







为了便于理解,本文前面尽量使用简短通俗的语言
在开始之前,首先介绍一些概念:
CANN :华为提供的异构计算架构,从底层芯片到上层软件都提供支持,目标是让AI算法在昇腾芯片上高效运行、精度高、容易部署 。
应用开发 :用CANN提供的接口,把已有的AI模型或者算法直接部署到昇腾芯片上运行。
Ascend CL :应用开发时用到的语言。
算子开发 :如果CANN工具包里没有你需要的计算单元(比如某个特殊数学运算),就得自己用Ascend C语言 写一个算子。
Ascend C :CANN专为算子开发设计的编程语言,其编译器像“开发者和硬件芯片间的翻译官”,帮你把代码转换成昇腾芯片能直接执行的指令。
AI Core :昇腾芯片里的核心,负责执行CANN下发的具体计算任务,是芯片高效运行的关键部件。
一句话类比总结 :假设用造车来比喻,CANN就像一家“智能汽车工厂”,提供从设计图纸到零件生产、整车组装的全套工具链。应用开发类似“整车组装”,用工厂提供的标准零件,把设计好的汽车组装起来,Ascend CL类似“生产线控制系统”,算子开发类似“定制零件”,Ascend C是“数控机床”,AI Core是“引擎”。
了解了上述基本概念,我们就对CANN整体有了基本的认知。要学习和使用CANN,首先要明确自己的目的,CANN提供了包括应用开发,算子开发,图开发,集合通信等等······(当然作者也未全部涉猎,作者最初的目的就是将已有的matlab算法搬到昇腾芯片上运行hhh)因为最近要学习的是算子开发,所以要先了解硬件架构,本文将以通俗的语言描述在学习昇腾AI core硬件架构时的一些理解和思考。
首先是整个AI处理器的架构
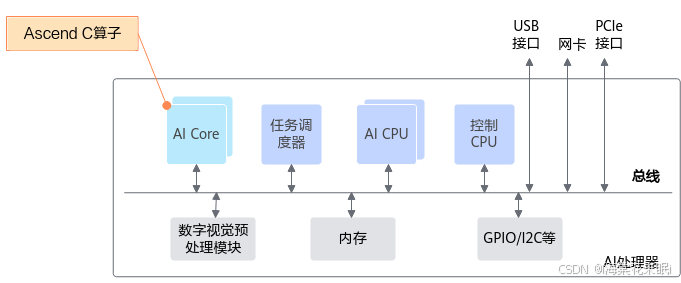
整体架构这里不过多介绍,Ascend C算子在AI core上运行,所以重点介绍AI core架构
AI core架构
AI core包括三种基础计算单元:Cube(矩阵)计算单元、Vector(向量)计算单元和Scalar(标量)计算单元,同时还包含存储单元(包括硬件存储和用于数据搬运的搬运单元)和控制单元。硬件架构根据Cube计算单元和Vector计算单元是否同核部署分为耦合架构和分离架构两种。
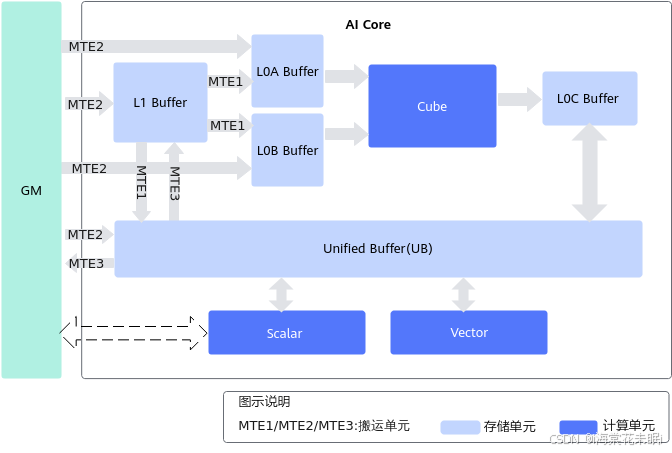
耦合架构
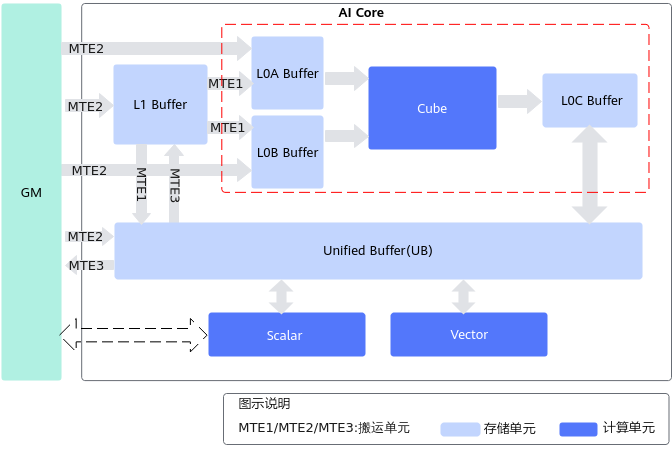
耦合架构是指Cube计算单元和Vector计算单元同核部署,架构图如下图所示,耦合架构中Cube计算单元和Vector计算单元共享同一个Scalar单元,统一加载所有的代码段。下图中列出了计算架构中的存储单元和计算单元,箭头表示数据处理流向,MTE1/MTE2/MTE3代表搬运单元。
分离架构
