







本文仅供学术研究,不做任何投资建议!
文章目录
1.什么是ahr999指标
ahr999指数由著名屯币党微博用户ahr999(九神)创建,计算方式:ahr999指标 =(比特币价格/200日定投成本)*(比特币价格/指数增长估值)。其中指数成长估值为币价和币龄的拟合结果,本指数拟合方法为每月对历史数据进行拟合。

该指数辅助比特币定投用户结合择机策略做出投资决策。 该指数隐含了比特币短期定投的收益率及比特币价格与预期估值的偏离度。 从长期来看,比特币价格与区块高度呈现出一定的正相关,同时借助定投方式的优势,短期定投成本大都位于比特币价格之下。 因此,当比特币价格同时低于短期定投成本和预期估值时增大投资额,能增大用户收益的概率。 根据指标回测,当指标低于0.45时适合抄底,在0.45和1.2区间内适合定投BTC,高于该区间意味着错过最佳定投时期。截至2019年11月底,历史上只有8.5%的时间,ahr999指数小于0.45,这就是抄底区间;有46.3%的时间,ahr999指数在0.45与1.2之间,这就是定投区间;有29.3%的时间,ahr999指数在1.2与5之间,这就是等待起飞的区间。当然,还有ahr999指数大于5的时间,不是屯币党的话可以考虑卖出了。
2.计算ahr999指标
2.1 获取数据
为了计算指标,我们需要先获取比特币诞生以来的所有日线行情数据。由于币安只能请求2019年之后的数据,所以我们需要补全2019年之前的数据。
通过cryptocompare这个网站进行下载,可以根据网站的api文档进行开发https://min-api.cryptocompare.com/documentation,获取日线数据不需要填写apikey。
def fetch_ohlcv(start: datetime = datetime(2010, 7, 17), end: datetime = None)-> pd.DataFrame:
"""
获取数据行情,只能获取到2010/7/16之后的数据
:param start:数据获取开始时间
:param end: 数据结束获取时间
:return:
"""
api_key = "your api key"
fsym: str = "BTC"
tsym: str = "USD"
limit: int = 2000 # 0-2000
toTs: int = int(end.timestamp())
df: DataFrame = DataFrame()
while True:
url = f"https://min-api.cryptocompare.com/data/v2/histoday?fsym={fsym}&tsym={tsym}&limit={limit}&toTs={toTs}&api_key={api_key}"
response = requests.get(url)
res = json.loads(response.content)
data = res.get("Data").get("Data")
tmp: DataFrame = pd.DataFrame(data,
columns=["time", "high", "low", "open",
"close",
"volumefrom", "volumeto"])
tmp.columns = ["datetime", "high", "low", "open",
"close",
"volume", "turnover"]
toTs = tmp.iloc[0].at["datetime"]
df = pd.concat([df, tmp])
if toTs <= start.timestamp():
break
df["datetime"] = df["datetime"].apply(
lambda time: datetime.fromtimestamp(time))
df.dropna(inplace=True)
df.duplicated(subset="datetime", keep="last")
df.set_index("datetime", inplace=True)
df.sort_index(inplace=True)
df = df[df.index > datetime(2010, 7, 17)]
df.to_csv("btcusd.csv")
return df
if __name__ == '__main__':
fetch_ohlcv(end=datetime.now())
其实上面的代码写的并不优雅,操作df最好还是使用链式操作,这篇文章讲了pandas的一些高级操作:https://blog.csdn.net/m0_58598240/article/details/125132376
def fetch_ohlcv(start: datetime = datetime(2010, 7, 17),
end: datetime = None) -> pd.DataFrame:
"""
获取数据行情,只能获取到2010/7/16之后的数据,7/16之前都是无效数据
:param start:数据获取开始时间 默认不动
:param end: 数据结束获取时间
:return: DataFrame
"""
api_key = "you api key"
fsym: str = "BTC"
tsym: str = "USD"
limit: int = 2000 # 0-2000
toTs: int = int(end.timestamp())
df: DataFrame = DataFrame()
while True:
url = f"https://min-api.cryptocompare.com/data/v2/histoday?fsym=" \
f"{fsym}&tsym={tsym}&limit={limit}&toTs={toTs}&api_key={api_key}"
