,比如:用正态分布去看,超过3δ的值就是离群值。
(2)缺失值:可以说是属性的列表缺失掉的一个数值或者数据中所缺失的一个属性。
【特别注意】在数据预处理过程中,需要话费60%~80%的精力在数据预处理上,要知道高质量的数据才会探测出高质量的结果;数据预处理做的越好,所得到的结果更加优越。
以葡萄酒为例,处理离群值:
def std_data(data2):
#计算标准差
std = data2['magnesium'].std()
ms = []
for item in data2['magnesium']:
if item <= 3*std or item >= -3*std: #3*std---3倍的标准差
ms.append(item)
if item > 3*std:
item = 3*std
ms.append(item)
else:
item = -3*std
ms.append(item)
new_magnesium = pd.DataFrame(ms) ##把数组转化为DataFrame
data2['magnesium'] = new_magnesium
return data2【注】范围[-3,3]倍的标准差,当计算值的范围小于等于-3倍的标准差时,就用-3倍的标准差替换原值;当计算值的范围大于等于3倍的标准差时,就用3倍的标准差替换原值。
卡方检验
1、卡方检验通俗一点说就是检验两个变量之间有没有关系。
2、统计样本的实际观测值与推断值之间的偏离程度,而偏离程度也就决定了卡方值的大小。
【注】卡方值越大,两者偏离程度越大;反之偏离程度越小
若两值完全相等时,卡方值=0
【注】0假设:H0
自由度(df)=(3-1)*(2-1)-----(三列-1)*(两行-1)
置信度(p)
方差分析
用于比较两个或者多个变量的数据样本。
【注】在进行方差分析时,
(1)不相关变量可以直接删除(drop)
(2)当多余变量中的两个相关性很强,可以删除一个,作他们与目标变量之间的相关性,那个的相关性强留下哪一个。
以葡萄酒为例,进行方差分析:
model_df =
ols('target~alcohol+malic_acid+ash+alcalinity_of_ash+total_phenols+flavanoids+nonflavanoid_phenols+proanthocyanins+color_intensity+hue+proline+magnesium',data=data_3).fit()
anova_table = anova_lm(model_df) # anova_lm()函数创建模型生成方差分析表
print(anova_table)生成的方差分析表:
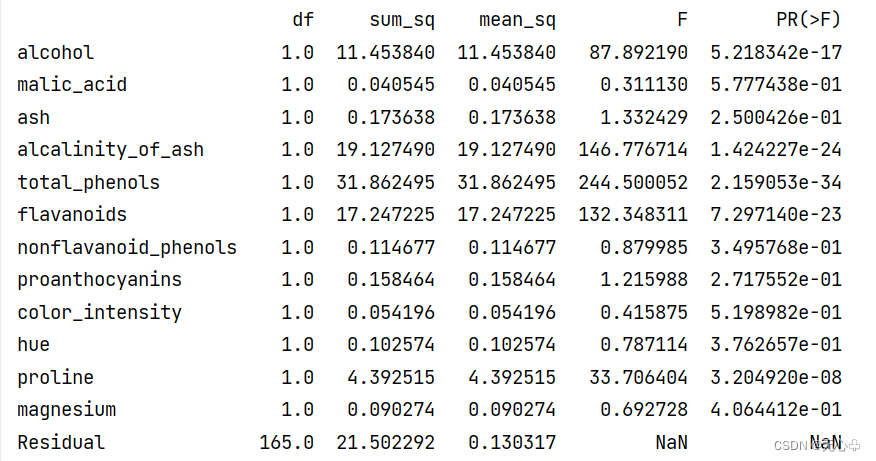
【注】Residual表示误差,df表示自由度,sum_sq表示离差平方和,mean_sq表示均方离差,F表示F值,PR(>F)表示F值所对应的显著水平















 3万+
3万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









