






前言
TOK问题乍一听,或许听着比较高大上,但是通过我下面的三个例题,相信同志们肯定会有不小的收获,以后再见到这一类问题,会有自己的想法。
其中对于tok问题,要牢记一句话(很重要哦):取大用小,取小用大!!!这句话在下面的例题中很有很深的体会的。
一、LeetCode最小K个数
首先大多数的而我们看到这个问题,觉着很简单啊,使用sort排序,然后输出最小的K个数就可以了。但是我们可以先看看题目= -- =.
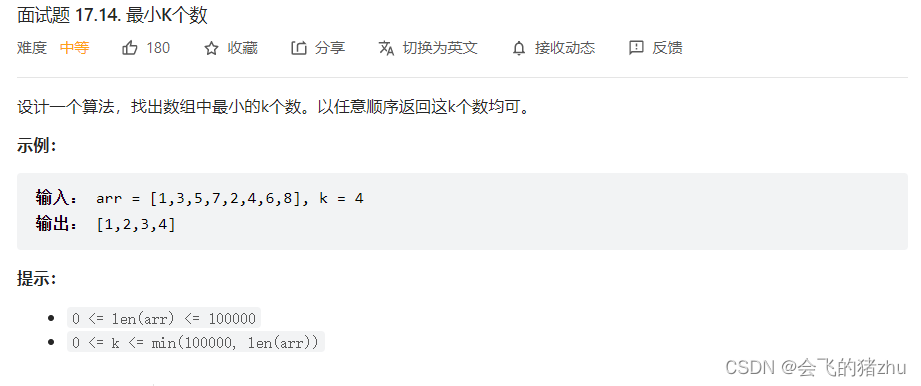
看到这题目,还是个中等难度,可能作者是想让我们使用别的方法。——没错。其实有些题目他们会有一些对于时间复杂度的限制,我们知道,最快的排序法,时间复杂度为O(nlogn),但对于这样的tok问题,我们的时间复杂度为O(nlogk),因为n肯定会大于k,所以时间复杂度变小了!
哈哈哈,不说废话了,先上代码,然后我再仔细的讲解一下。
public class Num17_14_SmallestK {
public int[] smallestK(int[] arr, int k) {
//取小用大
if(k==0||arr.length==0){
return new int[0];
}
//构造一个最大堆,JDK默认的是最小堆
Queue<Integer> queue=new PriorityQueue<>(new Comparator<Integer>() {
@Override
public int compare(Integer o1, Integer o2) {
return o2-o1;
}
});
for(int i:arr){
//维持最大堆的数量一直是K
if(queue.size()<k){
queue.offer(i);
}else{
if(i>queue.peek()){
continue;
}
queue.poll();
queue.offer(i);
}
}
int[] ret=new int[k];
for (int i = 0; i < k; i++) {
ret[i]=queue.poll();
}
return ret;
}
}
首先,我们使用优先级队列,创建了一个最大堆(就是后面的对象减去前面的对象相对应的值),这里直接使用匿名内部类传入了comparator接口的对象,然后对compare方法重写,实现了最大堆。
其次我们通过优先级队列维护了一个大小为K的堆,作为最后存储最小值的集合。那么头结点肯定是这个K个元素堆的最大值。当堆里放满了,就开始比较了:如果一个元素比堆的头结点还要大,那么他也就比堆里剩下的元素还要大,此时就不需要比较了,这也是为什么他的时间复杂度为O(nlogk)的原因。当然,如果一个元素比头结点小,那么就把头结点出队,这个元素入队。
二、LeetCode前K个高频元素
好,我们先看看题目:
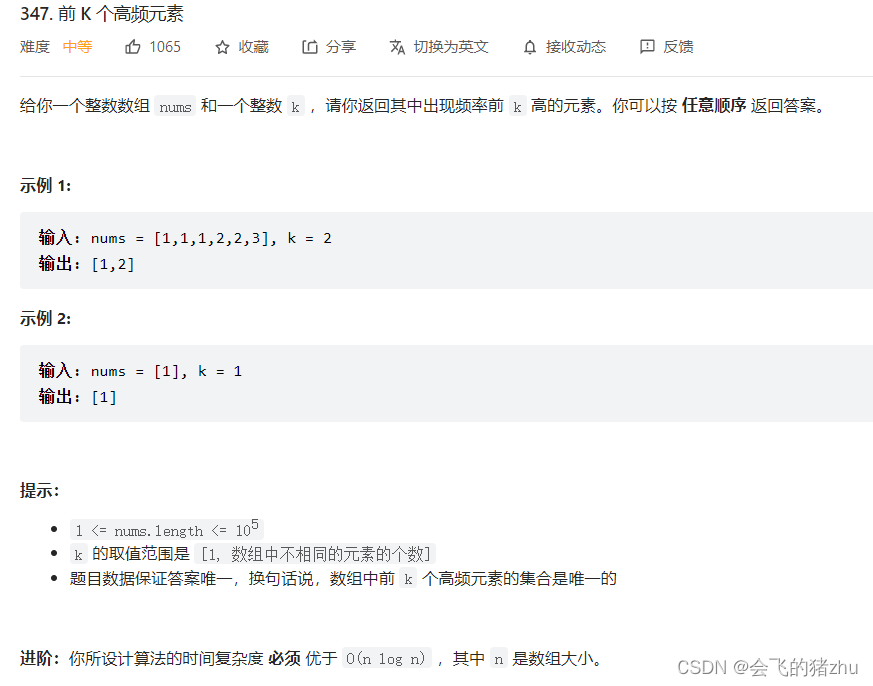
首先,此时人家要求了时间复杂度,所以肯定要使用优先级队列。又是因为前K个高频元素,所以我们使用最小堆来解决这个问题。
