







安装工具包
!pip install networkx gensim pandas numpy tqdm scikit-learn matplotlib导入工具包
#图数据挖掘
import networkx as nx
#数据分析
import pandas as pd
import numpy as np
#随机数
import random
#进度条
from tqdm import tqdm
#数据可视化
import matplotlib.pyplot as plt
%matplotlib inline
#显示中文标签
plt.rcParams['axes.unicode_minus'] = False
#正常显示负号
plt.rcParams["font.sans-serif"] = ["SimHei"]打开网站
https://densitydesign.github.io/strumentalia-seealsology/
输入
https://en.wikipedia.org/wiki/Computer_vision
https://en.wikipedia.org/wiki/Deep_learning
https://en.wikipedia.org/wiki/Convolutional_neural_network
https://en.wikipedia.org/wiki/Decision_tree
https://en.wikipedia.org/wiki/Support-vector_machine
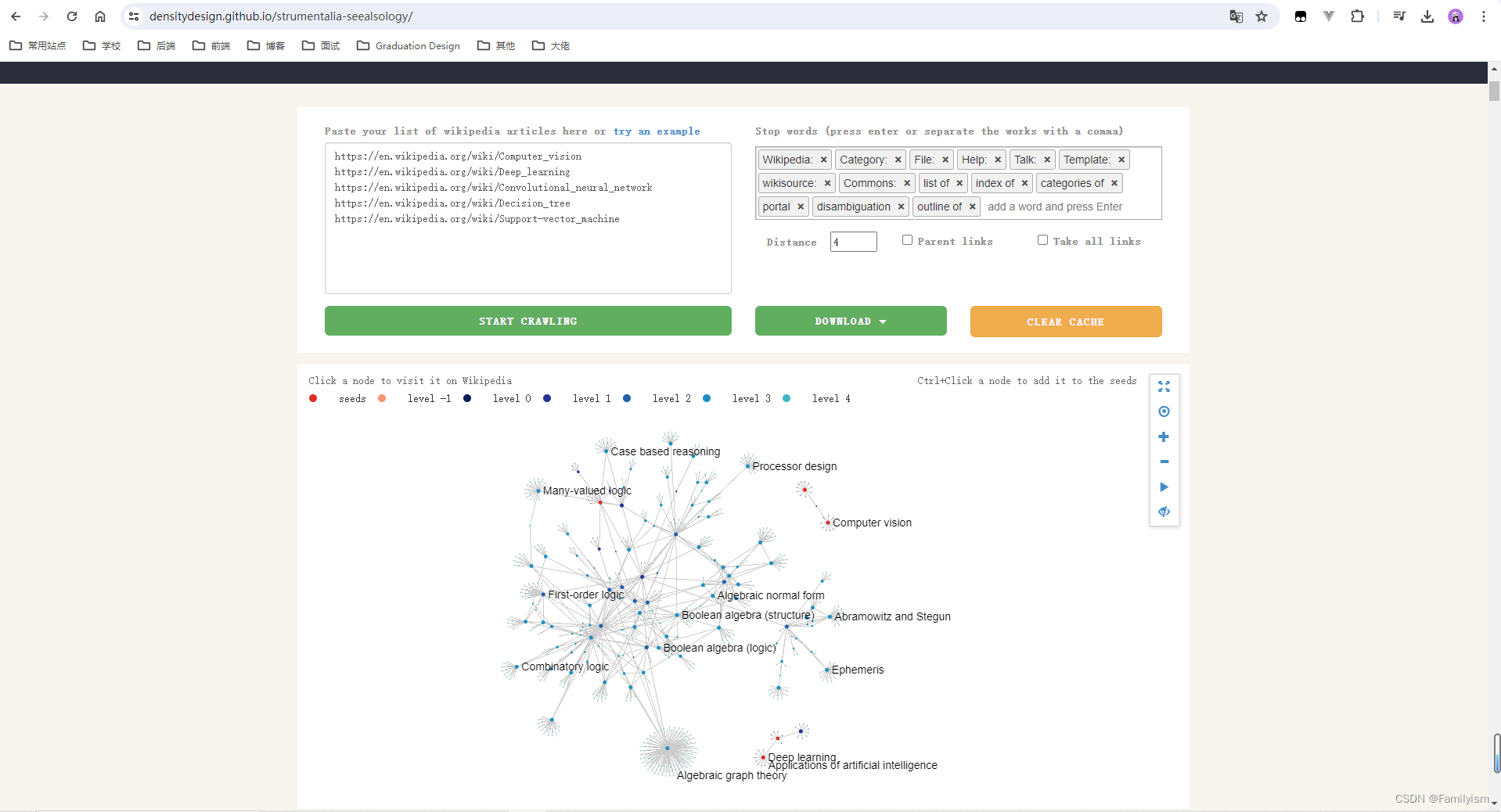
爬取完成以后下载tsv文件
导入爬取的tsv文件
df = pd.read_csv("seealsology-data.tsv" , sep= "\t")
df.head()
df.shape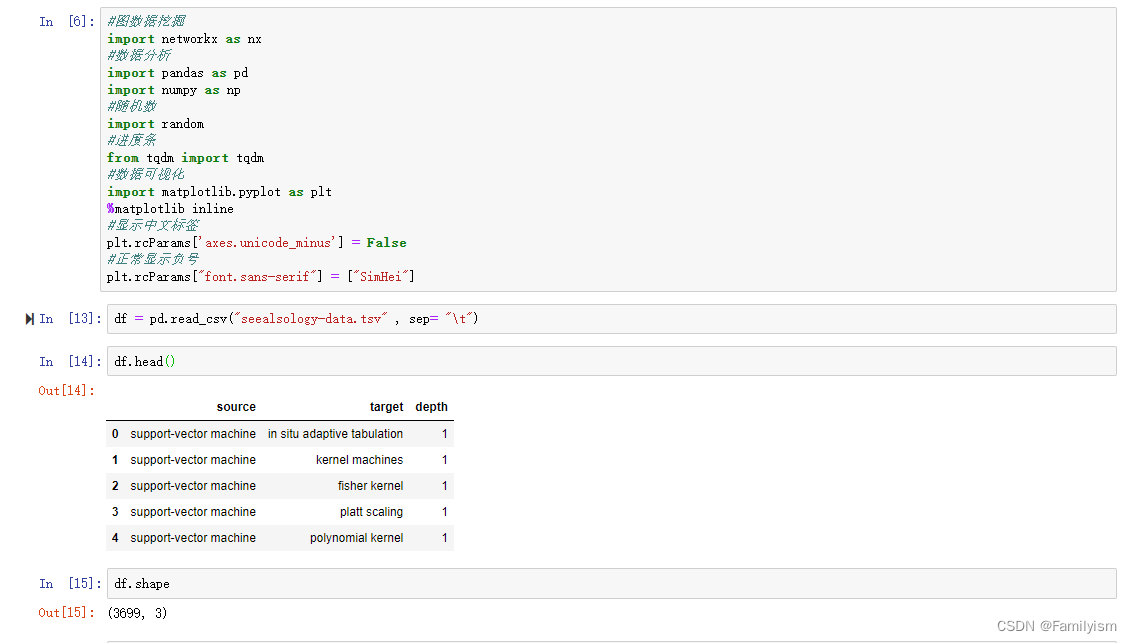
构建无向图
G = nx.from_pandas_edgelist(df,"source","target",edge_attr=True,create_using=nx.Graph)
len(G)生成随机游走节点序列的函数
def get_randomwalk(node,path_length):
random_walk=[node]
for i in range(path_length-1):
#汇总邻居节点
temp = list(G.neighbors(node))
temp = list(set(temp)-set(random_walk))
