






前言
现在扩散模型的生成能力十分惊艳,已经有许多下游任务开始利用扩散模型了。而其中stable diffusion的开源使得许多生成任务都是基于它之上,因此,想要利用stable diffusion做下游任务,其源码阅读成为了必不可少的工作。然而,源码的内容繁杂,层层嵌套之下,使其阅读起来十分费力。针对该问题,写下了这篇博客,旨在简化stable diffusion的代码,让大家更加容易理解其内在逻辑,轻松将预训练模型用在自己的目标任务之上。精简版的代码是利用预训练的stable diffusion模型来做txt2img和img2img任务,其被放在代码仓库中。链接如下:
wenyu427/sample-stable-diffusion at master (github.com)
知识准备
扩散模型是一个马尔科夫链式结构。其前向过程是高斯线性变换,即向图片中一步步加噪声,并最终变成一个随机高斯变量
。其逆过程就是从一个纯粹的高斯噪声(标准高斯分布)中逐步剔除噪声并最终得到一个真实图片。具体过程如图所示:
(图源:https://doi.org/10.48550/arXiv.2208.11970)
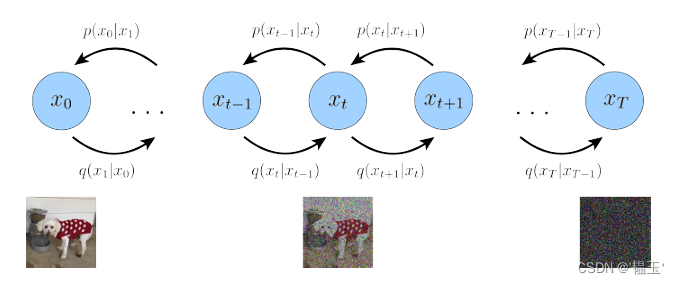
图1
因为本博客的主要目的是利用源码,所以关于扩散模型前向过程和逆向过程的公式推导,在这里不具体展开。下面将给出扩散模型必备的公式,这有助于代码的阅读。
1. 扩散概率模型(diffusion probabilistic models)
前向扩散过程
如图1,前向过程是从左向右,其定义如下:
(式1)
根据高斯分布的性质,等价为:
(式2)
其中,,
是人为设定的超参数,
。
通过归纳法,前向过程中任意时刻的分布可以由以下公式得到
(式3)
其中,.
逆向扩散过程
图1中的从右向左,即计算,但是直接计算是不可行的,故转而求
。
是一个概率分布,其均值和方差如下:
(式4)
(式5)
有了均值和方差,我们就可以进行采样了。
降噪扩散概率模型(DDPM)
原始DPM是预测 ,而DDPM是预测每一个时刻添加的噪声,这降低了模型的学习难度。
改写式3,可以得到:
(式6)
将式5,代入式4可以得到:
(式7)
注意,,等价于:
(式8)
这里直接给出,损失函数:
(式9)
DDIM
DDIM 重新定义了扩散过程和逆过程,并提出了一种新的采样技巧, 可以大幅减少采样的步骤。
式(10)
其中,是人为指定的。当
为0时,相当于直接输出的
时刻分布的均值,不进行采样。
PLMS采样器
采样公式如下:
式11
Classifier-free guidence
需要进行两次前向过程,分别得到有条件引导和无条件引导预测的噪声:
noise-uncond = forward(xt, t)
noise-cond = forward(ct, t, c)
noise = noise-uncond+w*(noise-cond - noise-uncond)
w为无条件引导的权重参数
2. 潜在扩散模型
潜在扩散模型的架构图,如下所示:(图源: https://doi.org/10.48550/arXiv.2112.10752)
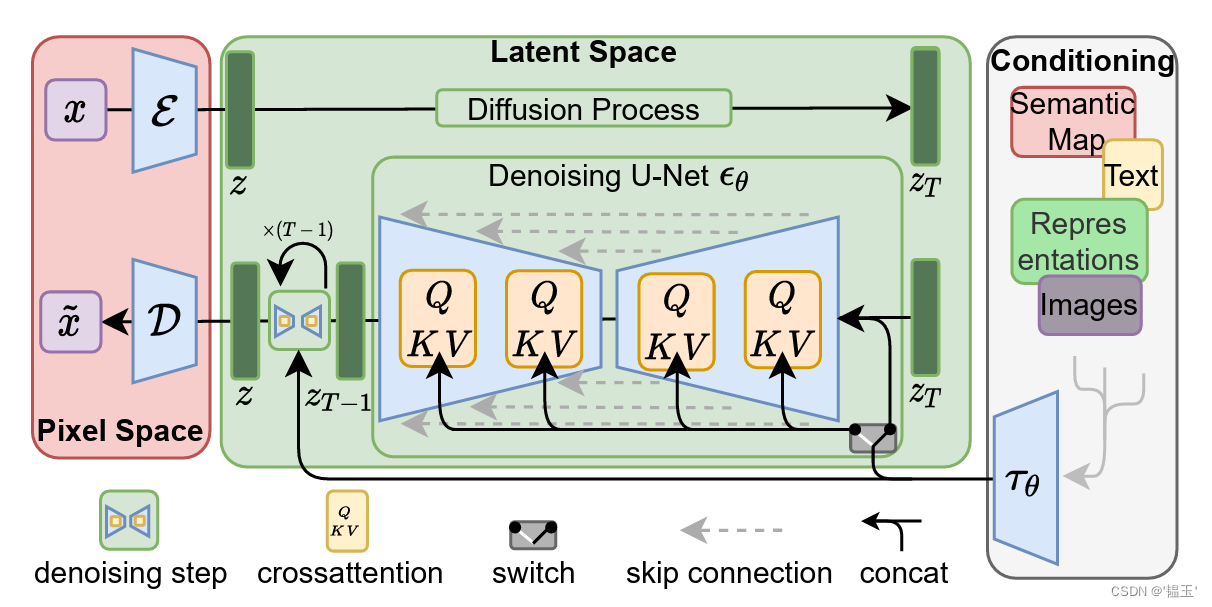
图2
如图2所示,潜在扩散模型包括:自编码器,U-net网络和条件网络。
自编码器将图像下采样8倍,得到图像的潜在表征。
U-Net用来预测t时刻的噪声,包含resnet block和attention
条件网络用来得到条件向量,控制图像的生成,如clip-text encoder。
源码解读
接下来,我们进入到stable diffusion v1源码的解读模块。由于源码内容十分复杂,我们不可能一句一句代码的来看,也不可能将代码全部放到博客里。因此,我会在将代码托管到仓库,而在博客里主要梳理代码的框架,理清其逻辑,方便大家对源码的阅读。需要指出的是,这里的代码是ComVis提供源码的精简版本,将大量不需要的条件判断,日志输出等内容进行了删除,以缩减代码总量,简化阅读负担。经过反复调试,txt2img和img2img的推断可以正常运行,大家可以方便利用其进行下游任务的工作。
1. 自编码器(AutoencoderKL)
自编码器包括编码器和解码器。编码器将图像编码为潜在特征z,而解码器则将z恢复回原始图像。
自编码器的定义如下,这里列出了主要的函数,即初始化,编码,解码和前向过程:
AutoEncoder
class AutoencoderKL(pl.LightningModule):
def __init__(self,
ddconfig,
lossconfig,
embed_dim,
ckpt_path=None,
ignore_keys=[],
image_key="image",
colorize_nlabels=None,
monitor=None,
):
super().__init__()
self.image_key = image_key
self.encoder = Encoder(**ddconfig)
self.decoder = Decoder(**ddconfig)
self.loss = instantiate_from_config(lossconfig)
