安装工具包
!pip install node2vec networkx numpy matplotlib
导入工具包
import networkx as nx #图数据挖掘
import numpy as np #数据分析
import random #随机数
#数据可视化
import matplotlib.pyplot as plt
%matplotlib inline
plt.rcParams['axes.unicode_minus'] = False
plt.rcParams["font.sans-serif"] = ["SimHei"]
导入数据集
G = nx.les_miserables_graph()
G.nodes
len(G)
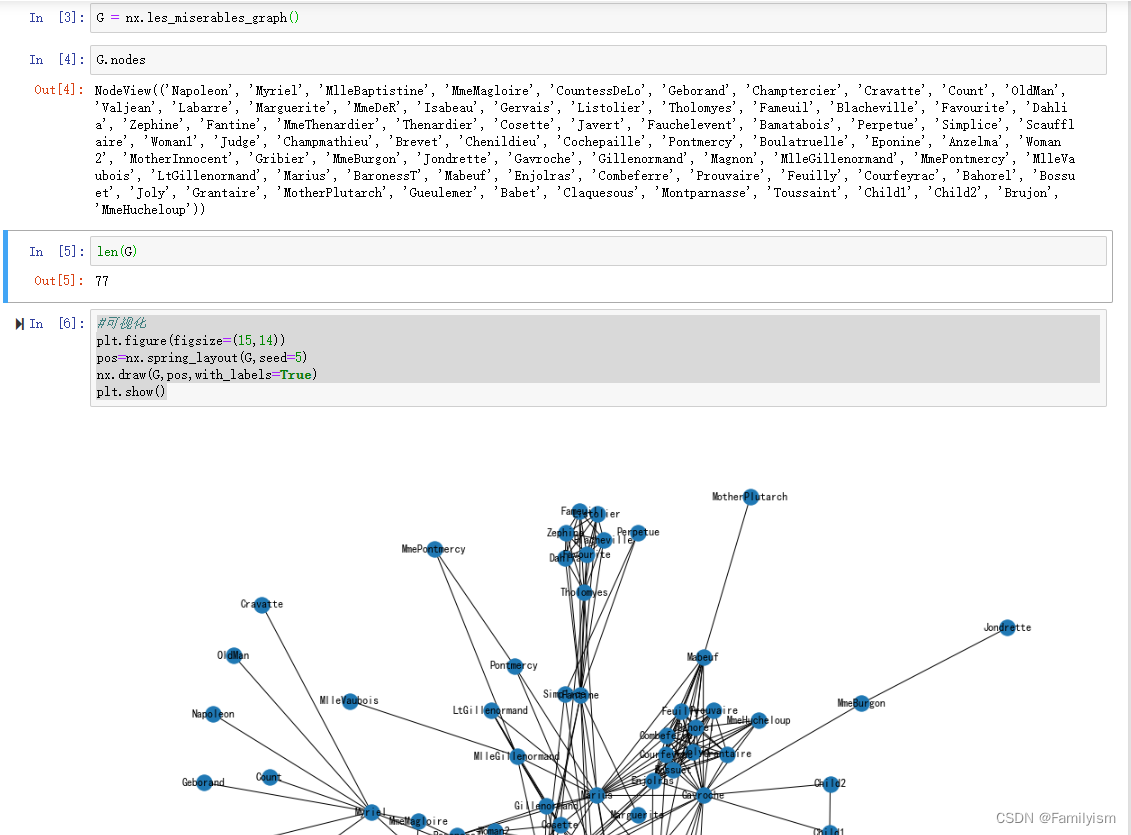
#可视化
plt.figure(figsize=(15,14))
pos=nx.spring_layout(G,seed=5)
nx.draw(G,pos,with_labels=True)
plt.show()
构建node2vec模型
from node2vec import Node2Vec
# 设置node2vec参数
node2vec = Node2Vec(G,
dimensions=32, # 嵌入维度
p=1, # 回家参数
q=3, # 外出参数
walk_length=10, # 随机游走最大长度
num_walks=600, # 每个节点作为起始节点生成的随机游走个数
workers=4 # 并行线程数