if len(temp)==0:
break
#从邻居节点中随机选择下一个节点
random_node=random.choice(temp)
random_walk.append(random_node)
node = random_node
return random_walk
all_nodes = list(G.nodes())
all_nodes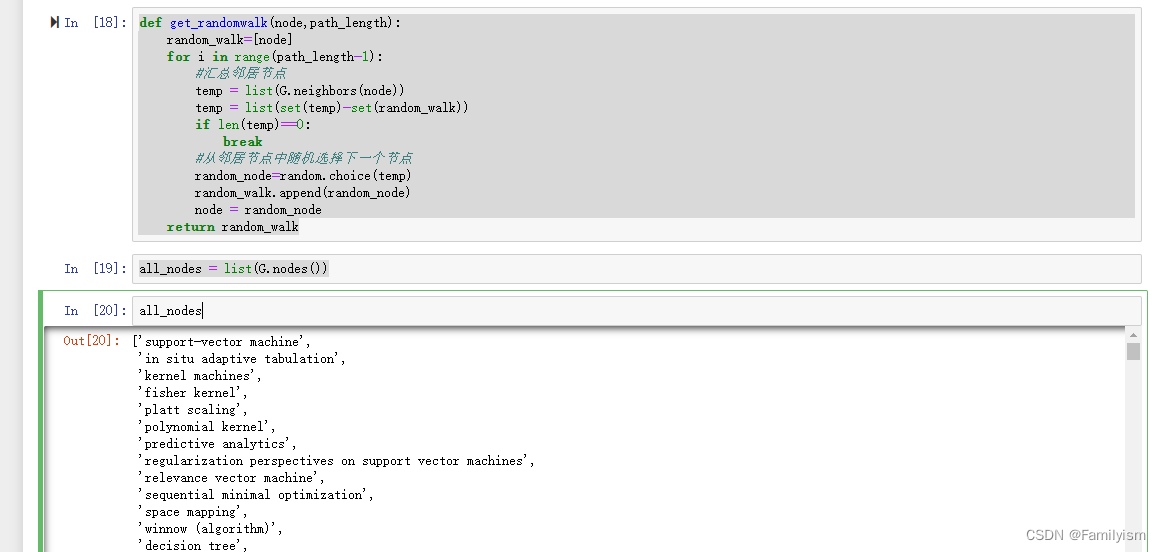
生成随机游走序列
gamma = 10
walk_length=5
random_walks=[]
for n in tqdm(all_nodes):
for i in range(gamma):
random_walks.append(get_randomwalk(n,walk_length))
len(random_walks)
random_walks[1]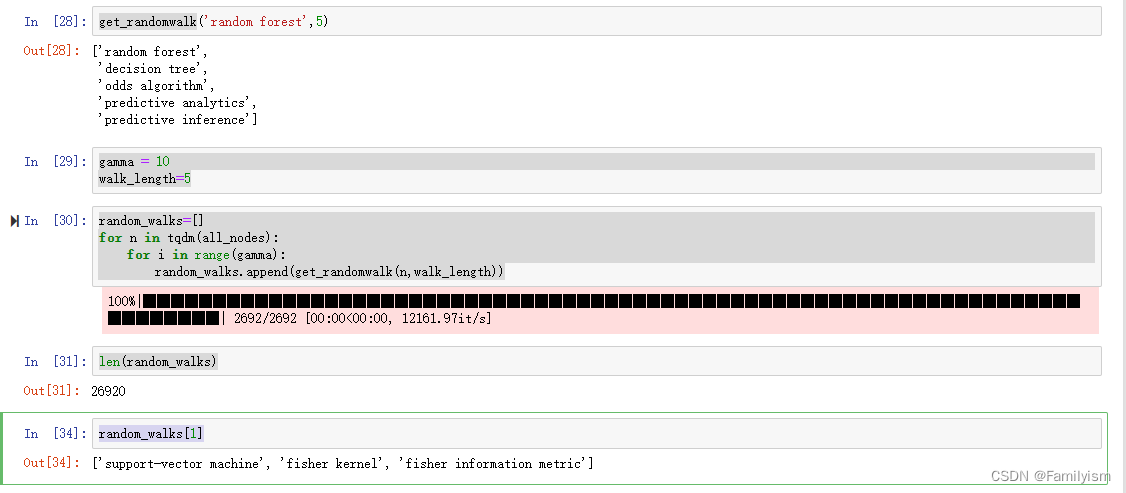
训练word2vec模型
from gensim.models import Word2Vec #自然语言处理
model = Word2Vec(vector_size=256,#Embedding维数
window=4,#窗口宽度