assert ddconfig["double_z"]
self.quant_conv = torch.nn.Conv2d(2*ddconfig["z_channels"], 2*embed_dim, 1)
self.post_quant_conv = torch.nn.Conv2d(embed_dim, ddconfig["z_channels"], 1)
self.embed_dim = embed_dim
if colorize_nlabels is not None:
assert type(colorize_nlabels)==int
self.register_buffer("colorize", torch.randn(3, colorize_nlabels, 1, 1))
if monitor is not None:
self.monitor = monitor
if ckpt_path is not None:
self.init_from_ckpt(ckpt_path, ignore_keys=ignore_keys)
def encode(self, x):
h = self.encoder(x)
moments = self.quant_conv(h)
posterior = DiagonalGaussianDistribution(moments)
return posterior
def decode(self, z):
z = self.post_quant_conv(z)
dec = self.decoder(z)
return dec
def forward(self, input, sample_posterior=True):
posterior = self.encode(input)
if sample_posterior:
z = posterior.sample()
else:
z = posterior.mode()
dec = self.decode(z)
return dec, posterior
其中,编码器是ResnetBlock,Downsample和Attention模块的堆叠。解码器是ResnetBlock,Upsample和Attention模块的堆叠。
ResnetBlock
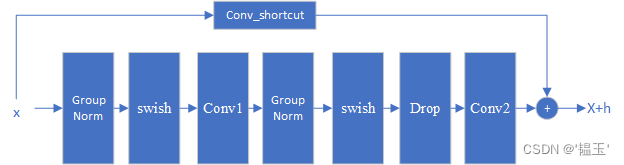
注意:ResnetBlock并不改变特征图的大小
class ResnetBlock(nn.Module):
def __init__(self, *, in_channels, out_channels=None, conv_shortcut=False,
dropout, temb_channels=512):
super().__init__()
self.in_channels = in_channels
out_channels = in_channels if out_channels is None else out_channels
self.out_channels = out_channels
self.use_conv_shortcut = conv_shortcut
self.norm1 = Normalize(in_channels)
self.conv1 = torch.nn.Conv2d(in_channels,
out_channels,
kernel_size=3,
stride=1,
padding=1)
self.norm2 = Normalize(out_channels)
self.dropout = torch.nn.Dropout(dropout)
self.conv2 = torch.nn.Conv2d(out_channels,
out_channels,
kernel_size=3,
stride=1,
padding=1)
if self.in_channels != self.out_channels:
if self.use_conv_shortcut:
self.conv_shortcut = torch.nn.Conv2d(in_channels, out_channels,
kernel_size=3,
stride=1,
padding=1)
def forward(self, x, temb):
h = x
h = self.norm1(h)
h = nonlinearity(h)
h = self.conv1(h)
if temb is not None:
h = h + self.temb_proj(nonlinearity(temb))[:,:,None,None]
h = self.norm2(h)
h = nonlinearity(h)
h = self.dropout(h)
h = self.conv2(h)
if self.in_channels != self.out_channels:
if self.use_conv_shortcut:
x = self.conv_shortcut(x)
else:
x = self.nin_shortcut(x)
return x+h
class Upsample(nn.Module):
def __init__(self, in_channels, with_conv):
