







一、功能与要求
1、实现功能
(1)通过对具体的综合场景化实验,使用Hadoop平台相关组件完成数据采集、数据存储、数据预处理、数据分析、数据可视化等大数据分析全流程;
(2)在Linux系统上安装Hadoop环境(伪分布式或完全分布式);项目使用各组件部署安装正常(flume、hive、sqoop、mysql);
(3)使用Flume或网络爬虫(WebMagic、Python)等数据采集工具完成待分析数据的采集;
(4)设计数据清洗、转换、统计功能,并编写MapReduce程序实现数据清洗功能;通过Idea或eclipse创建maven项目,创建MapReduce功能的Java类,输出项目源码和执行结果。
(5)安装配置Hive数据仓库,连接Hive数据仓库,在Hive中创建ODS层、DW层、ADS层数据表,向数据表中导入数据,并完成多表关联或分组聚合查询,并生成最终的ADS层表;
(6)在MySQL中创建用于存储Hive分析结果的数据表,使用Sqoop命令将hive分析结果导出到MySQL中;
(7)过可视化工具(Java Web、Python Web、Nodejs),开发可视化项目,对MySQL数据库中的分析结果进行可视化展示。
2、项目要求
(1)熟练掌握Hadoop平台的部署、搭建
(2)熟悉HDFS的操作命令
(3)熟悉MapReduce数据清洗的一般流程,能开发MapReduce程序
(4)熟悉Hive的基本语法,通过Hive进行数据分析
(5)熟悉Sqoop数据传输的基本语法
(6)熟熟悉常用Linux操作系统命令
(7)熟悉 Hadoop 操作命令
(8)熟练通过Flume等不同方法进行数据采集
(9)熟悉大数据业务处理的全流程
(10)熟悉数据可视化
3、提交作品
项目设计报告、项目源程序(项目工程目录及相关资源文件)、项目演示录屏、项目演示ppt。
其中,项目源程序包含五个目录:数据采集(包括:采集源码或命令、采集的原始数据)、数据清洗(MapReduce maven项目源码)、数据分析(HQL建库、建表、加载数据、查询等命令)、数据导出(sqoop命令)、数据可视化(可视化项目源码)。
二、系统设计
1、系统背景
借助大数据工具Hadoop以及互联网上的招聘信息作为数据源,设计了一套基于互联网招聘大数据的招聘数据智能分析平台,面向广大的求职者,以及刚毕业的大学生,从而使用户可以实时了解互联网行业最新动态岗位的分布情况,薪资的高低,学历要求,热门岗位,受欢迎的就业地区等信息分析和展示出来,帮助求职者来找到一份适合自己的工作,该项目从数据采集、清洗模块,数据分析模块,数据导出模块,数据可视化模块四个方面来实现平台功能,随着互联网大数据的发展,招聘行业的数据分析任务也亟待大数据技术来实现。但是由于企业岗位繁多,求职者无法正确选择对自身发展最好的职位,企业也无法找到合适的人才,为了解决这些问题才有了这个项目的产生。
2、系统总体设计
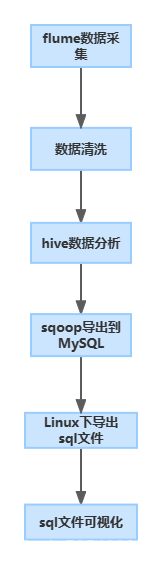
3、系统模块设计
数据采集模块,通过爬虫爬取各大招聘网站的职位信息,或者通过flume将正确的数据上传到hdfs的指定目录上。数据清洗使用MapReduce功能的Java类,编写MapReduce程序实现数据清洗功能,由于数据中有一些我们不需要的数据,属性,以及杂乱的字段,我们使用mapreduce来对于脏数据进行清洗,得到我们想要的数据,这一操作将数据变成了我们想要的数据格式属性,例如热门的职位招聘城市,职位的薪资,学历要求这些属性来进行提取。数据分析的模块我们使用hive来进行数据的分析,hive不适合用于联机(online)事务处理,也不提供实时查询功能,它最适合应用在基于大量不可变数据的批处理作业,通过输入sql 语句对于可以将SQL语句转换为MapReduce任务运行,通过自己的SQL查询分析需要的内容,来了解目前行业的招聘的一个大趋势。使用sqoop 对于数据进行导出,在MySQL中创建用于存储Hive分析结果的数据表,使用Sqoop命令将hive分析结果导出到MySQL中。
最后就是数据的可视化,通过数据可视化工具(JavaWeb、PythonWeb、Nodejs),开发可视化项目,对MySQL数据库中的分析结果进行可视化展示。输出可视化项目工程。
三、系统实现
1、Hadoop集群安装
|
|

2、数据采集
| 1.完成配置安装flume
2.编写Flume配置文件,启动flume
3.上传数据到本地数据目录download并启动flume
4.给hdfs上创建项目数据的目录jobdata来存放在采集的招聘数据,输出Flume日 |



 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章
















 1241
1241











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









