






语义分割模型中训练自己的数据集
新版本的 labelme 标注完成图像后,将 json 文件转换为图像时已经转换为 8 通道图像
但用别人的数据集发现经过图像标注生成的 label 一片黑,且图像深度为 24 位,或者别人提供的图像是24位深度
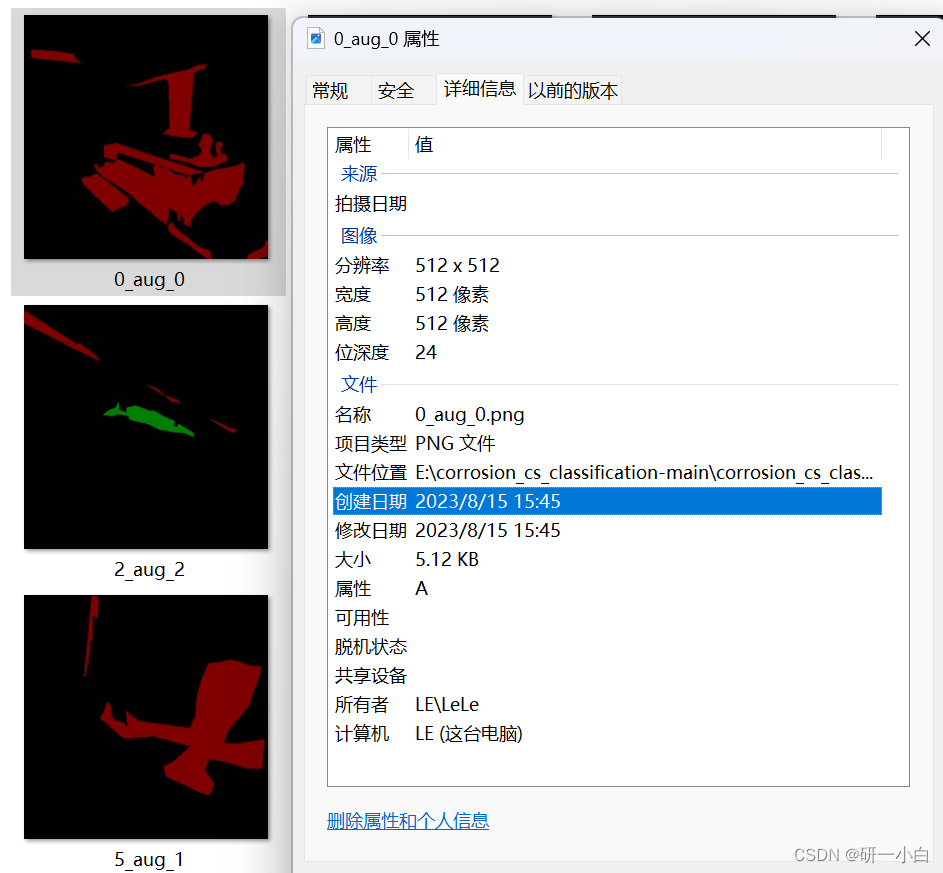
但分割模型要求标签label(mask)是8位彩图或灰度图

用程序进行转换自制VOC格式图像分割数据集:使用python+PIL生成8位深的RGB图像_图像分割标签位深_Cai.SN的博客-CSDN博客
from random import randint
import os
import numpy as np
import imgviz
from PIL import Image
def get_gray_cls(van_lbl, array_lbl):
cls = [0] # 用来存储灰度图像中每种类别所对应的像素,默认背景色为0
for x in range(van_lbl.size[0]):
for y in range(van_lbl.size[1]):
if array_lbl[x, y] not in cls:
cls.append(array_lbl[x, y])
return cls
def get_P_cls(cls_gray):
cls_P = [] # 将灰度图像中的每类像素用0~N表示
for i in range(len(cls_gray)):
cls_P.append(i)
return cls_P
def array_gray_to_P(cls_gray, cls_P, array):
for i in range(len(cls_gray)):
array[array == cls_gray[i]] = cls_P[i]
return array
if __name__ == '__main__':
label_from_PATH = "./divide_dataset/Test/mask" # 存放原始label的路径
label_to_PATH = "./divide_dataset/Test8" # 存放转换后图像当路径
van_file = './divide_dataset/val/labels/345_1.png' # 必须是一张包含所有类别的图像,称之为先锋图像
van_lbl = Image.open(van_file).convert('L') # 将先锋图像转换为灰度图像
array_lbl = np.array(van_lbl) # 获得灰度图像的numpy矩阵
cls_gray = get_gray_cls(van_lbl, array_lbl) # 获取灰度图像中每种类别所对应的像素值
cls_P = get_P_cls(cls_gray) # 将灰度图像中的每种类别所对应的像素值映射为0~N
# print(cls_gray)
# print(cls_P)
file_list = os.listdir(label_from_PATH)
if not os.path.isdir(label_to_PATH):
os.mkdir(label_to_PATH)
# 遍历每一张原始图像
for file_name in file_list:
file_path = os.path.join(label_from_PATH, file_name)
orig_lbl = Image.open(file_path).convert('L') # 将图像转换为灰度图像
array_gray = np.array(orig_lbl) # 获得灰度图像的numpy矩阵
array_P = array_gray_to_P(cls_gray, cls_P, array_gray) # 将灰度图像的numpy矩阵值映射为0~N
label = Image.fromarray(array_P.astype(np.uint8), mode='P') # 转换为PIL的P模式
# 转换成VOC格式的P模式图像
colormap = imgviz.label_colormap()
label.putpalette(colormap.flatten())
label.save(os.path.join(label_to_PATH, file_name))这个程序输入必须是一张包含所有类别的图像,称之为先锋图像,这样转换后的像素只有图像中的颜色数目,而不会出现多余的颜色
转换后的测试代码,因为本人做的三分类,加背景,转换后的应该只有四个类别,四个像素
import PIL.Image
import numpy as np
from numpy import dtype
img = PIL.Image.open(r"E:\pic_process\imgaug\divide_dataset\after\103_5.png")
print(np.unique(img))结果为