super().__init__()
self.with_conv = with_conv
if self.with_conv:
self.conv = torch.nn.Conv2d(in_channels,
in_channels,
kernel_size=3,
stride=1,
padding=1)
def forward(self, x):
x = torch.nn.functional.interpolate(x, scale_factor=2.0, mode="nearest")
if self.with_conv:
x = self.conv(x)
return x
class Downsample(nn.Module):
def __init__(self, in_channels, with_conv):
super().__init__()
self.with_conv = with_conv
if self.with_conv:
# no asymmetric padding in torch conv, must do it ourselves
self.conv = torch.nn.Conv2d(in_channels,
in_channels,
kernel_size=3,
stride=2,
padding=0)
def forward(self, x):
if self.with_conv:
pad = (0,1,0,1)
x = torch.nn.functional.pad(x, pad, mode="constant", value=0)
x = self.conv(x)
else:
x = torch.nn.functional.avg_pool2d(x, kernel_size=2, stride=2)
return xAttention
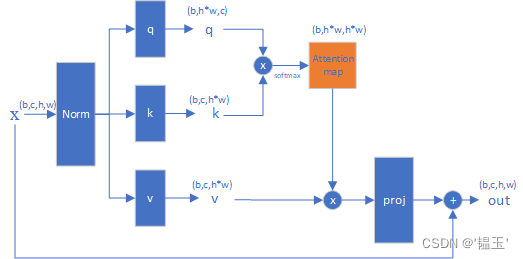
class AttnBlock(nn.Module):
def __init__(self, in_channels):
super().__init__()
self.in_channels = in_channels
self.norm = Normalize(in_channels)
self.q = torch.nn.Conv2d(in_channels,in_channels, kernel_size=1, stride=1, padding=0)
self.k = torch.nn.Conv2d(in_channels,in_channels, kernel_size=1, stride=1, padding=0)
self.v = torch.nn.Conv2d(in_channels,in_channels, kernel_size=1, stride=1, padding=0)
self.proj_out = torch.nn.Conv2d(in_channels, in_channels, kernel_size=1, stride=1, padding=0)
def forward(self, x):
h_ = x
h_ = self.norm(h_)
q = self.q(h_)
k = self.k(h_)
v = self.v(h_)
# compute attention
b,c,h,w = q.shape
q = q.reshape(b,c,h*w)
q = q.permute(0,2,1) # b,hw,c
k = k.reshape(b,c,h*w) # b,c,hw
w_ = torch.bmm(q,k) # b,hw,hw w[b,i,j]=sum_c q[b,i,c]k[b,c,j]
w_ = w_ * (int(c)**(-0.5))
w_ = torch.nn.functional.softmax(w_, dim=2)
# attend to values
v = v.reshape(b,c,h*w)
w_ = w_.permute(0,2,1) # b,hw,hw (first hw of k, second of q)
h_ = torch.bmm(v,w_) # b, c,hw (hw of q) h_[b,c,j] = sum_i v[b,c,i] w_[b,i,j]
h_ = h_.reshape(b,c,h,w)
h_ = self.proj_out(h_)
return x+h_Encoder
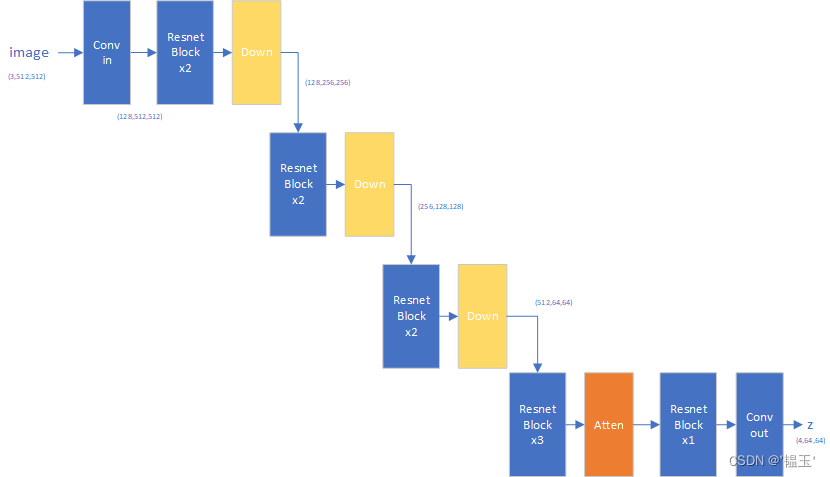
Decoder
decoder的结构与encoder是对称的。
2. U-Net
U-Net作为噪声预测网络,包括上采样,下采样,ResNetBlock,Attention。
上下采样:
class Upsample(nn.Module):
"""
An upsampling layer with an optional convolution.
:param channels: channels in the inputs and outputs.
:param use_conv: a bool determining if a convolution is applied.