sg=1, #Skip-Gram
hs=0,#不加分层softmaxnegative-10,#负采样
alpha=0.03, #初始学习率
min_alpha=0.0007,#最小学习率
seed=14#随机数种子
)
#用随机游走序列构建词汇表
model.build_vocab(random_walks, progress_per=2)
#训练(耗时1分钟左右)
model.train(random_walks,total_examples=model.corpus_count, epochs=50,report_delay=1)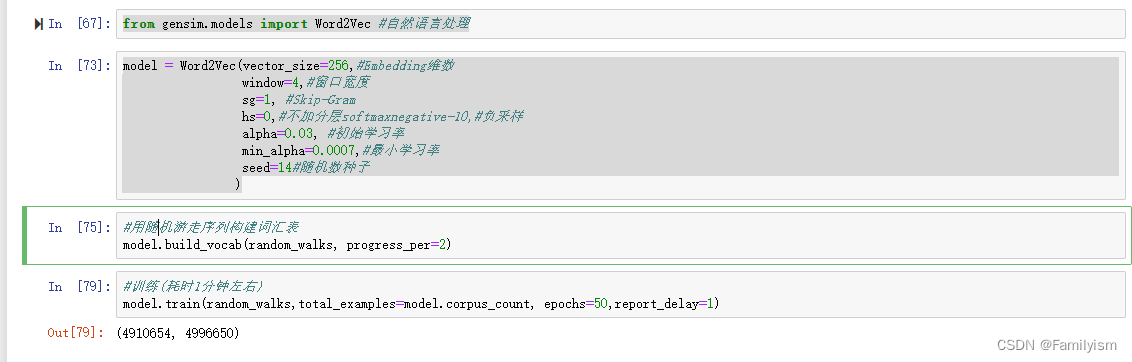
分析word2vec结果
model.wv.get_vector('random forest').shape
model.wv.get_vector('random forest')
model.wv.similar_by_word('decision tree')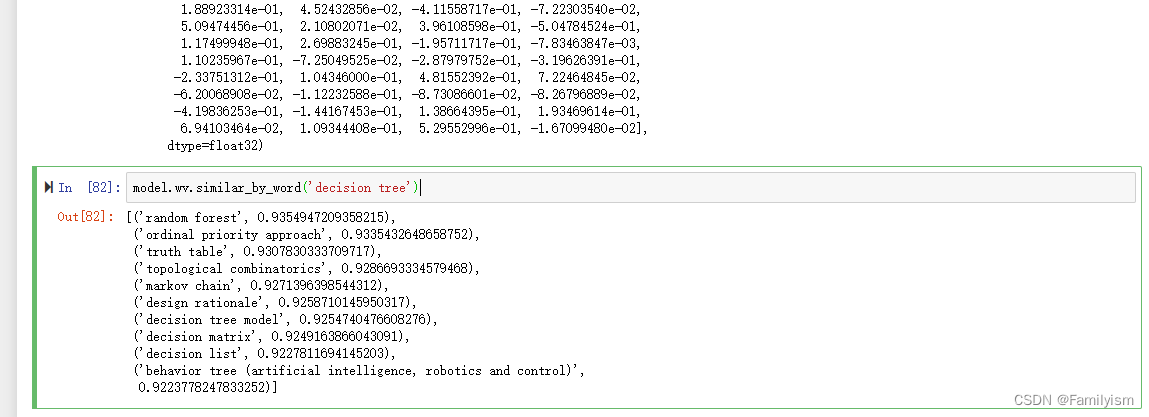
PAC降维处理
X =model.wv.vectors
from sklearn.decomposition import PCA
pca = PCA(n_components=2)