问题总结:
1 . 在跑bubbliiiing博客中pspnet训练自己的数据集中出现的损失不下降,Accuracy为100,mIOU不增长的问题也是标签文件转换的问题。
用voc_annotation.py划分数据集时,可以判断是否数据集标签正确,转换8位标签有问题时,出现
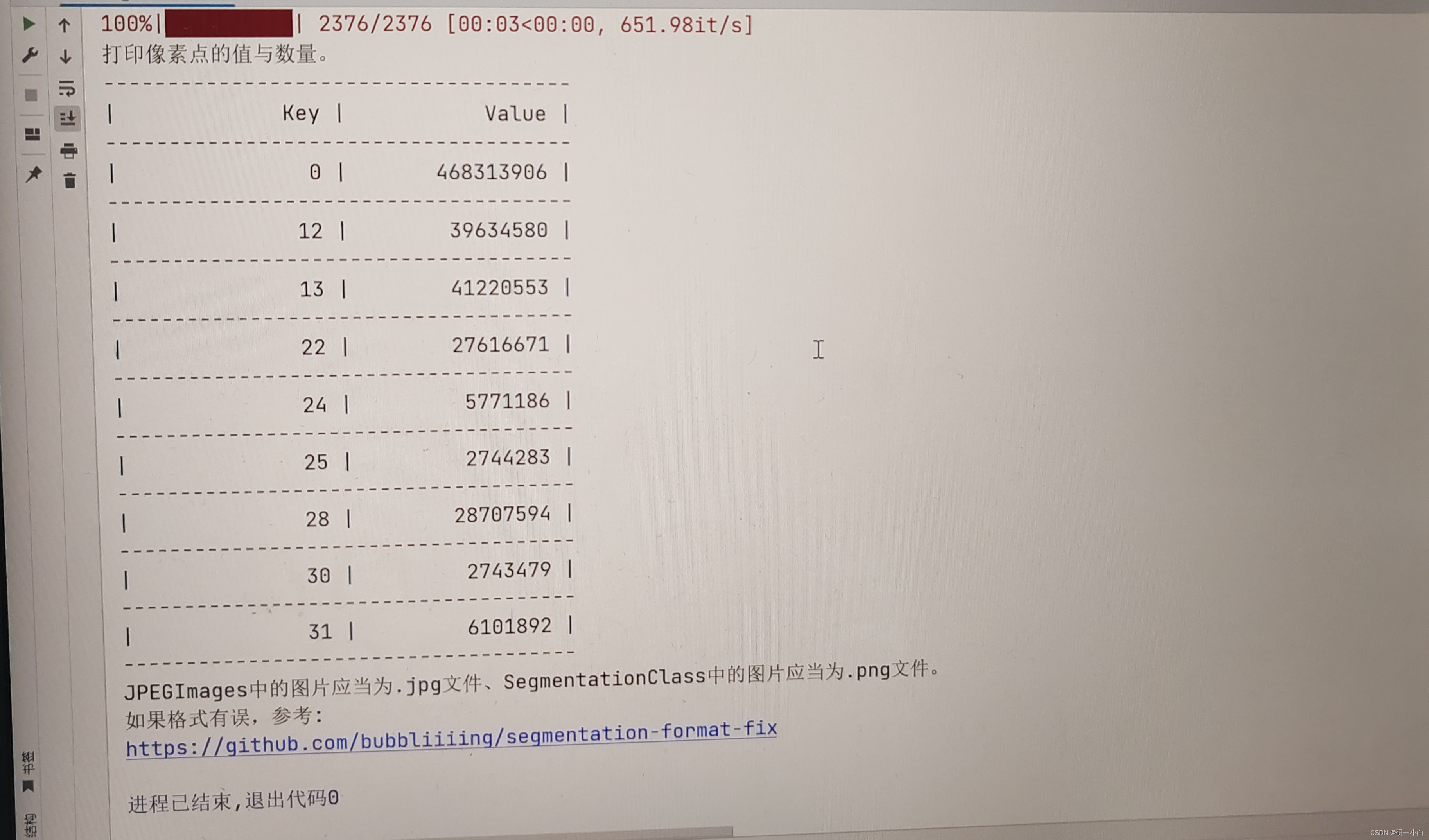
明明标签(含背景)只有4分类,但错误的(24bit to 8bit)图像后,却有9类图像。
所以图像的预处理很重要
2. 根据博主霹雳吧啦Wz,用FCN训练自己的数据集中,出现错误
cuda\NLLLoss2d.cu:103: block: [2,0,0], thread: [735,0,0] Assertion `t >= 0 \\&\\& t < n_classes` failed.
以及
【代码error】RuntimeError: 1only batches of spatial targets supported (3D tensors) but got targets of size: : [4, 512, 512, 3]
两个问题都是因为上述数据标签转化问题

















 2814
2814

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