response = requests.get(url)
res = json.loads(response.content)
data = res.get("Data").get("Data")
tmp: DataFrame = pd.DataFrame(data,
columns=[
"time", "high", "low",
"open","close",
"volumefrom", "volumeto"]
)
tmp.columns = ["datetime", "high", "low", "open","close","volume", "turnover"]
toTs = tmp.iloc[0].at["datetime"]
df = pd.concat([df, tmp])
if toTs <= start.timestamp():
break
result = (df
.loc[:, ["datetime", "high", "low", "open","close","volume", "turnover"]]
.dropna()
.assign(datetime=df["datetime"].apply(lambda time: datetime.fromtimestamp(time)))
.set_index("datetime")
.sort_index()
.query(f"datetime>'{datetime(2010, 7, 16)}'")
.to_csv("btcusd.csv")
)
return result
链式调用的写法相比于一般写法而言会快上一点,不过由于数据量比较小,因此二者时间的差异并不大;但链式调用由于不需要额外的中间变量已经覆盖写入步骤,在内存开销上会少一些。
当然,链式调用并不算是完美的,它也存在着一定缺陷。比如说当链式调用的方法超过 10 步以上时,那么出错的几率就会大幅度提高,从而造成调试或 Debug 的困难。
2.2 将数据保存到数据库
def csv_to_db(path: str, database: BaseDatabase):
with open(path, "rt") as f:
buf: list = [line.replace("\0", "") for line in f]
reader: csv.DictReader = csv.DictReader(buf, delimiter=",")
bars: List[BarData] = []
start: datetime = None
count: int = 0
tz = ZoneInfo("Asia/Shanghai")
# 防止后续主键冲突,无法插入数据库
bar_duplicated: BarData = BarData(symbol="BTCUSDT",
exchange=Exchange.BINANCE,
datetime=datetime(2007, 1, 1), volume=0,
turnover=0, open_price=0, high_price=0,
low_price=0, close_price=0,
interval=Interval.DAILY,
gateway_name="DB")
for item in reader:
dt: datetime = datetime.fromisoformat(item["datetime"])
dt = dt.replace(tzinfo=tz)
turnover = item.get("turnover", 0)
open_interest = item.get("open_interest", 0)
bar: BarData = BarData(
symbol="BTCUSDT",
exchange=Exchange.BINANCE,
datetime=dt,
interval=Interval.DAILY,
volume=float(item["volume"]),
open_price=float(item["open"]),
high_price=float(item["high"]),
low_price=float(item["low"]),
close_price=float(item["close"]),
turnover=float(turnover),
open_interest=float(open_interest),
gateway_name="DB",
)
# 防止后续主键冲突,无法插入数据库
if bar_duplicated.exchange == bar.exchange and bar_duplicated.datetime \
== bar.datetime and bar_duplicated.interval == bar.interval:
continue
else:
bars.append(bar)
bar_duplicated = bar
# do some statistics
count += 1
if not start:
start = bar.datetime
end: datetime = bar.datetime
# insert into database
database.save_bar_data(bars)
return start, end, count
if __name__ == '__main__':
# fetch_ohlcv(end=datetime.now())
datebase = get_database()
print(csv_to_db("btcusd.csv", datebase))
运行程序导入成功!之后我们只需要使用脚本代码定期维护数据库的数据即可。【VeighNa】开始量化交易——第二章有详细的数据维护教程。关注我的主页在量化专栏即可找到!