embed_2d = pca.fit_transform(X)
embed_2d.shape
plt.figure(figsize=(14,14))
plt.scatter(embed_2d[:, 0 ],embed_2d[:, 1 ])
plt.show()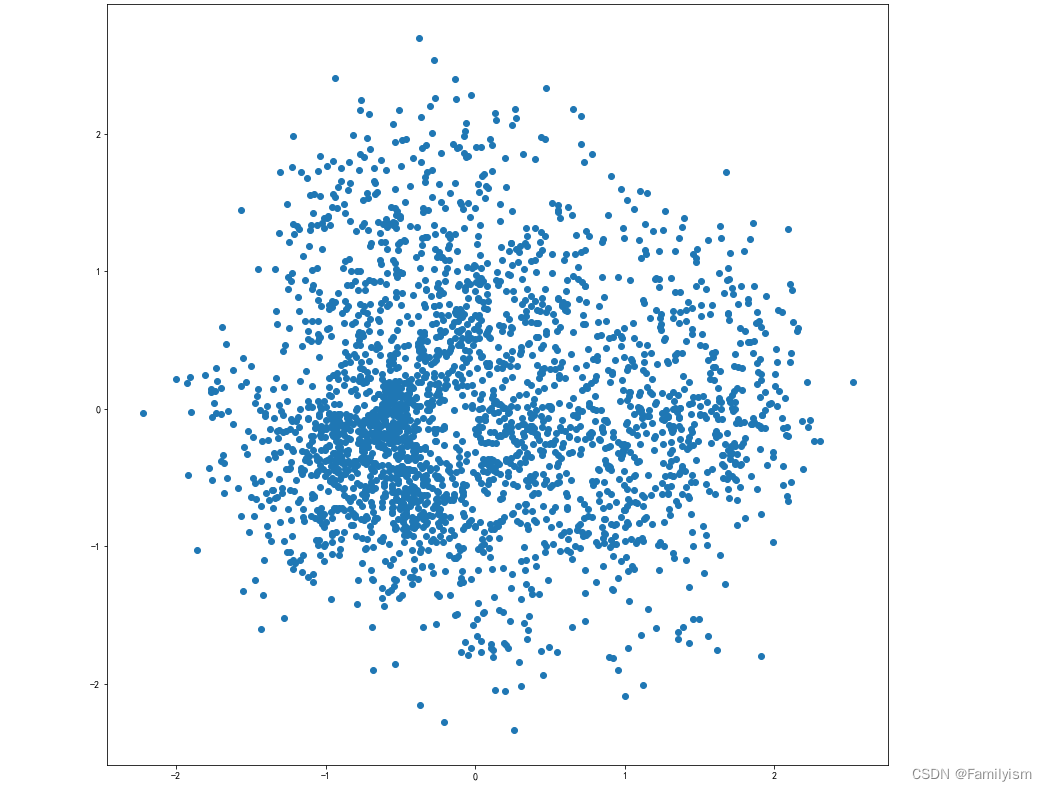
可视化某个词条的二维Embedding
term = 'computer vision'
term_256d=model.wv[term].reshape(1,-1)
term_256d.shape
term_2d = pca.transform(term_256d)
term_2d
plt.scatter(embed_2d[:, 0 ],embed_2d[:, 1 ])
plt.scatter(term_2d[:, 0 ],term_2d[:, 1 ],c='r',s=200)
plt.show()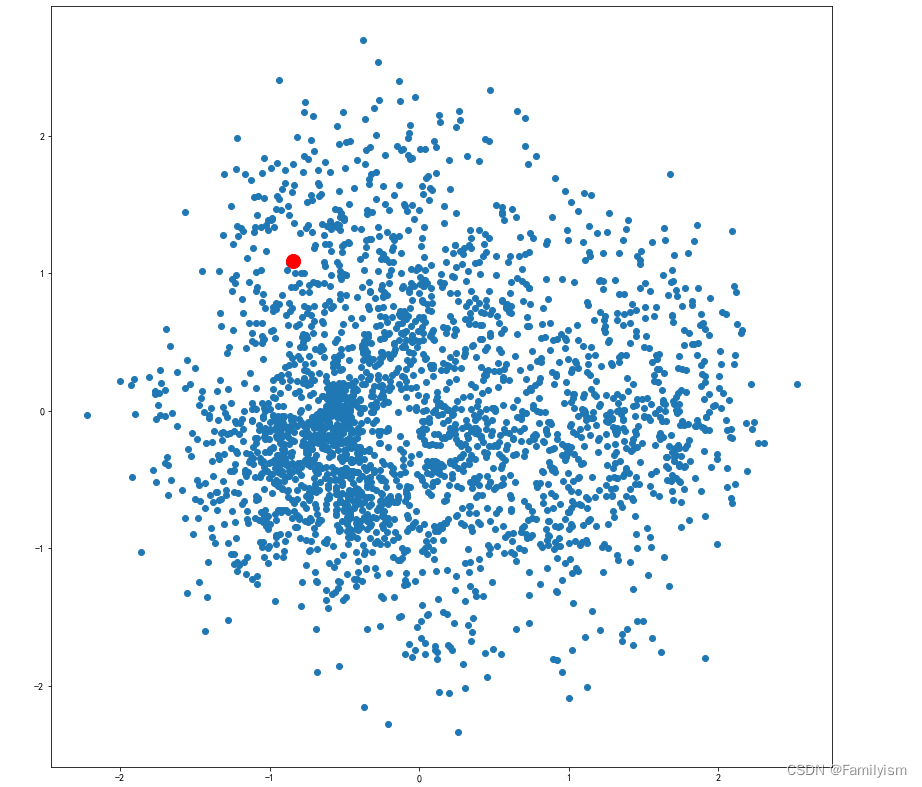
可视化某些词条的二维Embedding
pagerank = nx.pagerank(G)
node_importance = sorted(pagerank.items(),key=lambda x:x[1],reverse=True)