如下图所示,分离架构将AI Core拆成矩阵计算(AI Cube,AIC)和向量计算(AI Vector,AIV)两个独立的核,每个核都有自己的Scalar单元,能独立加载自己的代码段,从而实现矩阵计算与向量计算的解耦。增加了两个Buffer:BT Buffer(BiasTable Buffer,存放Bias)和FP Buffer(Fixpipe Buffer,存放量化参数、Relu参数等)。 (这两个Buffer作者还不太理解,有大佬看到希望能解释一波)
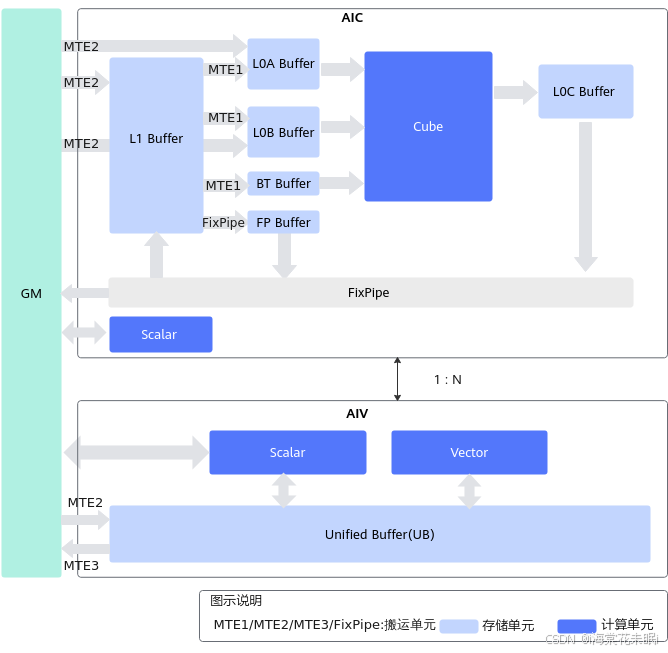
分离架构典型计算数据流:
- Vector计算:GM-UB- [Vector]-UB-GM
- Cube计算:
- GM-L1-L0A/L0B-[Cube]-L0C-FixPipe-L1
- GM-L1-L0A/L0B-[Cube]-L0C-FixPipe-GM
计算单元
计算单元包括Cube(矩阵)计算单元、Vector(向量)计算单元和Scalar(标量)计算单元
Scalar
Scalar负责各类型的标量数据运算和程序的流程控制。功能上可以看做一个小CPU,可以控制程序流水,进行指令的地址和参数计算,控制AI Core中其他执行单元的流水。
思考:相对于Host CPU,AI Core中的Scalar计算能力较弱,重点用于发射指令,所以在实际应用场景中应尽量减少Scalar计算,比如性能调优时尽量减少if/else等分支判断及变量运算。
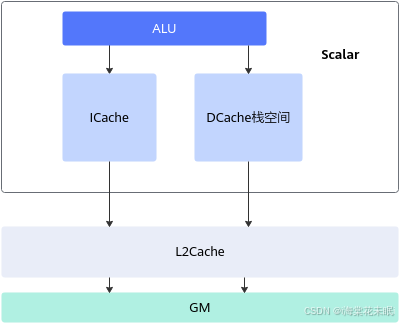
如下图所示:Scalar执行标量运算指令时,执行标准的ALU(Arithmetic Logic Unit)语句,ALU需要的代码段和数据段都来自于GM。ICache(Instruction Cache)用于缓存代码段,缓存大小与硬件规格相关,比如为16K或32K,以2K为单位加载;DCache(Data Cache)用于缓存数据段,大小也与硬件规格相关,比如为16K,以cacheline(64Byte)为单位加载。
思考:考虑到核内访问效率最高,应尽量保证代码段和数据段被缓存在ICache和DCache,避免核外访问; 同时根据数据加载单位不同,编程时可以考虑单次加载数据大小,来提升加载效率。例如在DCache加载数据时,当数据内存首地址与cacheline(64Byte)对齐时,加载效率最高。
Vector
Vector负责执行向量运算。向量计算单元执行向量指令,类似于传统的单指令多数据(Single Instruction Multiple Data,SIMD)指令,每个向量指令可以完成多个操作数的同一类型运算。如下图所示,向量计算单元可以快速完成两个FP16类型的向量相加或者相乘。
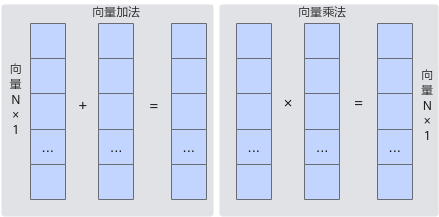
Vector所有计算的源数据以及目标数据都要求存储在Unified Buffer中,Vector指令的首地址和操作长度有对齐要求,通常要求32B对齐,具体对齐要求参考API的约束描述。
Cube
Cube计算单元负责执行矩阵运算。如下图红框所示,其中L0A存储左矩阵,L0B存储右矩阵,L0C存储矩阵乘的结果和中间结果。