2.3 开始计算ahr999指标
ahr999指标 =(比特币价格/200日定投成本)*(比特币价格/指数增长估值)
2.3.1 建立模型
计算这个指标之前,需要先计算出指数增长估计,假设它是指数增长模型:
y
=
a
e
r
x
y = ae^{rx}
y=aerx
其中
y
y
y是收盘价,
x
x
x是币龄,
r
r
r是比特币增长速度,
a
a
a是参数,我们使用scipy的最小二乘法拟合这个指数增长函数。
from matplotlib import pyplot as plt
from scipy.optimize import curve_fit
from datetime import datetime
import pandas as pd
from vnpy.trader.constant import Exchange, Interval
from vnpy.trader.database import get_database, BaseDatabase
import numpy as np
database = get_database()
bars = database.load_bar_data(
symbol="BTCUSDT",
exchange=Exchange.BINANCE,
interval=Interval.DAILY,
start=datetime(2009, 1, 1),
end=datetime.now()
)
# 转化成pandas的DataFrame格式
df = pd.DataFrame.from_records([
{"datetime": bar.datetime,
"symbol": bar.symbol,
"high": bar.high_price,
"open": bar.open_price,
"low": bar.low_price,
"close": bar.close_price,
"volume": bar.volume,
"turnover": bar.turnover} for bar in bars]).set_index("datetime")
x = np.arange(1, len(df) + 1)
y = np.log(df.close.to_numpy())
def fun(x, a, b):
return a + b * x
popt, pcov = curve_fit(fun, x, y)
a = np.exp(popt[0])
plt.plot(x, a * np.exp(popt[1] * x))
plt.plot(x, np.exp(y), "g")
print(f"a值为:{popt[0]},r值为{popt[1]}")
plt.show()
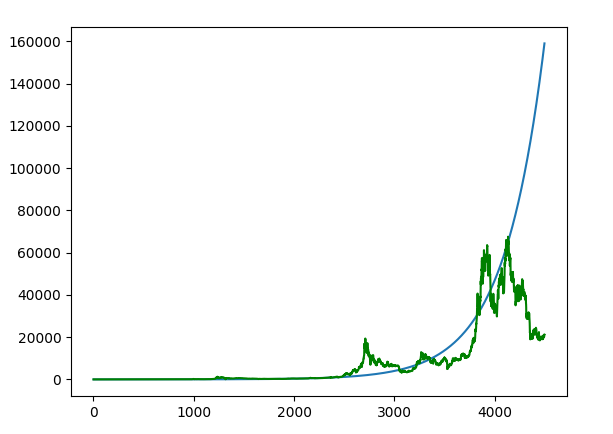
我们可以发现到后面,价格一路飙升,很显然与事实不符,在2021年11月份估值就可以出现了背离,所以我们需要对指数增长模型进行改进。
到2022年11月目前市值4441亿美元,黄金总市值是8.2万亿美元,我相信在很长一段时间比特币价值不会超过黄金,因此比特币的价值增长不可能是一个指数增长模型,更像是一个阻止增长模型,预测比特币长期来看会到10万美金,到达一个值后就不会再增长。类似于生态系统中的物种繁衍的s型曲线,建模完整过程可以参考我之前写的一篇文章:【数学建模\MATLAB】掌握用Matlab求解微分方程问题
于是我们建立了logtisc阻滞增长模型:
x
(
t
)
=
x
m
1
+
(
x
m
x
0
−
1
)
e
−
r
t
x(t) = \frac{x_m}{1+(\frac{x_m}{x_0}-1)e^{-rt}}
x(t)=1+(x0xm−1)e−rtxm
x
m
x_m
xm表示了比特币最高涨到的价格,
x
0
x_0
x0表示了比特币初始价格,
r
r
r是比特币增长速度。
我们假定比特币最高时10万美金,计算出r值:0.0027923
from matplotlib import pyplot as plt
from scipy.optimize import curve_fit
from datetime import datetime
import pandas as pd
from vnpy.trader.constant import Exchange, Interval
from vnpy.trader.database import get_database, BaseDatabase
import numpy as np
database = get_database()
bars = database.load_bar_data(
symbol="BTCUSDT",