:param dims: determines if the signal is 1D, 2D, or 3D. If 3D, then
upsampling occurs in the inner-two dimensions.
"""
def __init__(self, channels, use_conv, dims=2, out_channels=None, padding=1):
super().__init__()
self.channels = channels
self.out_channels = out_channels or channels
self.use_conv = use_conv
self.dims = dims
if use_conv:
self.conv = conv_nd(dims, self.channels, self.out_channels, 3, padding=padding)
def forward(self, x):
assert x.shape[1] == self.channels
if self.dims == 3:
x = F.interpolate(
x, (x.shape[2], x.shape[3] * 2, x.shape[4] * 2), mode="nearest"
)
else:
x = F.interpolate(x, scale_factor=2, mode="nearest")
if self.use_conv:
x = self.conv(x)
return x
class Downsample(nn.Module):
"""
A downsampling layer with an optional convolution.
:param channels: channels in the inputs and outputs.
:param use_conv: a bool determining if a convolution is applied.
:param dims: determines if the signal is 1D, 2D, or 3D. If 3D, then
downsampling occurs in the inner-two dimensions.
"""
def __init__(self, channels, use_conv, dims=2, out_channels=None,padding=1):
super().__init__()
self.channels = channels
self.out_channels = out_channels or channels
self.use_conv = use_conv
self.dims = dims
stride = 2 if dims != 3 else (1, 2, 2)
if use_conv:
self.op = conv_nd(
dims, self.channels, self.out_channels, 3, stride=stride, padding=padding
)
else:
assert self.channels == self.out_channels
self.op = avg_pool_nd(dims, kernel_size=stride, stride=stride)
def forward(self, x):
assert x.shape[1] == self.channels
return self.op(x)ResNstBlock
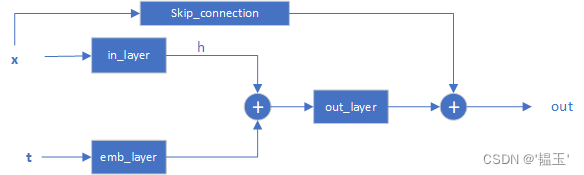
class TimestepBlock(nn.Module):
"""
Any module where forward() takes timestep embeddings as a second argument.
"""
@abstractmethod
def forward(self, x, emb):
"""
Apply the module to `x` given `emb` timestep embeddings.
"""
class ResBlock(TimestepBlock):
"""
A residual block that can optionally change the number of channels.
:param channels: the number of input channels.
:param emb_channels: the number of timestep embedding channels.
:param dropout: the rate of dropout.
:param out_channels: if specified, the number of out channels.
:param use_conv: if True and out_channels is specified, use a spatial
convolution instead of a smaller 1x1 convolution to change the
channels in the skip connection.
:param dims: determines if the signal is 1D, 2D, or 3D.
:param use_checkpoint: if True, use gradient checkpointing on this module.
:param up: if True, use this block for upsampling.
:param down: if True, use this block for downsampling.
"""
def __init__(
self,
channels,
emb_channels,
dropout,
out_channels=None,
use_conv=False,
use_scale_shift_norm=False,
dims=2,
use_checkpoint=False,
up=False,
down=False,
):
super().__init__()
self.channels = channels
self.emb_channels = emb_channels
self.dropout = dropout
self.out_channels = out_channels or channels
self.use_conv = use_conv
self.use_checkpoint = use_checkpoint
self.use_scale_shift_norm = use_scale_shift_norm
self.in_layers = nn.Sequential(
normalization(channels),
nn.SiLU(),
conv_nd(dims, channels, self.out_channels, 3, padding=1),
)
self.updown = up or down
if up:
self.h_upd = Upsample(channels, False, dims)
self.x_upd = Upsample(channels, False, dims)
elif down:
self.h_upd = Downsample(channels, False, dims)
self.x_upd = Downsample(channels, False, dims)
else:
self.h_upd = self.x_upd = nn.Identity()
self.emb_layers = nn.Sequential(
nn.SiLU(),
linear(
emb_channels,
2 * self.out_channels if use_scale_shift_norm else self.out_channels,
),
)
self.out_layers = nn.Sequential(
normalization(self.out_channels),
nn.SiLU(),
nn.Dropout(p=dropout),
zero_module(
conv_nd(dims, self.out_channels, self.out_channels, 3, padding=1)