存储单元
AI处理器中的存储系统保证计算单元所需的数据供应。
AI Core中包含多级内部存储,AI Core需要把外部存储中的数据加载到内部存储中,才能完成相应的计算。AI Core的内部存储包括:L1 Buffer,L0A Buffer / L0B Buffer,L0C Buffer,Unified Buffer,BT Buffer,FP Buffer。为了配合AI Core中的数据传输和搬运,AI Core中还包含MTE(Memory Transfer Engine,存储转换引擎)搬运单元和FixPipe,在搬运过程中可执行随路数据格式/类型转换。
搬运单元的数据流向在耦合架构图和分离架构图上给出
控制单元
控制单元为整个计算过程提供了指令控制,负责整个AI Core的运行。AI Core包含的控制单元如图所示:
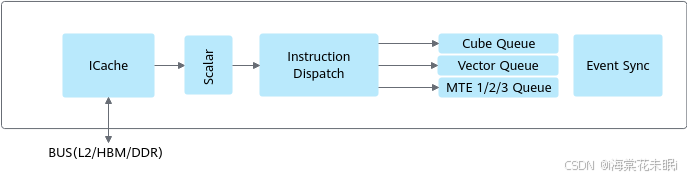
指令从内存加载到指令缓存(ICache)后,按类型分两条路径执行:
- scalar指令 :由scalar单元直接执行;
- 其他指令 :经scalar单元调度至5类专用队列(Vector、Cube、MTE1/MTE2/MTE3)
同一队列内部按入队顺序串行执行,不同队列间可以并行处理以提升效率。对于并行执行过程中可能出现的数据依赖,通过事件同步模块(Event Sync)插入同步指令来控制流水线的同步,提供PipeBarrier、SetFlag/WaitFlag两种API,保证队列内部以及队列之间按照逻辑关系执行。
- PipeBarrier本身是一条指令,用于在队列内部约束执行顺序(虽然指令是顺序执行,但并不意味着后一条指令开始执行时前一条指令执行结束)。PipeBarrier指令可以保证前序指令中所有数据读写全部完成,后序指令才开始执行。
- SetFlag/WaitFlag为两条指令,在SetFlag/WaitFlag的指令中,可以指定一对指令队列的关系,表示两个队列之间完成一组“锁”机制,其作用方式为:
- SetFlag:当前序指令的所有读写操作都完成之后,当前指令开始执行,并将硬件中的对应标志位设置为1。
- WaitFlag:当执行到该指令时,如果发现对应标志位为0,该队列的后续指令将一直被阻塞;如果发现对应标志位为1,则将对应标志位设置为0,同时后续指令开始执行。
SetFlag/WaitFlag常用于跨队列同步,通俗讲,这种情况类似“厨师-服务员”协作:
- 厨师(队列A)做完菜后放盘子到窗口,并喊“菜好了!”。(
SetFlag置1) - 服务员(队列B)听到喊声才端菜,否则一直等待。(
WaitFlag遇1置0,否则等)
大多数情况,基于编程模型中介绍的编程模型和范式进行编程时不需要关注同步
本节先学习到这里,后面是介绍编程模型的章节

















 422
422

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