exchange=Exchange.BINANCE,
interval=Interval.DAILY,
start=datetime(2009, 1, 1),
end=datetime.now()
)
# 转化成pandas的DataFrame格式
df = pd.DataFrame.from_records([
{"datetime": bar.datetime,
"symbol": bar.symbol,
"high": bar.high_price,
"open": bar.open_price,
"low": bar.low_price,
"close": bar.close_price,
"volume": bar.volume,
"turnover": bar.turnover} for bar in bars]).set_index("datetime")
x = np.arange(1, len(df) + 1)
y = df.close.to_numpy()
def fun(x, r):
xm = 100000
return xm/(1+(xm/0.4951-1)*np.exp(-r*x))
popt, pcov = curve_fit(fun, x, y)
x_ = np.arange(1,6000)
plt.plot(x, fun(x,*popt),"b",label="fit")
plt.plot(x_,fun(x_,*popt),"r--",label="predict")
plt.plot(x, y, "g",label="real")
plt.legend()
print(f"r值为:{popt[0]}")
plt.show()
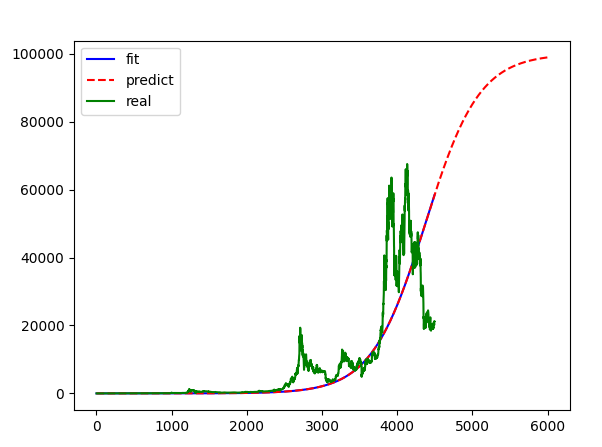
得到最终公式:
x
(
t
)
=
100000
1
+
(
100000
0.4951
−
1
)
e
−
0.0027923
t
x(t) = \frac{100000}{1+(\frac{100000}{0.4951}-1)e^{-0.0027923t}}
x(t)=1+(0.4951100000−1)e−0.0027923t100000
如果你是一个比特币坚定的信仰主义者,认为比特币最终可以到达10万美金,那么恭喜你,可以继续看下面的内容了,如果认为比特币就是一个骗局,那下面的内容也没什么意义了。
2.3.2 计算指标
下面的代码运行环境在jupyter下进行
import csv
import json
from datetime import datetime
from typing import List
from zoneinfo import ZoneInfo
import numpy as np
import pandas as pd
import requests
from pandas import DataFrame
from vnpy.trader.constant import Exchange, Interval
from vnpy.trader.database import get_database, BaseDatabase
from vnpy.trader.object import BarData
import plotly.graph_objs as go
import numpy as np
"""计算ahr999指标
ahr999指标 =(比特币价格/200日定投成本)*(比特币价格/指数增长估值)
到2022年11月目前市值4441亿美元,黄金总市值是8.2万亿美元,我相信在很长一段时间比特币价值
不会超过黄金,因此比特币的价值增长不可能是一个指数增长模型,更像是一个阻止增长模型,预测比特币长期来看会到10万美金,
到达一个值后就不会再增长。类似于生态系统中的物种繁衍的s型曲线.
"""
# 从数据库获取数据
database = get_database()
bars = database.load_bar_data(
symbol="BTCUSDT",
exchange=Exchange.BINANCE,
interval=Interval.DAILY,
start=datetime(2009, 1, 1),
end=datetime.now()
)
# 转化成pandas的DataFrame格式
df = pd.DataFrame.from_records([
{"datetime": bar.datetime,
"symbol": bar.symbol,
"high": bar.high_price,
"open": bar.open_price,
"low": bar.low_price,
"close": bar.close_price,