n=30
terms_choose = []
for each in node_importance [:n]:
terms_choose.append(each[0])
terms_choose
term2index = model.wv.key_to_index
plt.figure(figsize=(14,14))
plt.scatter(embed_2d[:, 0 ],embed_2d[:, 1 ])
for item in terms_choose:
idx=term2index[item]
plt.scatter(embed_2d[idx, 0 ],embed_2d[idx, 1 ],c='r',s=50)
plt.annotate(item,xy=(embed_2d[idx, 0 ],embed_2d[idx, 1 ]),c='k',fontsize=12)
plt.show()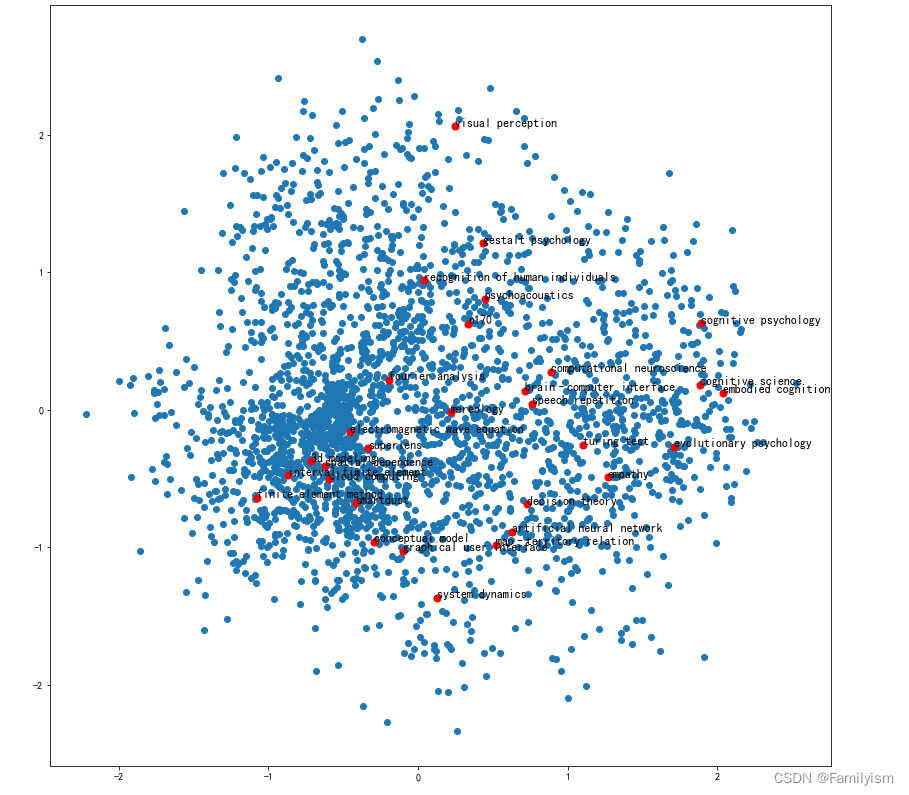
TSNE降维可视化
from sklearn.manifold import TSNE
tsne = TSNE(n_components=2,n_iter=1000)
embed_2d = tsne.fit_transform(X)
