






今天,我给大家分享一个使用“ReActor”插件来进行视频换脸的案例。

视频换脸的思路其实也很简单,其实就是把视频的每一帧都提取出来,然后把每一帧的图片都进行换脸,最后重新把这些图片重新合成一个视频。

废话不多说,我们先来看看效果:
生成效果
原视频如下:

杨幂:

最后的效果:

从视频(由AI生成,请谨慎甄别)可以看出,效果还是不错的,那么具体是怎么做到,以及过程中会有什么坑呢?请接着往下看。
安装插件
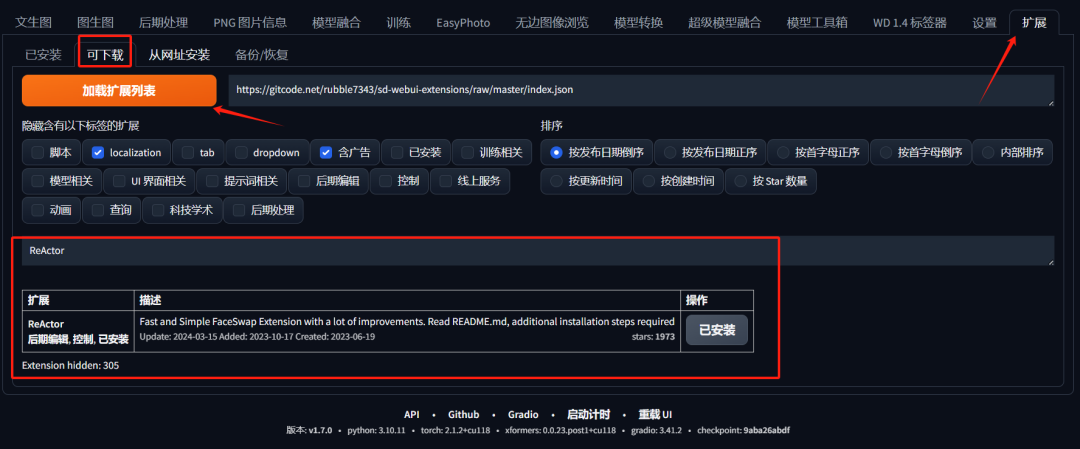