"volume": bar.volume,
"turnover": bar.turnover} for bar in bars]).set_index("datetime")
# 阻滞增长模型
def fun(x):
xm = 100000
return xm / (1 + (xm / 0.4951 - 1) * np.exp(-0.0027922897270131037 * x))
# 指数增长估值
df["age"] = np.arange(1, len(df) + 1)
df["increasing_index"] = df["age"].apply(lambda x: fun(x))
# 计算200日定投成本
# 这边为了简化操作就使用200日收盘价均线作为定投成本的计算
df["investment_cost"] = df["close"].rolling(200).mean()
# 计算ahr999指标
df["ahr999"] = (df["close"] / df["investment_cost"]) * (
df["close"] / df["increasing_index"])
df.dropna(inplace=True)
trace1 = go.Scatter(
x=df.index,
y=df.ahr999,
name="ahr999",
xaxis='x',
yaxis='y1',
)
trace2 = go.Scatter(
x=df.index,
y=df.close,
name='close',
xaxis='x',
yaxis='y2')#标明设置一个不同于trace1的一个坐标轴)
trace3 = go.Scatter(
x=df.index,
y=np.full(len(df),0.4),
name='抄底线'
)
trace4 = go.Scatter(
x=df.index,
y=np.full(len(df),1.2),
name='定投线'
)
trace5 = go.Scatter(
x=df.index,
y=np.full(len(df),5),
name='观望线'
)
layout = go.Layout(
yaxis=dict(range=[0, 10]),
yaxis2=dict(anchor='x', overlaying='y', side='right')#设置坐标轴的格式,一般次坐标轴在右侧
)
data = [trace1, trace2,trace3,trace4,trace5]
fig = go.Figure(data=data, layout=layout)
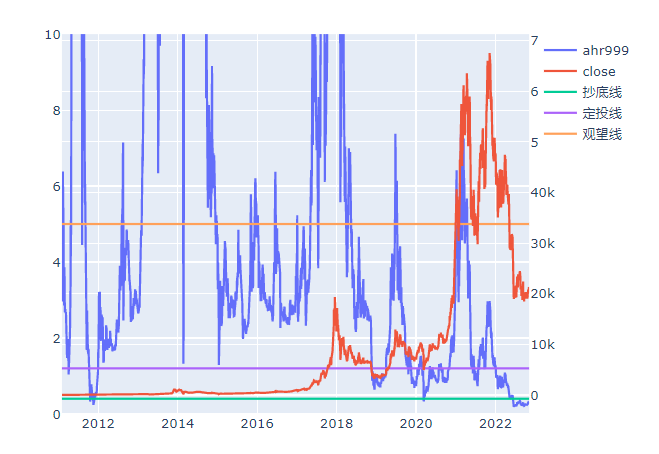
fig.show()
plt.rcParams['font.family']='simhei'
ahr999_bins = [0,0.45,1.2,5,df["ahr999"].max()]
# 设置标签
labels=['抄底区间','定投区间','观望区间','套现区间']
a = pd.cut(x=df["ahr999"],bins=ahr999_bins,labels=labels).dropna()
counts = pd.value_counts(a)
b=plt.bar(counts.index.astype(str),counts)
plt.bar_label(b,counts)
plt.show()
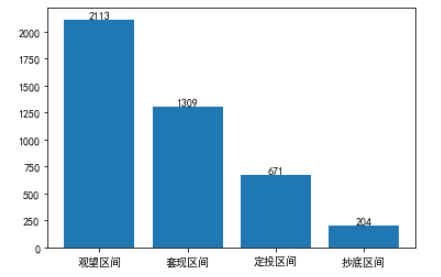
结合两个图例,我们可以发现在历史上只要在定投区间和抄底区间买入比特币,基本上不会亏钱,在之后的一段时间内会迎来比特币的进一步上涨。
3.情绪指标
别人恐惧我贪婪,别人贪婪我恐惧。
如果之前接触过luna的币友,看到这张图应该都会有深深的感触。投资从来不是一个简单的事情,各自指标只能帮助你去分析,但不能替代你去分析。什么意思呢?行情千变万化,交易所更像是一个战场,你在和数以千万的对手拼策略、拼勇气,背后更有飞机、大炮的猛攻,策略就是我们的三八大盖,要活下来,最终还是得怂。

3.1 指标介绍
加密货币市场行为是非常情绪化的。当行情上涨时,人们往往会变得贪婪,这导致了FOMO(害怕错过)。当行情下跌时,人们经常以不合理的反应抛售他们的加密货币。借助恐惧和贪婪指数,我们试图阻止你的反应过度情绪。这有两个简单的假设:一是极端的恐惧可能是投资者过于担心的信号,这可能是一个买入的机会;二是当投资者变得过于贪婪时,这意味着市场将会出现回调。因此,我们分析比特币市场的当前情绪,并将这些行情走势压缩成一个从0到100的指数区间。0意味着“极度恐惧”,而100则意味着“极度贪婪”。

指标官方文档:https://alternative.me/crypto/fear-and-greed-index/