)
# p=1, q=0.5, n_clusters=6。DFS深度优先搜索,挖掘同质社群
# p=1, q=2, n_clusters=3。BFS宽度优先搜索,挖掘节点的结构功能。
# 训练Node2Vec,参数文档见 gensim.models.Word2Vec
model = node2vec.fit(window=3, # Skip-Gram窗口大小
min_count=1, # 忽略出现次数低于此阈值的节点(词)
batch_words=4 # 每个线程处理的数据量
)
X = model.wv.vectors # 77个节点的嵌入向量
节点Embedding聚类可视化
#DBSCAN聚类
# from sklearn.cluster import DBSCAN
# cluster_labels = DBSCAN(eps=0.5,min samples=6).fit(X).labels
# print(cluster labels)
# KMeans聚类
from sklearn.cluster import KMeans
cluster_labels = KMeans(n_clusters=3).fit(X).labels_ # 对X进行聚类,聚成三簇,
print(cluster_labels) # 得到聚类的label
将词汇表的节点顺序转为networkx中的节点顺序。
colors = []
nodes = list(G.nodes)
for node in nodes: # 按 networkx 的顺序遍历每个节点
idx = model.wv.key_to_index[str(node)] # 获取这个节点在 embedding 中的索引号
colors.append(cluster_labels[idx]) # 获取这个节点的聚类结果
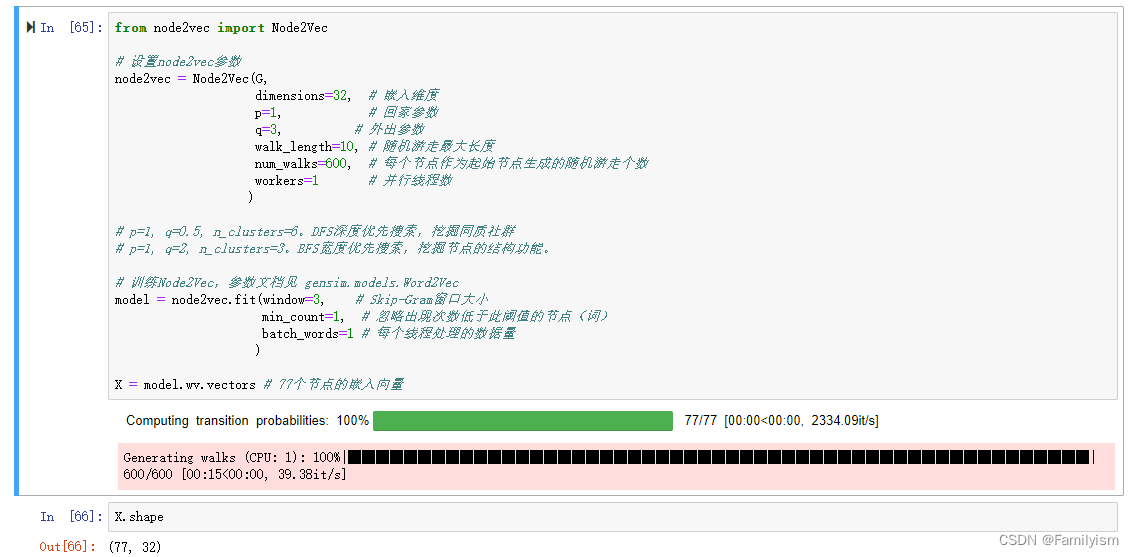
可视化聚类
plt.figure(figsize=(15,14))
pos = nx.spring_layout(G, seed=10)
nx.draw(G, pos, node_color=colors, with_labels=True)
plt.show()
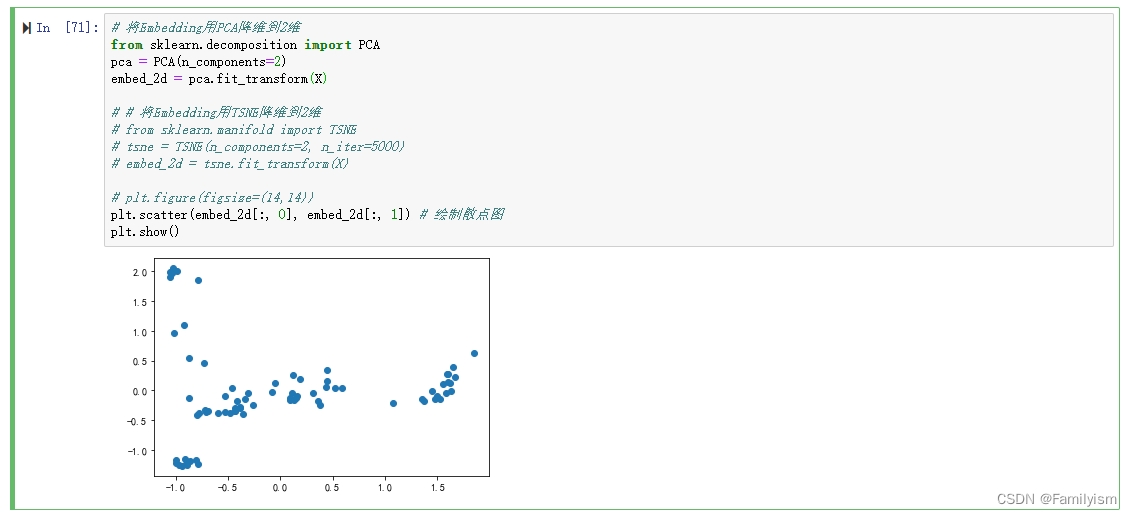
将Embedding用PCA降维到2维
# 将Embedding用PCA降维到2维
from sklearn.decomposition import PCA
pca = PCA(n_components=2)
embed_2d = pca.fit_transform(X)
# # 将Embedding用TSNE降维到2维
# from sklearn.manifold import TSNE
# tsne = TSNE(n_components=2, n_iter=5000)
# embed_2d = tsne.fit_transform(X)
# plt.figure(figsize=(14,14))
plt.scatter(embed_2d[:, 0], embed_2d[:, 1]) # 绘制散点图