),
)
if self.out_channels == channels:
self.skip_connection = nn.Identity()
elif use_conv:
self.skip_connection = conv_nd(
dims, channels, self.out_channels, 3, padding=1
)
else:
self.skip_connection = conv_nd(dims, channels, self.out_channels, 1)
def forward(self, x, emb):
if self.updown:
in_rest, in_conv = self.in_layers[:-1], self.in_layers[-1]
h = in_rest(x)
h = self.h_upd(h)
x = self.x_upd(x)
h = in_conv(h)
else:
h = self.in_layers(x)
emb_out = self.emb_layers(emb).type(h.dtype)
while len(emb_out.shape) < len(h.shape):
emb_out = emb_out[..., None]
if self.use_scale_shift_norm:
out_norm, out_rest = self.out_layers[0], self.out_layers[1:]
scale, shift = th.chunk(emb_out, 2, dim=1)
h = out_norm(h) * (1 + scale) + shift
h = out_rest(h)
else:
h = h + emb_out
h = self.out_layers(h)
return self.skip_connection(x) + h
SpatialTransformer
交叉注意在SpatialTransformer模块由多层TransformerBlock组成。TransformerBlock包含CrossAttention和FeedForward。在CrossAttention层里引入了条件引导。
class BasicTransformerBlock(nn.Module):
def __init__(self, dim, n_heads, d_head, dropout=0., context_dim=None, gated_ff=True, checkpoint=True):
super().__init__()
self.attn1 = CrossAttention(query_dim=dim, heads=n_heads, dim_head=d_head, dropout=dropout) # is a self-attention
self.ff = FeedForward(dim, dropout=dropout, glu=gated_ff)
self.attn2 = CrossAttention(query_dim=dim, context_dim=context_dim,
heads=n_heads, dim_head=d_head, dropout=dropout) # is self-attn if context is none
self.norm1 = nn.LayerNorm(dim)
self.norm2 = nn.LayerNorm(dim)
self.norm3 = nn.LayerNorm(dim)
self.checkpoint = checkpoint
def forward(self, x, context=None):
x = self.attn1(self.norm1(x)) + x
x = self.attn2(self.norm2(x), context=context) + x
x = self.ff(self.norm3(x)) + x
return xCrossAttention
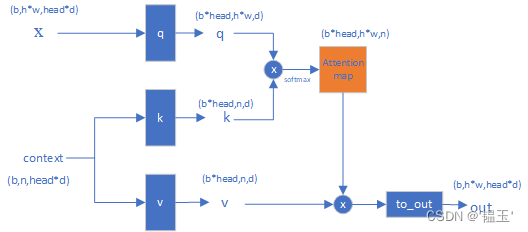
class CrossAttention(nn.Module):
def __init__(self, query_dim, context_dim=None, heads=8, dim_head=64, dropout=0.):
super().__init__()
inner_dim = dim_head * heads
context_dim = default(context_dim, query_dim)
self.scale = dim_head ** -0.5
self.heads = heads
self.to_q = nn.Linear(query_dim, inner_dim, bias=False)
self.to_k = nn.Linear(context_dim, inner_dim, bias=False)
self.to_v = nn.Linear(context_dim, inner_dim, bias=False)
self.to_out = nn.Sequential(
nn.Linear(inner_dim, query_dim),
nn.Dropout(dropout)
)
def forward(self, x, context=None, mask=None):
h = self.heads
q = self.to_q(x)
context = default(context, x)
k = self.to_k(context)
v = self.to_v(context)
q, k, v = map(lambda t: rearrange(t, 'b n (h d) -> (b h) n d', h=h), (q, k, v))
sim = einsum('b i d, b j d -> b i j', q, k) * self.scale
if exists(mask):
mask = rearrange(mask, 'b ... -> b (...)')
max_neg_value = -torch.finfo(sim.dtype).max
mask = repeat(mask, 'b j -> (b h) () j', h=h)
sim.masked_fill_(~mask, max_neg_value)
# attention, what we cannot get enough of
attn = sim.softmax(dim=-1)
out = einsum('b i j, b j d -> b i d', attn, v)
out = rearrange(out, '(b h) n d -> b n (h d)', h=h)
return self.to_out(out)
SpatialTransformer 就是多个 BasicTransformerBlock的叠加。
class SpatialTransformer(nn.Module):
"""
Transformer block for image-like data.
First, project the input (aka embedding)
and reshape to b, t, d.
Then apply standard transformer action.
Finally, reshape to image
"""
def __init__(self, in_channels, n_heads, d_head,
depth=1, dropout=0., context_dim=None):
super().__init__()
self.in_channels = in_channels
inner_dim = n_heads * d_head
self.norm = Normalize(in_channels)
self.proj_in = nn.Conv2d(in_channels,
inner_dim,
kernel_size=1,
stride=1,
padding=0)
self.transformer_blocks = nn.ModuleList(
[BasicTransformerBlock(inner_dim, n_heads, d_head, dropout=dropout, context_dim=context_dim)
for d in range(depth)]