3.2 指标计算
"""
恐惧&贪婪指数
"""
def fear_and_greed_index(limit:int) ->DataFrame:
url = f"https://api.alternative.me/fng/?limit={limit}"
response = requests.get(url)
res = json.loads(response.content)
df = pd.DataFrame(data=res["data"],columns=["value","value_classification","timestamp"])
df["timestamp"] = df["timestamp"].apply(lambda timestamp: datetime.strftime(datetime.fromtimestamp(int(timestamp)),'%Y-%m-%d %H:%M:%S'))
df = df.set_index("timestamp")
df["value"] = df["value"].astype(int)
df.to_csv("fear_and_greed_index.csv")
return df
df2 = fear_and_greed_index(2000)
df2["datetime"] = df2.index
df2["datetime"] = df2["datetime"].apply(lambda x:datetime.fromisoformat(x).replace(tzinfo=ZoneInfo("Asia/Shanghai")))
df2.set_index("datetime")
df3 = pd.merge(df,df2,on="datetime")
fear_greed = go.Scatter(
x=df3.index,
y=df3.value,
name="fear_greed",
)
close = go.Scatter(
x=df3.index,
y=df3.close,
name='close',
xaxis='x',
yaxis='y2'
)#标明设置一个不同于trace1的一个坐标轴)
layout = go.Layout(
yaxis2=dict(anchor='x', overlaying='y', side='right')#设置坐标轴的格式,一般次坐标轴在右侧
)
fig = go.Figure(data=[fear_greed,close],layout=layout)
fig.show()
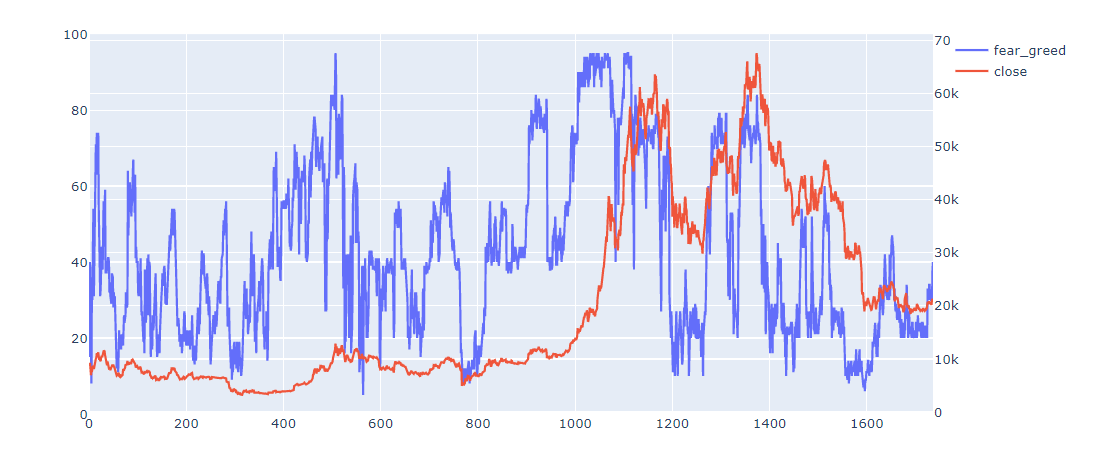
可以发现,贪婪程度越高,我们越应该恐惧,因为这往往意味着牛市的结束,熊市的开始。价格高点的极度恐惧往往是一波反弹,在价格低点的极度恐惧往往是熊市的结束,牛市的开始。所以我们抄底就应该在别人退场的时候进场,卖出的时候就应该在别人进场的时候出场。
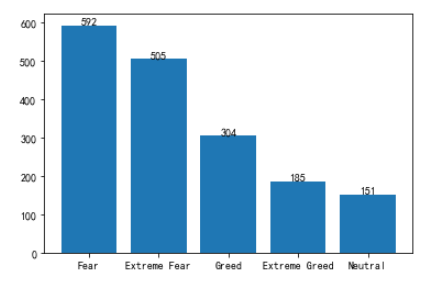
value_classification = pd.value_counts(df3["value_classification"])
b=plt.bar(value_classification.index.astype(str),value_classification)
plt.bar_label(b,value_classification)
plt.show()
4. 编写简单的回测策略
4.1 策略介绍
- ahr999指标小于0.45,极度贪婪的情况下,定时买入3个仓位比特币
- ahr999指标小于0.45,并且在恐惧的情况下,定时买入2个仓位比特币
- ahr999指标0.45-1.2, 并且在极度恐惧的情况下,定时买入1个仓位比特币
- ahr999指标5以上, 并且在极度贪婪的情况下,定时卖出4个仓位比特币
- ahr999指标5以上,在极度贪婪的时候定期出3个仓位比特币
计划定时周期为一周
def backtesting(interval,df)->pd.DataFrame:
"""
interval 定投时间
"""
# 抛弃NA数值
df.dropna(inplace=True)
# 计算目标仓位
target = 0
df["target"] = 0
df["capital"] = 20000
for ix, row in df.iterrows():
# 在定投的时间:
if not (ix%interval):
# 如果空仓
if target<=0:
if row.ahr999<0.45 and (row.value_classification=="Extreme Fear"):