其次,我们要计算的是元素出现的次数,以及对应的元素,所以我们应该使用Map集合来记录每个元素以及相应的出现次数。
最后,我们要新建一个内部类,其成员变量包括每个元素及其对应的次数,然后把每个对象依次放入优先级队列中。
好了让我们看看下面的代码:
private class Freq{
private int key;
private int times;
public int getKey() {
return key;
}
public int getTimes() {
return times;
}
public Freq(int key, int times) {
this.key = key;
this.times = times;
}
}
public int[] topKFrequent(int[] nums, int k) {
int[] ret=new int[k];
Map<Integer,Integer> map=new HashMap<>();
for(int i:nums){
//这是一个简短的写法,不需要if、else了,
// map.put(i,map.getOrDefault(i,0)+1);
if(map.containsKey(i)){
//此时i已经存在map里面
map.put(i,map.get(i)+1);
}else{
//此时为第一次出现
map.put(i,1);
}
}
Queue<Freq> queue=new PriorityQueue<>(new Comparator<Freq>() {
@Override
public int compare(Freq o1, Freq o2) {
return o1.times-o2.times;
}
});
for(Map.Entry<Integer,Integer> entry:map.entrySet()){
if(queue.size()<k){
queue.offer(new Freq(entry.getKey(),entry.getValue()));
}else{
if(entry.getValue()<queue.peek().times){
continue;
}
queue.poll();
queue.offer(new Freq(entry.getKey(),entry.getValue()));
}
}
int i=0;
while(!queue.isEmpty()){
ret[i++]=queue.poll().getKey();
}
return ret;
}注意:
1.对于这里有个内部类,是为了保存元素与其出现的次数,以便于放入队列中方便比较(其实对于大部分此类型的题目,都需要自己写一个内部类方便解决问题)。
2.此时复写的compare方法里比较的是内部类对象中元素出现次数的大小。
3.对于Map集合的遍历,要转为Set集合然后使用for-each循环遍历。(主要是因为Map不是collection的子类,没有实现for-each方法)。然后将map里面的内容用于对内部类对象初始化,在依次存入最小堆中。
三、查找和最小的K对数字
这里我们先看看题目看看有没有一些想法