)
self.proj_out = zero_module(nn.Conv2d(inner_dim,
in_channels,
kernel_size=1,
stride=1,
padding=0))
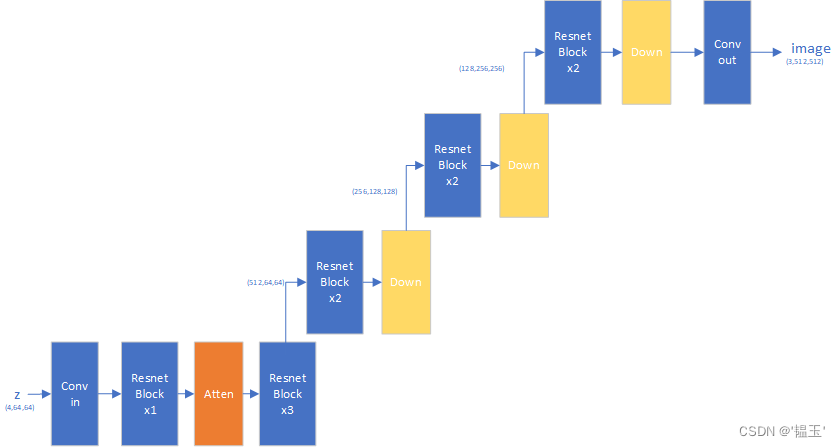
U-Net
最终的U-Net结构如下:
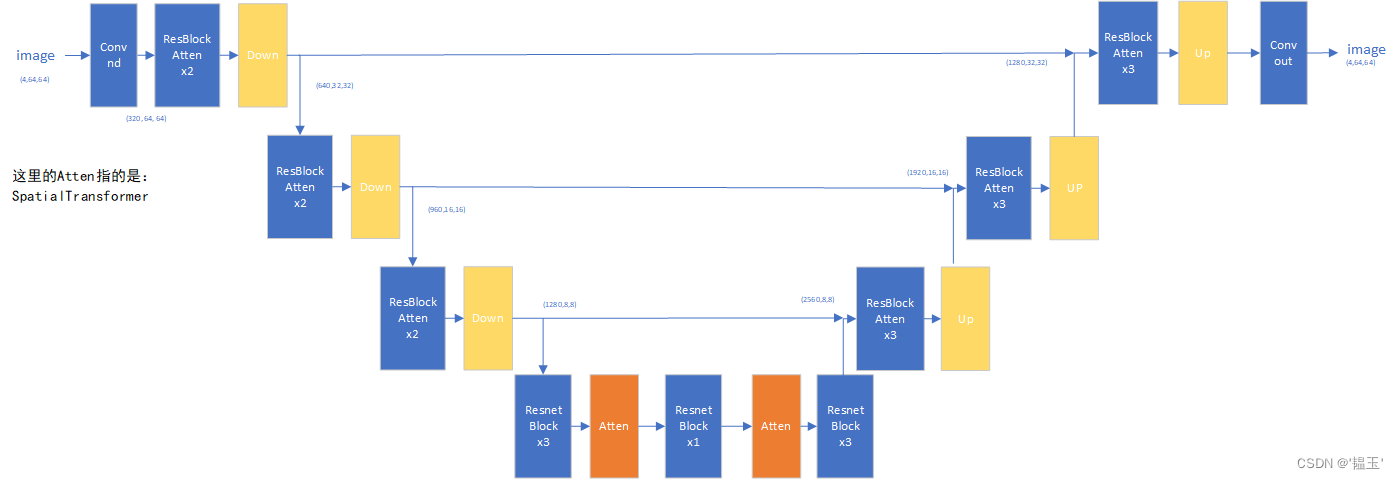
3. 条件网络
这里的条件向量,使用的就是clip的文本嵌入。 last_hidden_state: [1, 77, 768] pooler_output: [1, 768]
class FrozenCLIPEmbedder(AbstractEncoder):
"""Uses the CLIP transformer encoder for text (from Hugging Face)
"""
def __init__(self, version="openai/clip-vit-large-patch14",
device="cuda", max_length=77):
super().__init__()
self.tokenizer = CLIPTokenizer.from_pretrained(version, local_files_only=True)
self.transformer = CLIPTextModel.from_pretrained(version, local_files_only=True)
self.device = device
self.max_length = max_length
self.freeze()
def freeze(self):
self.transformer = self.transformer.eval()
for param in self.parameters():
param.requires_grad = False
def forward(self, text):
batch_encoding = self.tokenizer(text, truncation=True, max_length=self.max_length, return_length=True,
return_overflowing_tokens=False, padding="max_length", return_tensors="pt")
tokens = batch_encoding["input_ids"].to(self.device)
outputs = self.transformer(input_ids=tokens)
z = outputs.last_hidden_state # last_hidden_state: [1, 77, 768]; pooler_output: [1, 768]
return z4. LatentDiffusion
下面是latent diffusion简化后的逻辑。
首先是初始化,和注册变量。这里的LatentDiffusion继承DDPM,而在LatentDiffusion中主要使用了DDPM的self.register_schedule()注册变量。这些变量是方便扩散模型前向过程和方向过程的计算。
# DDPM中使用了下面这条命令来实例化U-Net模型,好处是这样可以处理不同的条件输入。
self.model = DiffusionWrapper(unet_config, conditioning_key)
class DiffusionWrapper(pl.LightningModule):
def __init__(self, diff_model_config):
super().__init__()
self.diffusion_model = instantiate_from_config(diff_model_config)
def forward(self, x, t, c_concat: list = None, c_crossattn: list = None):
cc = torch.cat(c_crossattn, 1)
out = self.diffusion_model(x, t, context=cc)
return out还需要实例化的网络:
# 这里用来实例化自编码器
self.instantiate_first_stage(first_stage_config)
# 这里用来实例化条件网络clip
self.instantiate_cond_stage(cond_stage_config)
class DDPM(pl.LightningModule):
# classic DDPM with Gaussian diffusion, in image space
def __init__(self,
unet_config,
timesteps=1000,
beta_schedule="linear",
loss_type="l2",
ckpt_path=None,
linear_start=1e-4,
linear_end=2e-2,
cosine_s=8e-3,
conditioning_key=None,
**kwargs):
super().__init__()
self.model = DiffusionWrapper(unet_config, conditioning_key)
if ckpt_path is not None:
self.init_from_ckpt(ckpt_path, ignore_keys=ignore_keys, only_model=load_only_unet)
self.register_schedule(given_betas=given_betas, beta_schedule=beta_schedule, timesteps=timesteps,
linear_start=linear_start, linear_end=linear_end, cosine_s=cosine_s)
self.loss_type = loss_type
def register_schedule(self, given_betas=None, beta_schedule="linear", timesteps=1000,
linear_start=1e-4, linear_end=2e-2, cosine_s=8e-3):
if exists(given_betas):
betas = given_betas
else:
betas = make_beta_schedule(beta_schedule, timesteps, linear_start=linear_start, linear_end=linear_end,
cosine_s=cosine_s)
alphas = 1. - betas
alphas_cumprod = np.cumprod(alphas, axis=0)
alphas_cumprod_prev = np.append(1., alphas_cumprod[:-1])
timesteps, = betas.shape
self.num_timesteps = int(timesteps)
self.linear_start = linear_start
self.linear_end = linear_end
assert alphas_cumprod.shape[0] == self.num_timesteps, 'alphas have to be defined for each timestep'
to_torch = partial(torch.tensor, dtype=torch.float32)
self.register_buffer('betas', to_torch(betas))
self.register_buffer('alphas_cumprod', to_torch(alphas_cumprod))
self.register_buffer('alphas_cumprod_prev', to_torch(alphas_cumprod_prev))
# calculations for diffusion q(x_t | x_{t-1}) and others
self.register_buffer('sqrt_alphas_cumprod', to_torch(np.sqrt(alphas_cumprod)))
