







数据资料参考百度网盘:链接:https://pan.baidu.com/s/1nUj0NkKyHg0JoefJ_oz3ig?pwd=de8t
提取码:de8t
学习内容:
- 在spark shell中完成3个pdf文件中相应RDD基本操作
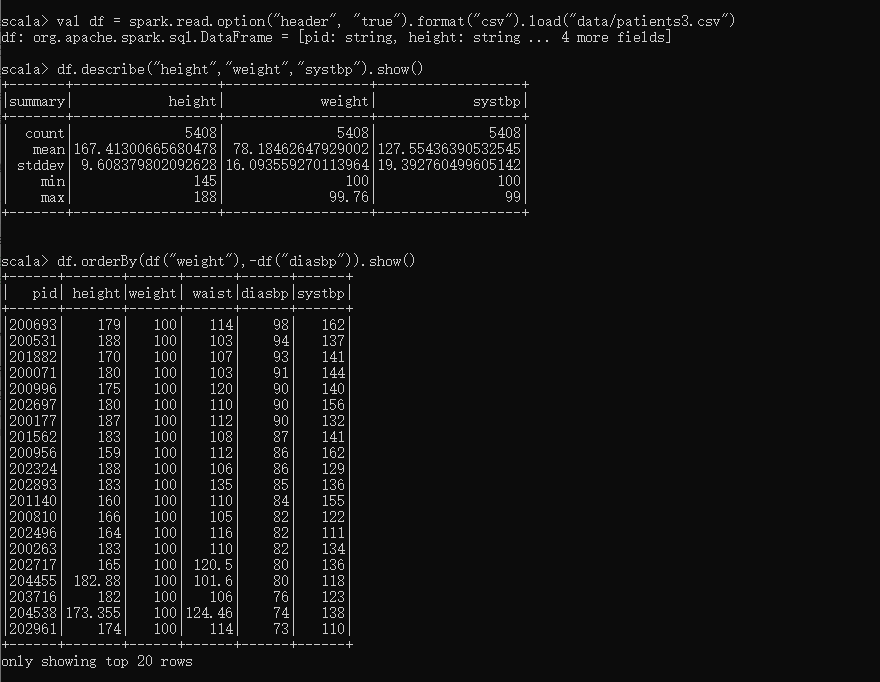
- Patient3.csv中包含病历数据,字段分别为:pid, 身高,体重,腰围,舒张压,收缩压。请RDD操作分别统计以下值:
1)病人数量、平均身高、体重最大值、收缩压方差
2)按体重升序、舒张压降序排序并输出 - 温度.txt数据中包含一段时间的温度测量数据,数据说明如下:
a)第15-19个字符是年份
b)第45-50位是温度表示,+表示零上 -表示零下,且温度的值不能是9999,9999表示异常数据
c)第50位值只能是0、1、4、5、9几个数字
要求:采用Spark SQL实现获取每年的最低温度。
val df = spark.read.option("header", "true").format("csv").load("data/patients3.csv")
df.describe("height","weight","systbp").show()
df.orderBy(df("weight"),-df("diasbp")).show()
val temp_filter = temp.filter(s => (s!="")&&(s.substring(46,50)!="9999")&&(List(0,1,4,5,9).contains(s.substring(50,51).toInt))).map( line => {
(line.substring(15,19).toInt,line.substring(45,50).toInt)
} ).groupByKey().map(values=>(values._1,values._2.min)).collect()


















 2079
2079











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