一、ReActor
我们打开 WebUI,在‘扩展 ’里面搜索 ReActor 找到它,然后点击安装 ,再点击应用更改并重启 。
[可能会遇到的问题]
-
安装过程控制台可能提示连接无响应,原因是install.py中有一行代码,是需要从huggingface 下载一个模型
model_url = “https://huggingface.co/datasets/Gourieff/ReActor/resolve/main/models/inswapper_128.onnx”
-
处理方法也很简单,可以手动访问链接下载,也可看下方扫描即可获取本文所需所有模型,然后存放在sd-webui 安装目录\models\insightface中,然后重启sd-webui 即可。

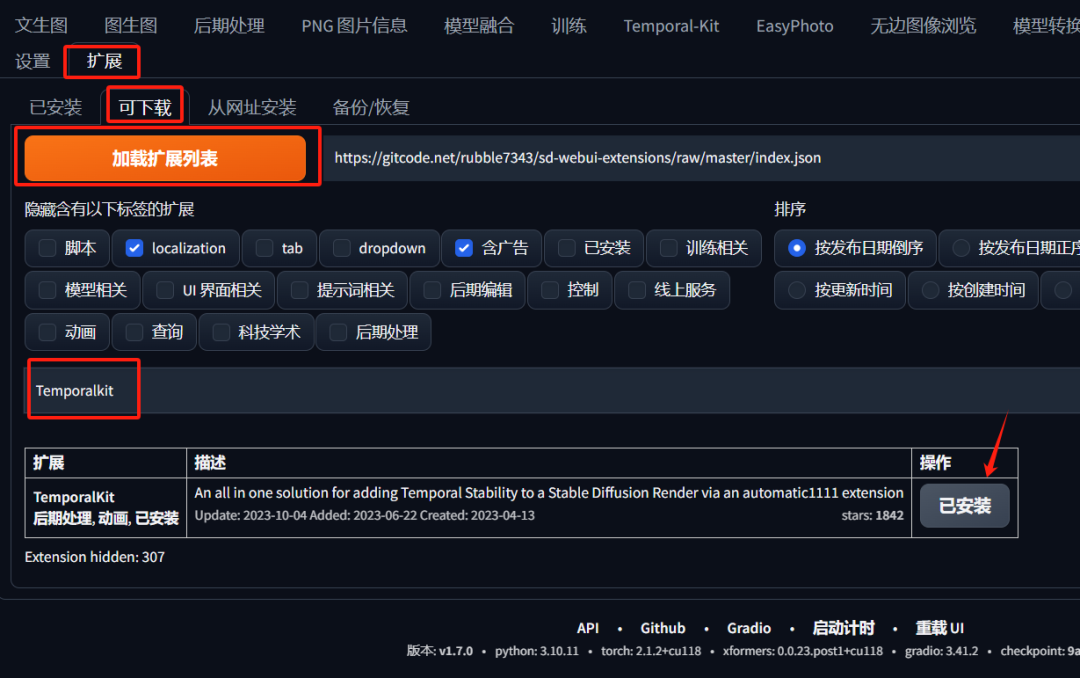
二、Temporalkit
继续在‘扩展 ’里面搜索 Temporalkit 找到它,然后点击安装,再点击应用更改并重启。
[可能会遇到的问题]
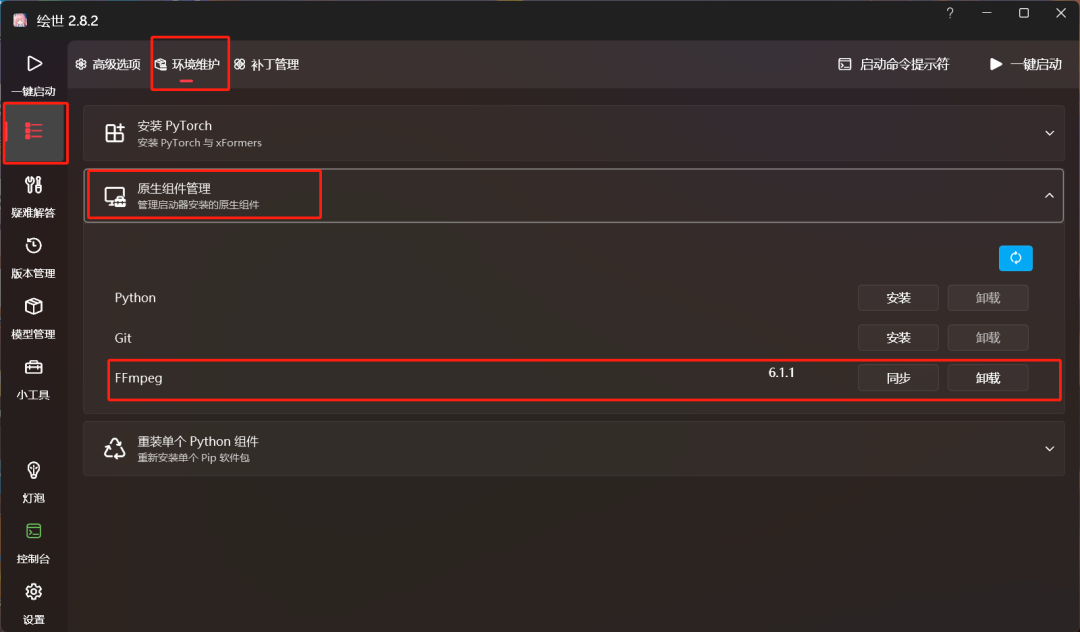
- 确保电脑已经有 ffmpeg 的环境,如果没有的话,可以根据下方步骤一键安装和配置