self.register_buffer('sqrt_one_minus_alphas_cumprod', to_torch(np.sqrt(1. - alphas_cumprod)))
self.register_buffer('log_one_minus_alphas_cumprod', to_torch(np.log(1. - alphas_cumprod)))
self.register_buffer('sqrt_recip_alphas_cumprod', to_torch(np.sqrt(1. / alphas_cumprod)))
self.register_buffer('sqrt_recipm1_alphas_cumprod', to_torch(np.sqrt(1. / alphas_cumprod - 1)))
# calculations for posterior q(x_{t-1} | x_t, x_0)
posterior_variance = (1 - self.v_posterior) * betas * (1. - alphas_cumprod_prev) / (
1. - alphas_cumprod) + self.v_posterior * betas
# above: equal to 1. / (1. / (1. - alpha_cumprod_tm1) + alpha_t / beta_t)
self.register_buffer('posterior_variance', to_torch(posterior_variance))
# below: log calculation clipped because the posterior variance is 0 at the beginning of the diffusion chain
self.register_buffer('posterior_log_variance_clipped', to_torch(np.log(np.maximum(posterior_variance, 1e-20))))
self.register_buffer('posterior_mean_coef1', to_torch(
betas * np.sqrt(alphas_cumprod_prev) / (1. - alphas_cumprod))) # x0
self.register_buffer('posterior_mean_coef2', to_torch(
(1. - alphas_cumprod_prev) * np.sqrt(alphas) / (1. - alphas_cumprod))) # xt
class LatentDiffusion(DDPM):
"""main class
"""
def __init__(self,
first_stage_config,
cond_stage_config,
num_timesteps_cond=None,
cond_stage_key="image",
cond_stage_trainable=False,
concat_mode=True,
cond_stage_forward=None,
conditioning_key=None,
scale_factor=1.0,
scale_by_std=False,
*args, **kwargs):
super().__init__(conditioning_key=conditioning_key, *args, **kwargs)
self.concat_mode = concat_mode
self.cond_stage_trainable = cond_stage_trainable
self.cond_stage_key = cond_stage_key
try:
self.num_downs = len(first_stage_config.params.ddconfig.ch_mult) - 1
except:
self.num_downs = 0
if not scale_by_std:
self.scale_factor = scale_factor
else:
self.register_buffer('scale_factor', torch.tensor(scale_factor))
self.instantiate_first_stage(first_stage_config)
self.instantiate_cond_stage(cond_stage_config)
self.cond_stage_forward = cond_stage_forward
self.clip_denoised = False
self.bbox_tokenizer = None
self.register_schedule()
self.restarted_from_ckpt = False
if ckpt_path is not None:
self.init_from_ckpt(ckpt_path, ignore_keys)
self.restarted_from_ckpt = True
def register_schedule(self,
given_betas=None, beta_schedule="linear", timesteps=1000,
linear_start=1e-4, linear_end=2e-2, cosine_s=8e-3):
super().register_schedule(given_betas, beta_schedule, timesteps, linear_start, linear_end, cosine_s)
def instantiate_first_stage(self, config):
model = instantiate_from_config(config)
self.first_stage_model = model.eval()
for param in self.first_stage_model.parameters():
param.requires_grad = False
def instantiate_cond_stage(self, config):
model = instantiate_from_config(config)
self.cond_stage_model = model.eval()
for param in self.cond_stage_model.parameters():
param.requires_grad = False
def get_learned_conditioning(self, c):
return self.cond_stage_model.encode(c)
@torch.no_grad()
def decode_first_stage(self, z, predict_cids=False, force_not_quantize=False):
z = 1. / self.scale_factor * z
return self.first_stage_model.decode(z)
def apply_model(self, x_noisy, t, cond, return_ids=False):
cond = {'c_crossattn': [cond]}
x_recon = self.model(x_noisy, t, **cond)
return x_recon
5. 采样
采用了PLMS采样器,其类定义如下:
其中,make_schedule用来注册计算所需变量。sample()用来采样,它调用了plms_sampling()方法,而plms_sampling()循环调用了p_sample_plms()方法来得到最终图片。
class PLMSSampler(object):
def __init__(self, model, schedule="linear", **kwargs):
super().__init__()
self.model = model
self.ddpm_num_timesteps = model.num_timesteps
self.schedule = schedule
def register_buffer(...):
def make_schedule(...):
def sample(...):
...