plt.show()
查看Embedding
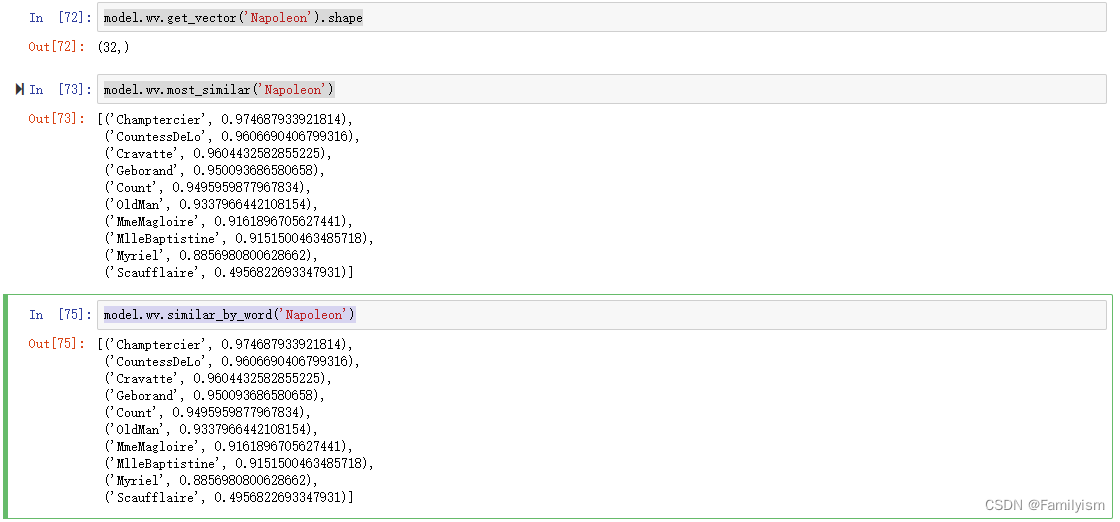
model.wv.get_vector('Napoleon').shape
model.wv.most_similar('Napoleon')
model.wv.similar_by_word('Napoleon')
对edge连接进行embedding
from node2vec.edges import HadamardEmbedder # 导入工具包
# Hadamard 二元操作符:两个 Embedding 对应元素相乘
edges_embs = HadamardEmbedder(keyed_vectors=model.wv)
edges_embs[('Napoleon','Brujon')]
#计算所有的Edge的Embedding
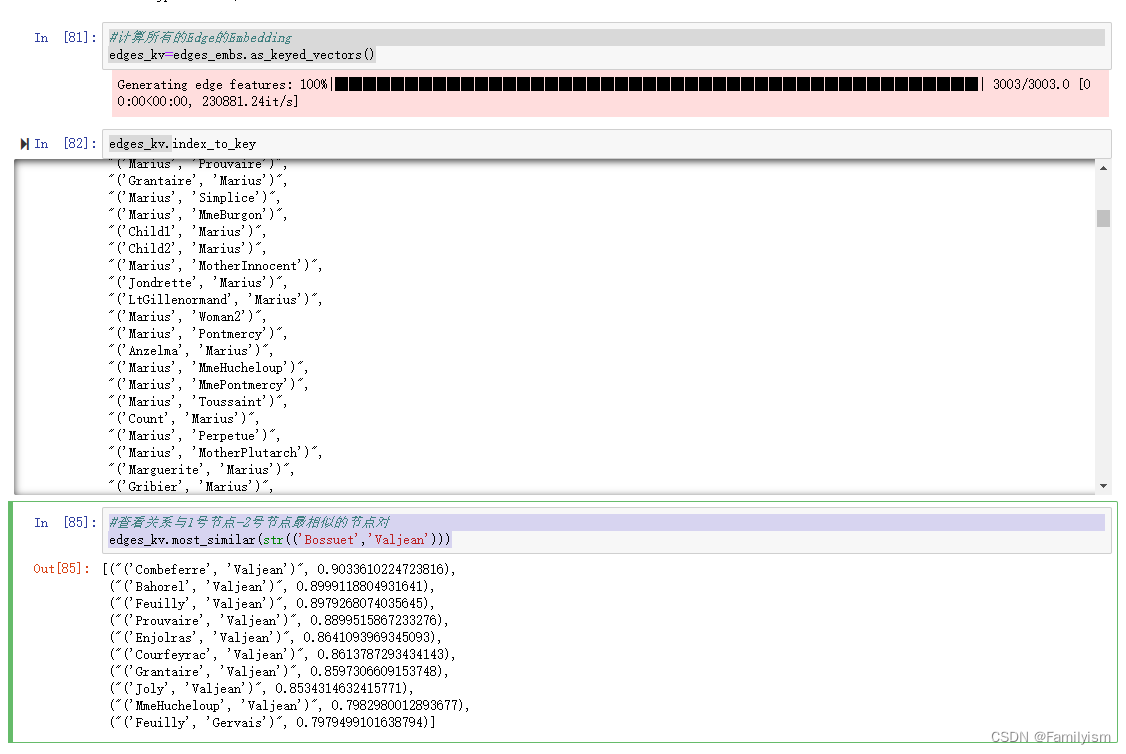
edges_kv=edges_embs.as_keyed_vectors()
edges_kv.index_to_key
#查看关系与1号节点-2号节点最相似的节点对
edges_kv.most_similar(str(('Bossuet','Valjean')))
























 2324
2324











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