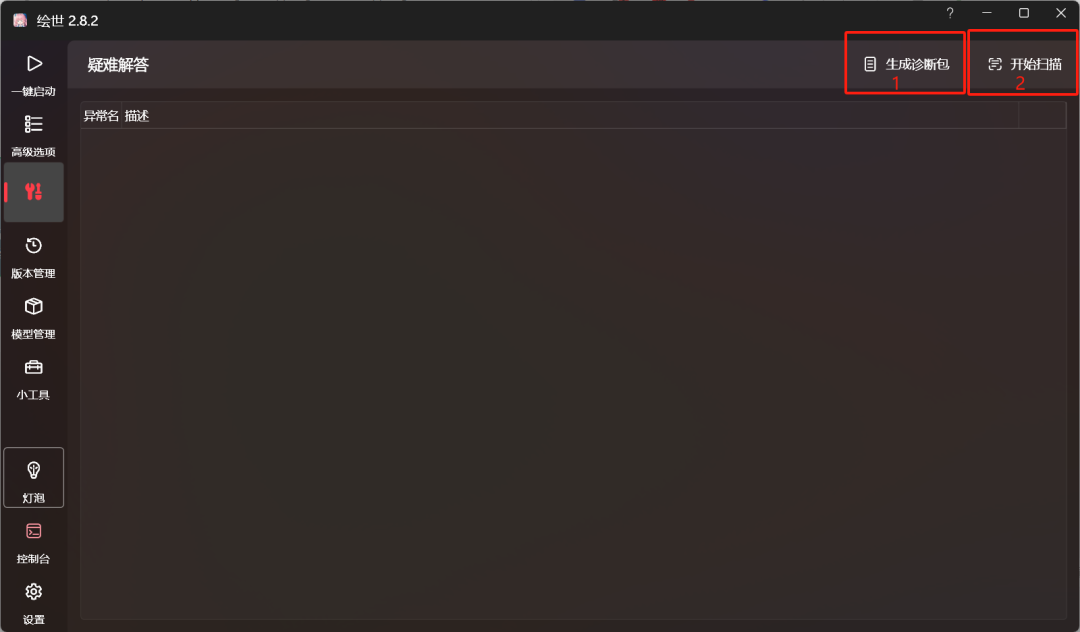
- 若安装 Temporalkit 后,在重启SD时无法启动,可根据下方步骤先生成诊断包,再开始扫描,启动器会提供修复方案。
步骤说明
一 、提取视频中的所有帧
一切准备就绪后,我们首先就是要把视频的每一帧提取出来,这时我们会用到 Temporalkit ,打开 Temporalkit
选项,上传视频,并按照下面红框内容进行设置或勾选。
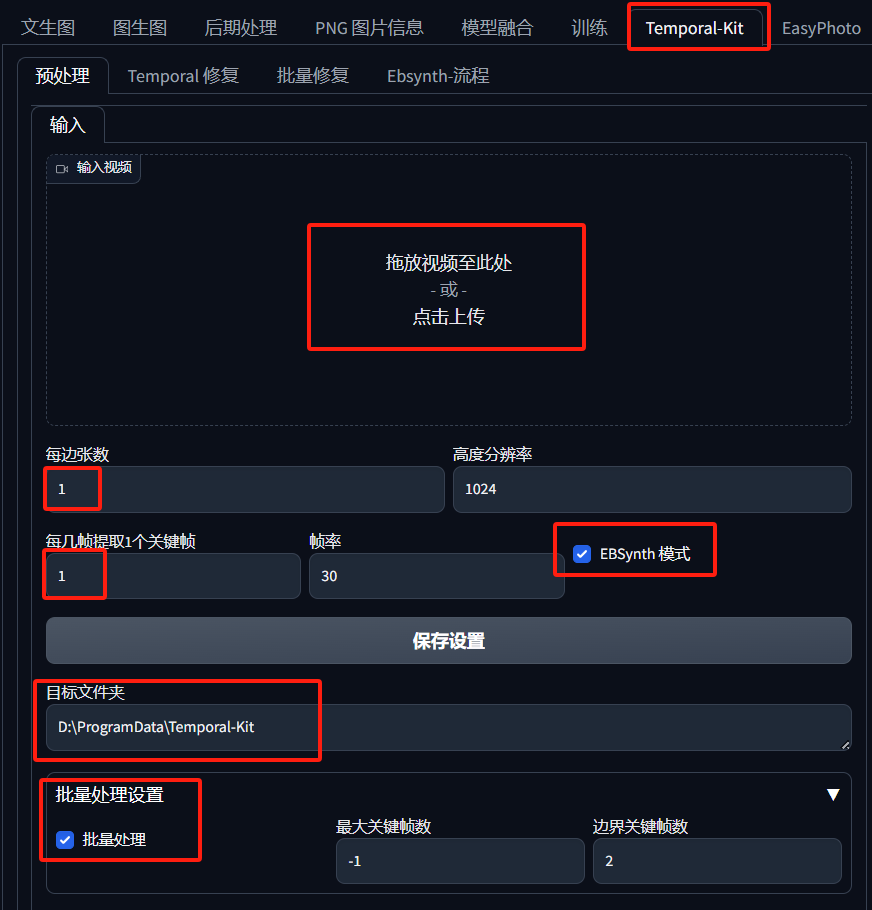