samples = self.plms_sampling(.....)
return samples
def plms_sampling(...):
...
img, pred_x0, e_t = self.p_sample_plms(.....)
return img
def p_sample_plms(...):
...
return x_prev, pred_x0, e_t因此,采样的核心逻辑在p_sample_plms函数。让我们来看一下:
get_model_output(x, t),根据调用了latent diffusion中的apply_model来得到预测噪声e_t。 unconditional_guidance_scale != 1时使用classifer free guidence,需要进行两次前向过程的到有条件引导和无条件引导的预测结果。
get_x_prev_and_pred_x0()根据预测的结果e_t,得到和
.
def p_sample_plms(self, x, c, t, index, repeat_noise=False, use_original_steps=False, quantize_denoised=False,
temperature=1., noise_dropout=0., score_corrector=None, corrector_kwargs=None,
unconditional_guidance_scale=1., unconditional_conditioning=None, old_eps=None, t_next=None):
b, *_, device = *x.shape, x.device
def get_model_output(x, t):
if unconditional_conditioning is None or unconditional_guidance_scale == 1.:
e_t = self.model.apply_model(x, t, c)
else:
x_in = torch.cat([x] * 2)
t_in = torch.cat([t] * 2)
c_in = torch.cat([unconditional_conditioning, c])
e_t_uncond, e_t = self.model.apply_model(x_in, t_in, c_in).chunk(2)
e_t = e_t_uncond + unconditional_guidance_scale * (e_t - e_t_uncond)
if score_corrector is not None:
assert self.model.parameterization == "eps"
e_t = score_corrector.modify_score(self.model, e_t, x, t, c, **corrector_kwargs)
return e_t
alphas = self.model.alphas_cumprod if use_original_steps else self.ddim_alphas
alphas_prev = self.model.alphas_cumprod_prev if use_original_steps else self.ddim_alphas_prev
sqrt_one_minus_alphas = self.model.sqrt_one_minus_alphas_cumprod if use_original_steps else self.ddim_sqrt_one_minus_alphas
sigmas = self.model.ddim_sigmas_for_original_num_steps if use_original_steps else self.ddim_sigmas
def get_x_prev_and_pred_x0(e_t, index):
# select parameters corresponding to the currently considered timestep
a_t = torch.full((b, 1, 1, 1), alphas[index], device=device)
a_prev = torch.full((b, 1, 1, 1), alphas_prev[index], device=device)
sigma_t = torch.full((b, 1, 1, 1), sigmas[index], device=device)
sqrt_one_minus_at = torch.full((b, 1, 1, 1), sqrt_one_minus_alphas[index],device=device)
# current prediction for x_0
pred_x0 = (x - sqrt_one_minus_at * e_t) / a_t.sqrt()
if quantize_denoised:
pred_x0, _, *_ = self.model.first_stage_model.quantize(pred_x0)
# direction pointing to x_t
dir_xt = (1. - a_prev - sigma_t**2).sqrt() * e_t
noise = sigma_t * noise_like(x.shape, device, repeat_noise) * temperature
if noise_dropout > 0.:
noise = torch.nn.functional.dropout(noise, p=noise_dropout)
x_prev = a_prev.sqrt() * pred_x0 + dir_xt + noise
return x_prev, pred_x0
e_t = get_model_output(x, t)
if len(old_eps) == 0:
# Pseudo Improved Euler (2nd order)
x_prev, pred_x0 = get_x_prev_and_pred_x0(e_t, index)
e_t_next = get_model_output(x_prev, t_next)
e_t_prime = (e_t + e_t_next) / 2
elif len(old_eps) == 1:
# 2nd order Pseudo Linear Multistep (Adams-Bashforth)
e_t_prime = (3 * e_t - old_eps[-1]) / 2
elif len(old_eps) == 2:
# 3nd order Pseudo Linear Multistep (Adams-Bashforth)
e_t_prime = (23 * e_t - 16 * old_eps[-1] + 5 * old_eps[-2]) / 12
elif len(old_eps) >= 3:
# 4nd order Pseudo Linear Multistep (Adams-Bashforth)
e_t_prime = (55 * e_t - 59 * old_eps[-1] + 37 * old_eps[-2] - 9 * old_eps[-3]) / 24
x_prev, pred_x0 = get_x_prev_and_pred_x0(e_t_prime, index)
return x_prev, pred_x0, e_t至此,我们终于回顾完了stable diffusion的代码。

















 4896
4896

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