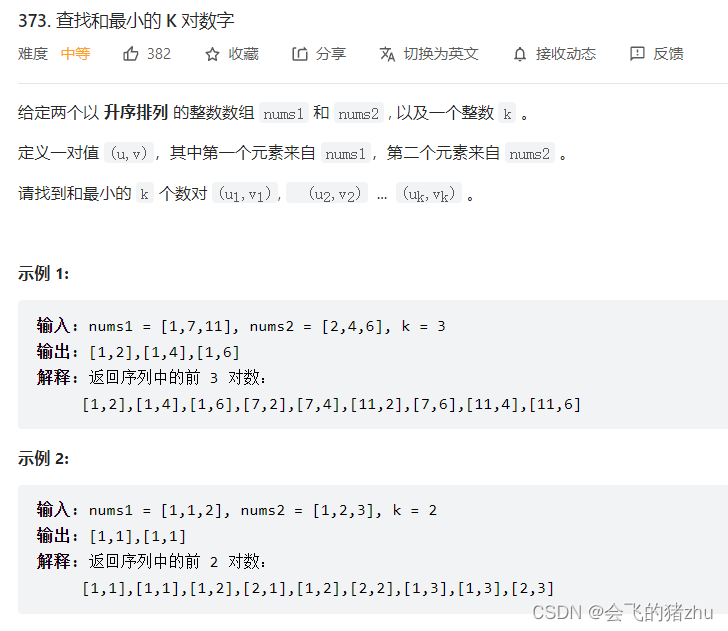
经过上面两个题,在看到这个题目,我们一定会想到使用最大堆,没错就是他!其次是要比较和,所以我们肯定还要在建立一个内部类来辅助我们更好的解决问题。好了我们先看看代码吧!!!
public class Num373_KSmallestPairs {
private class Pair{
int u;
int v;
public Pair(int u, int v) {
this.u = u;
this.v = v;
}
}
public List<List<Integer>> kSmallestPairs(int[] nums1, int[] nums2, int k) {
Queue<Pair> queue=new PriorityQueue<>(new Comparator<Pair>() {
@Override
public int compare(Pair o1, Pair o2) {
return (o2.u+o2.v)-(o1.u+o1.v);
}
});
for (int i = 0; i < Math.min(nums1.length,k); i++) {
for (int j = 0; j < Math.min(nums2.length,k); j++) {
if(queue.size()<k){
queue.offer(new Pair(nums1[i],nums2[j]));
}else{
int add=nums1[i]+nums2[j];
Pair pair=queue.peek();
if(add>(pair.u+ pair.v)){
continue;
}
queue.poll();
queue.offer(new Pair(nums1[i],nums2[j]));
}
}
}
List<List<Integer>> ret=new ArrayList<>();
for (int i = 0; !queue.isEmpty(); i++) {
List<Integer> tmp=new ArrayList<>();
Pair pair=queue.poll();
tmp.add(pair.u);
tmp.add(pair.v);
ret.add(tmp);
}
return ret;
}
}
当然大体的思路我么肯定都会明白一些,但还有些小小的细节:
1.对于复写compare方法时不要忘了是对象的两个成员变量的和相互比较。
2.在进行两个for循环是一定要注意是要去数组长度和K的最小值,这个虽然简单,但也容易写着写着迷糊,不要问我咋么知道的,因为我之前做题的时候也是,呜呜呜~~~
总结
通过上面三个例题我们可以知道,遇到求最大或最小的时候,我们首先向tok问题上去想。一定要牢记 取大用小,取小用大。
其次在应用问题上,我们要灵活的使用内部类、Map等帮助我们解决问题,达到我们的目的。好了这次的分享结束了,希望我们能相互鼓励,达到自己的梦想!!!

















 5万+
5万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