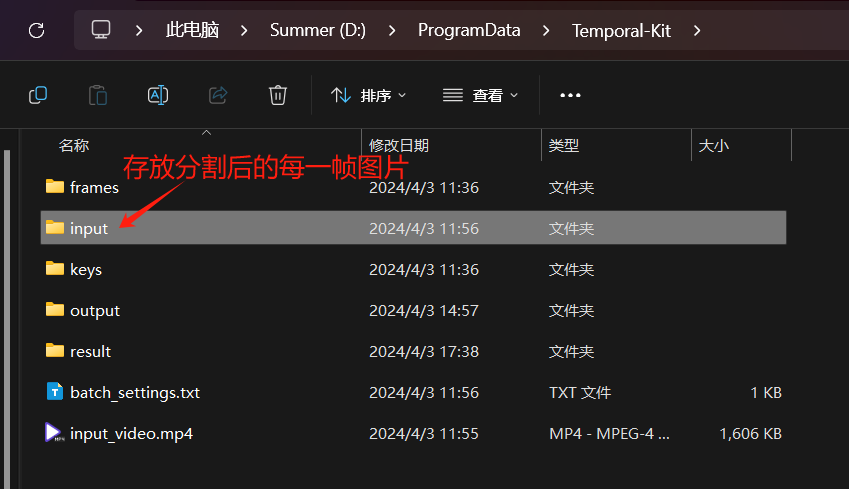
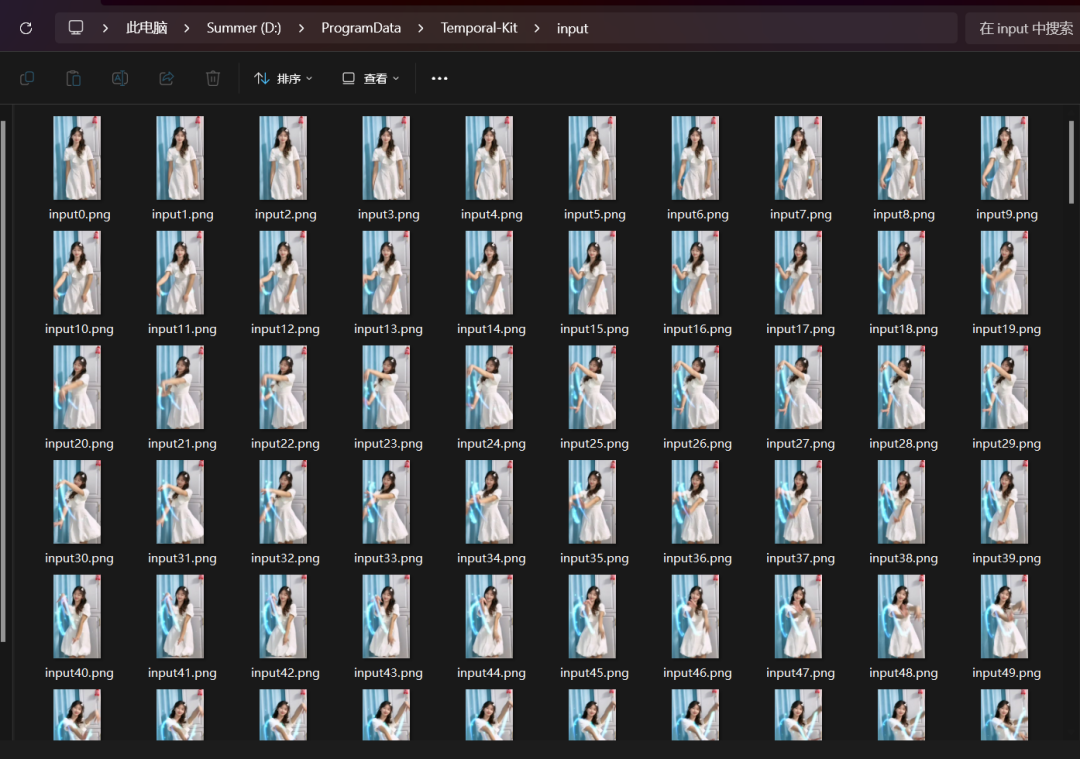
运行后会输出到我们设置的目录当中,打开 input 文件夹就能看到每一帧的图片。
二 、文件夹批量换脸
接着我们打开 图生图 选项,然后顶部 Stable Diffusion 模型 选择真实系风格或写真系风格的模型
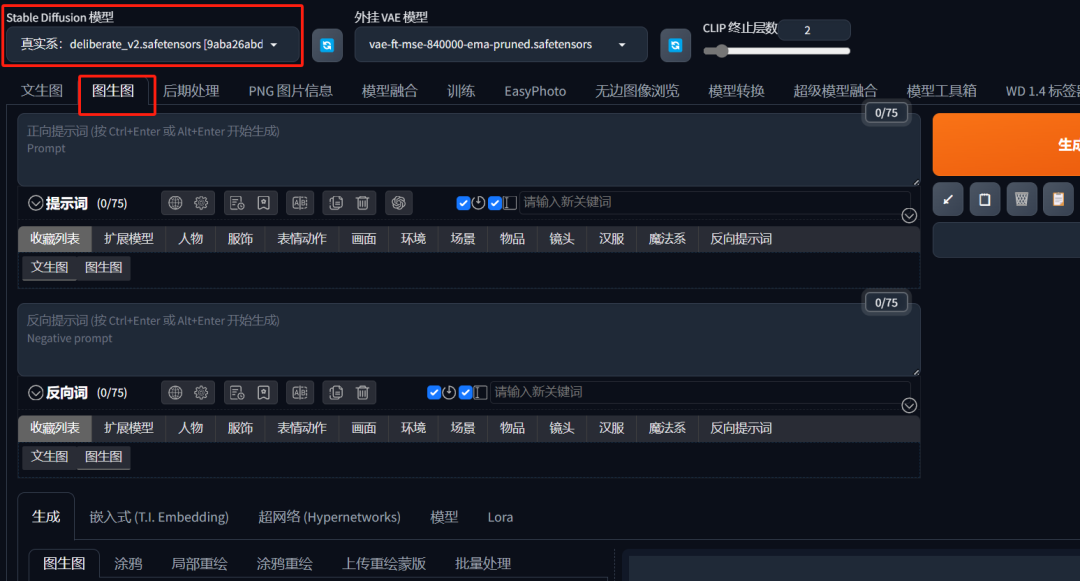
