






sklearn数据集划分API
sklearn.model_selection.train_test_split
scikit-learn数据集API介绍
datasets.fetch_*(data_home=None)获取大规模数据集,需要从网络上下载,函数的第一个参数是data_home,表示数据集下载的目录,默认是 ~/scikit_learn_data/
获取数据集返回的类型
load*和fetch*返回的数据类型datasets.base.Bunch(字典格式)
data:特征数据数组,是 [n_samples * n_features] 的二维
numpy.ndarray 数组
target:标签数组,是 n_samples 的一维 numpy.ndarray 数组
DESCR:数据描述
feature_names:特征名,新闻数据,手写数字、回归数据集没有
target_names:标签名,回归数据集没有
from sklearn.datasets import load_iris,load_digits,fetch_20newsgroups
li=load_iris()
ld=load_digits()
print(li.data)#获取数据集,也就是特征值
print(li.target)#获取目标值
print(li.DESCR)#获取数据描述
print(li.feature_names)#获取特征值名称
print(li.target_names)#获取目标值名称,如有采样结果。相同的种子采样结果相同。
(默认随机取)
from sklearn.model_selection import train_test_split
'''返回值为:训练集:x_train,y_train 测试集:x_test,y_test ,x代表特征值,y代表目标值'''
'''返回顺序为,先特征值,后目标值'''
x_train,x_test,y_train,y_test=train_test_split(li.data,li.target,test_size=0.25)#传入数据的特征值及目标值,指定测试集的大小
'''训练集和测试集使用最多的比例为0.75:0.25'''
print('训练集的特征值和目标值为:',x_train,y_train)
print('测试集的特征值和目标值为:',x_test,y_test)用于分类的大数据集
训练集的“训练”,测试集的“测试”,两者的“全部”
from sklearn.datasets import fetch_20newsgroups#获取新闻文章数据集
news=fetch_20newsgroups(subset='all')#选择要获取的数据类型,是训练、测试还是全部
print(news.data)
print(news.target)转换器


标准化公式:
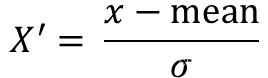
fit(X1)+transform(X2)==fit_transform()
当fit和transform分开使用时,fit中传入的x1会成为标准化公式中的基准值,计算该基准值的平均值及方差,transform中的x2数据会根据x1数据的平均值和方差进行数据的标准化转换,因此使用该公式时需注意,当x1=x2时无影响,当x1!=x2时要注意,可能会出现偏差,但是fit_transform仅传入一个数据,因此不会出现问题。
估计器

调用fit,对训练集进行学习,构造模型,然后将测试集数据输入模型,用predict进行预测,最后将得出的结果与实际结果进行比对,通过score来给模型的正确性进行打分















 764
764











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









