







 本文介绍了决策树的基础知识,包括信息熵和信息增益的概念,并探讨了ID3、C4.5和CART等算法的选择原则。此外,详细阐述了如何使用sklearn库构建和可视化决策树。随后,文章转向随机森林这一集成学习方法,解释了随机森林的工作原理,强调了有放回抽样的重要性,并简要提到了随机森林的API参数。最后,指出随机森林在降低过拟合风险和提高预测准确性方面的优势。
本文介绍了决策树的基础知识,包括信息熵和信息增益的概念,并探讨了ID3、C4.5和CART等算法的选择原则。此外,详细阐述了如何使用sklearn库构建和可视化决策树。随后,文章转向随机森林这一集成学习方法,解释了随机森林的工作原理,强调了有放回抽样的重要性,并简要提到了随机森林的API参数。最后,指出随机森林在降低过拟合风险和提高预测准确性方面的优势。
信息熵
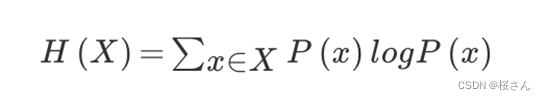
n种可能性,在不知道任何信息时,将信息砍半后进行选择,如有32支球队,判断拿纸球队会获胜时,首先选择16支获胜概率较大的球队,→8→4→2→1,共选择5次,因此信息熵为log32=5(默认以2为底)因为每次选择进行二选一。当这32支球队夺冠的几率相同时,对应的信息熵等于5比特
信息和消除不确定性是相联系的
决策树的划分依据之一-信息增益:特征A对训练数据集D的信息增益g(D,A),定义为集合D的信息熵H(D)与特征A给定条件下D的信息条件熵H(D|A)之差,即公式为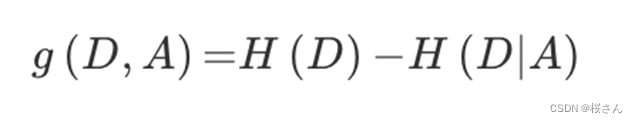
注:信息增益表示得知特征X的信息而使得类Y的信息的不确定性减少的程度
常见决策树使用的算法:
ID3
信息增益 最大的准则
C4.5
信息增益比 最大的准则
CART
回归树: 平方误差 最小
分类树: 基尼系数 最小的准则 在sklearn中可以选择划分的原则
sklearn决策树API
•
class
sklearn.tree.DecisionTreeClassifier
(
criterion=’
gini
’
,
max_depth
=
None
,
random_state
=None
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