然后设置批量处理 ,输入目录填入刚才的 input 文件夹,输出目录填写 output 文件夹。
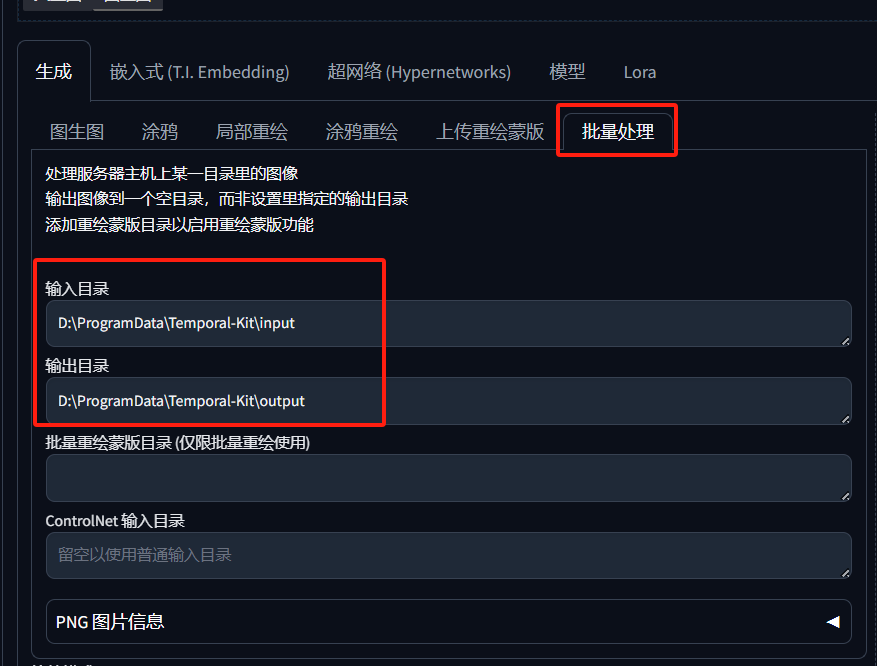
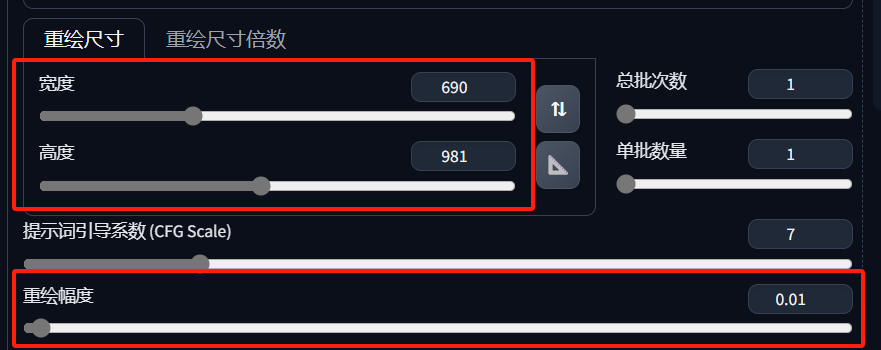
接下来修改重绘的宽度和高度,上传的图片的尺寸是多少,就填写多少就可以了。重点来了,重绘幅度要设置为小于 0.2,这样可以尽最大能力保留原图的细节。
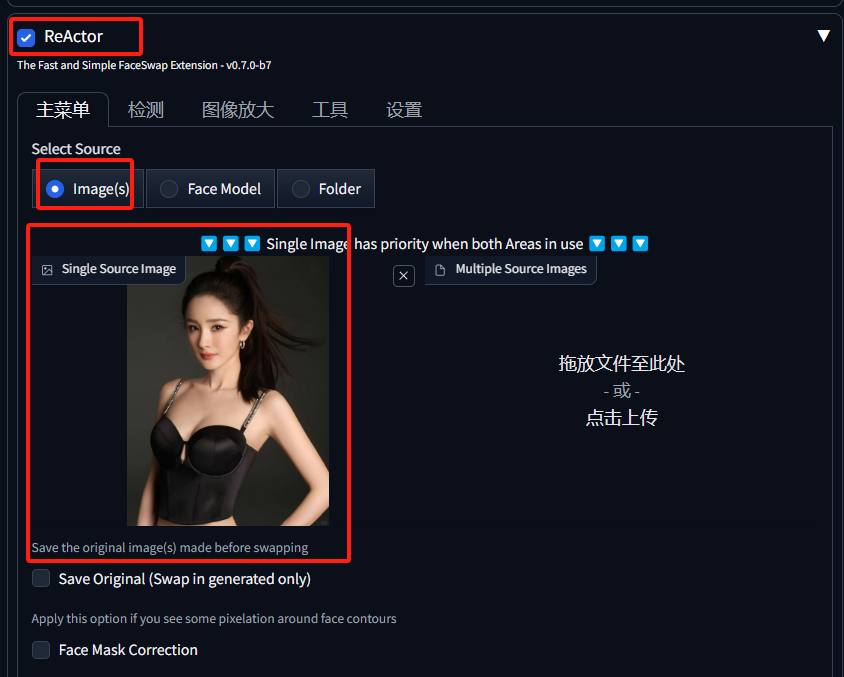
接下来把页面往下拖,找到ReActor