plt.figure(figsize=(14,14))
plt.scatter(embed_2d[:, 0 ],embed_2d[:, 1 ])
plt.show()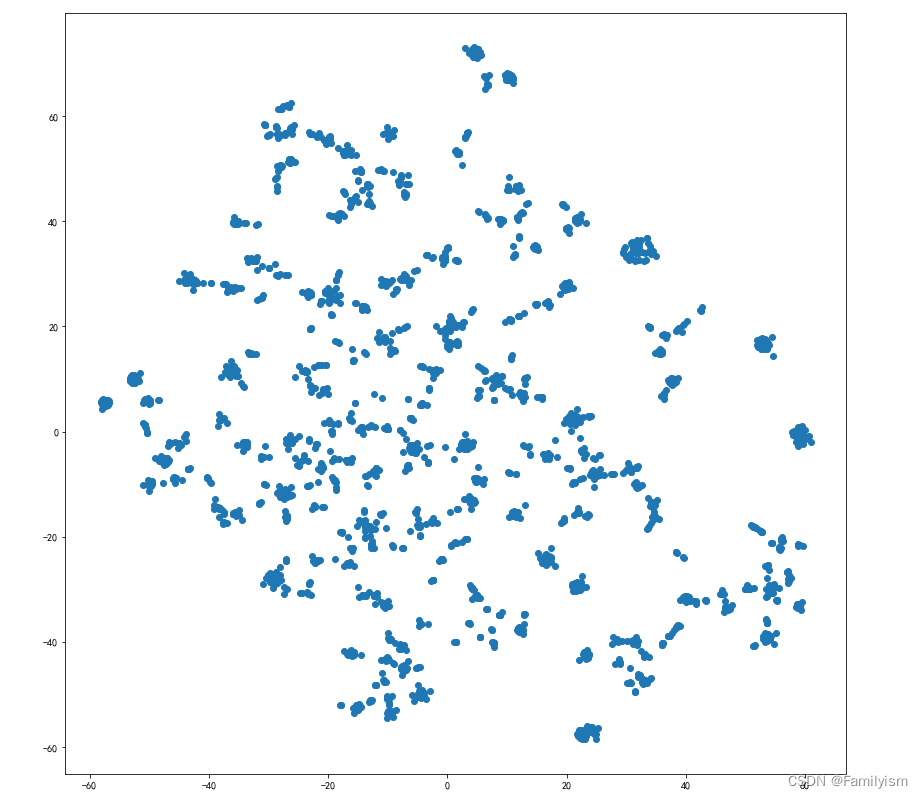
可视化某些词条的二维Embedding
plt.figure(figsize=(14,14))
plt.scatter(embed_2d[:, 0 ],embed_2d[:, 1 ])
for item in terms_choose:
idx=term2index[item]
plt.scatter(embed_2d[idx, 0 ],embed_2d[idx, 1 ],c='r',s=50)
plt.annotate(item,xy=(embed_2d[idx, 0 ],embed_2d[idx, 1 ]),c='k',fontsize=12)
plt.show()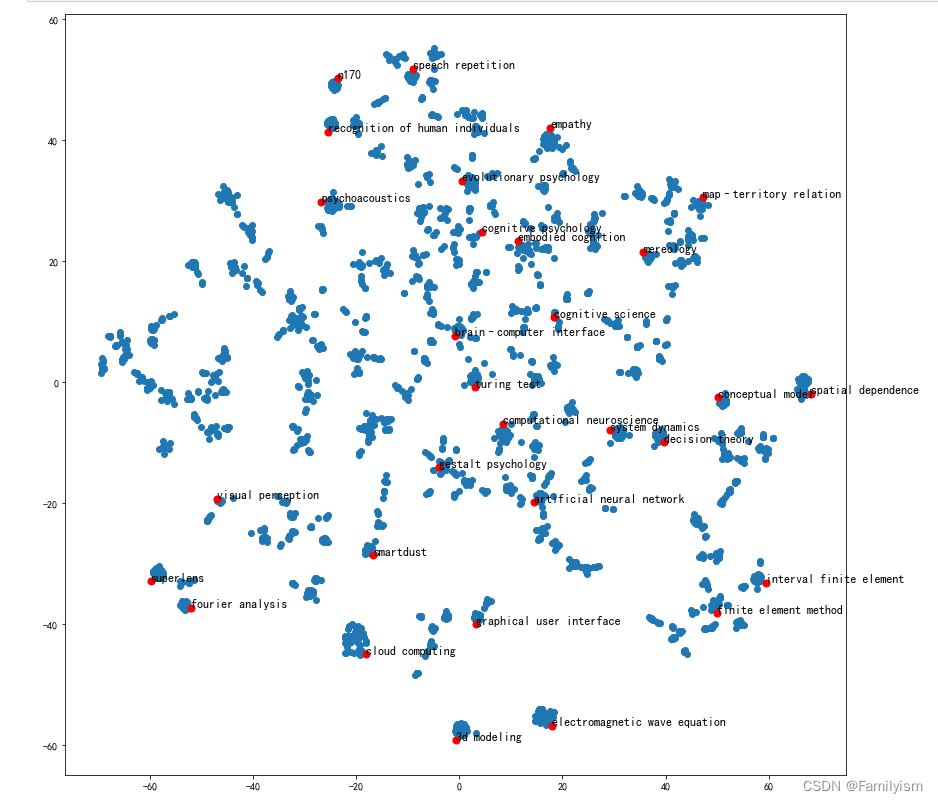
















 482
482











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