选项,并勾选上。默认就是上传图片的方式来替换脸,这里我们上传一张目标人物的照片。最后点击网页顶部的生成按钮 ,等待即可。
三 、剪映合成视频
视频需要合成两次,原因是素材视频是13秒,而第一次合成最快只能设置到20秒。然后再次导入第一次合成的视频,再次压缩到13秒即可。
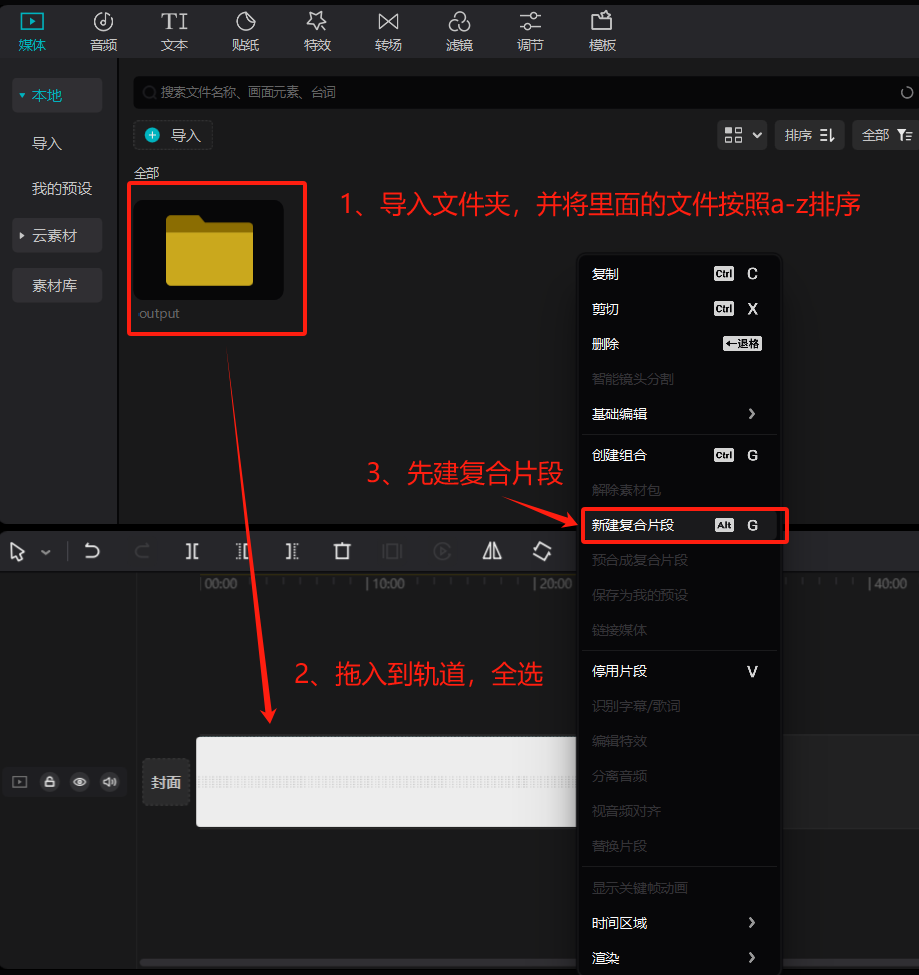
最快只能设置到20秒,因此需要先导出一次视频,为下一次压缩时长做准备。
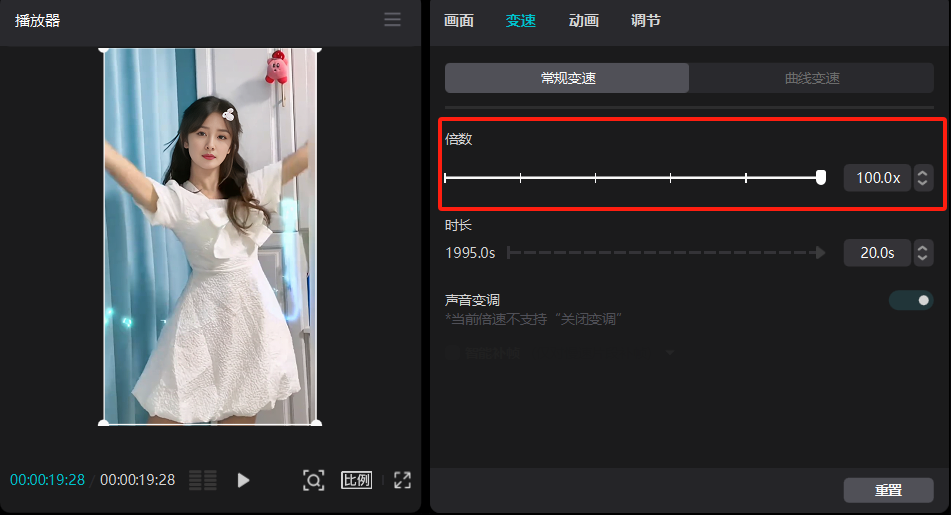
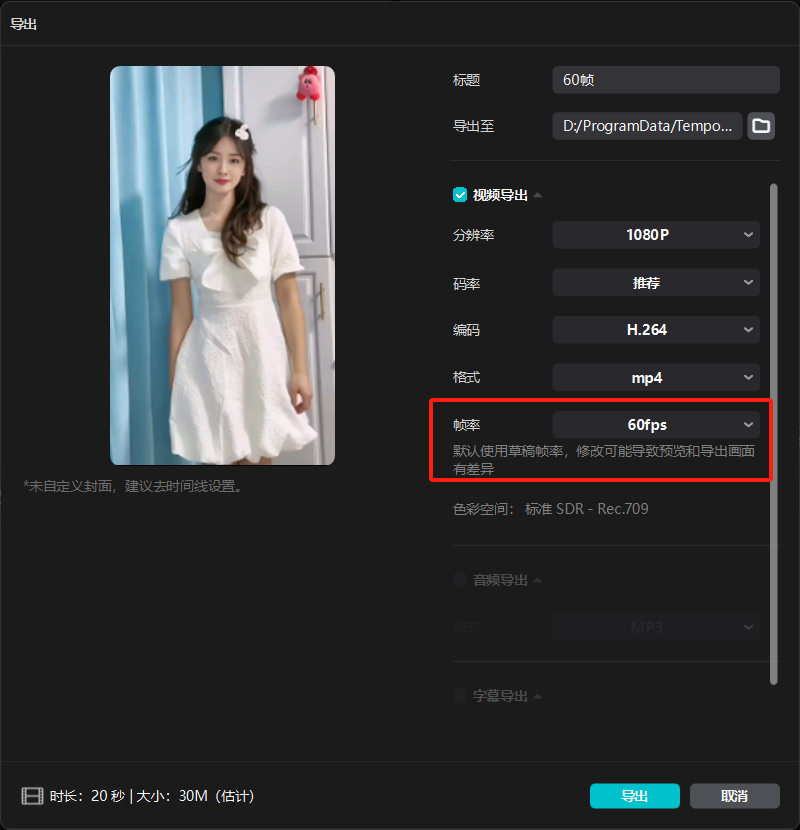
第一次导出的时候,需要选择60帧,这样第二次压缩的时候画面会更流畅。
第二次压缩的时候,时长设置为与原素材一样的13秒,再配上原素材的音轨即可。

总结
总体来说,ReActor 实现的视频换脸案例实质还是图片换脸,只不过最后是将图片合成视频。感兴趣的小伙伴们赶紧试试吧。















 1440
1440

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