target = target+3
elif row.ahr999<0.45 and (row.value_classification=="Fear"):
target = target+2
elif (0.45<= row.ahr999 <=1.2) and (row.value_classification=="Extreme Fear"):
target = target+1
# 如果不是空仓,进行买入或者卖出
else:
if row.ahr999<0.45 and (row.value_classification=="Extreme Fear"):
target = target+3
elif row.ahr999<0.45 and (row.value_classification=="Fear"):
target = target+2
elif (0.45<= row.ahr999 <=1.2) and (row.value_classification=="Extreme Fear"):
target = target+1
elif row.ahr999>5 and (row.value_classification=="Extreme Greed") and target>4:
target = target - 4
elif row.ahr999>5 and (row.value_classification=="Greed") and target>3:
target = target -3
df["target"][ix]=target
# 计算仓位
df["pos"] = df["target"].shift(1).fillna(0)
# 计算盈亏和手续费
rate = 0.0004
df["change"] = df["close"].diff()
df["fee"]=0
df["fee"][df['pos']!=df['pos'].shift(1)]=df.loc[:,"close"]*rate
df["pnl"] = df["change"] * df["pos"]-df["fee"]
df["balance"] = df["pnl"].cumsum()+df["capital"]
# 计算夏普比
pre_balance: Series = df["balance"].shift(1)
pre_balance.iloc[0] = df["capital"].iloc[0]
x = df["balance"] / pre_balance
x[x <= 0] = np.nan
df["return"] = np.log(x).fillna(0)
total_return: float = (df["balance"].iloc[-1] / df["capital"].iloc[0] - 1) * 100
total_days: int = len(df)
annual_return: float = total_return / total_days * 365
daily_return: float = df["return"].mean() * 100
return_std: float = df["return"].std() * 100
daily_risk_free: float = 4.0 / np.sqrt(365)
sharpe_ratio: float = (daily_return - daily_risk_free) / return_std * np.sqrt(365)
# 计算最大回撤
df["highlevel"] = (
df["balance"].rolling(
min_periods=1, window=len(df), center=False).max()
)
df["drawdown"] = df["balance"] - df["highlevel"]
df["ddpercent"] = df["drawdown"] / df["highlevel"] * 100
max_ddpercent = df["ddpercent"].min()
print(f"夏普比{sharpe_ratio},最大回撤{max_ddpercent},总收益率为{total_return},年化收益率为{annual_return}")
return df
4.2 回测结果
夏普比,最大回撤,总收益,年化收益。
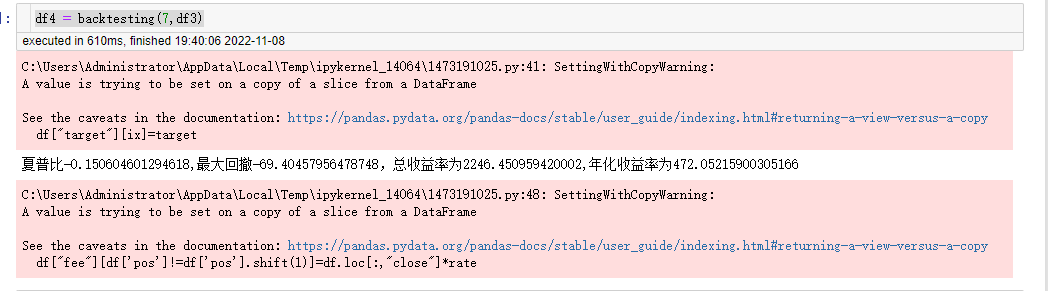
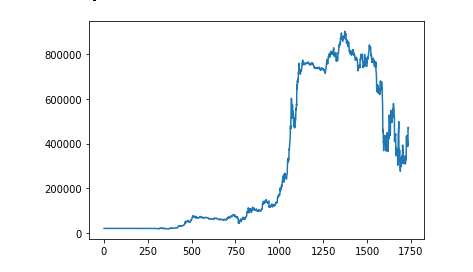
资金曲线
df4 = backtesting(7,df3)
df4["balance"].plot()
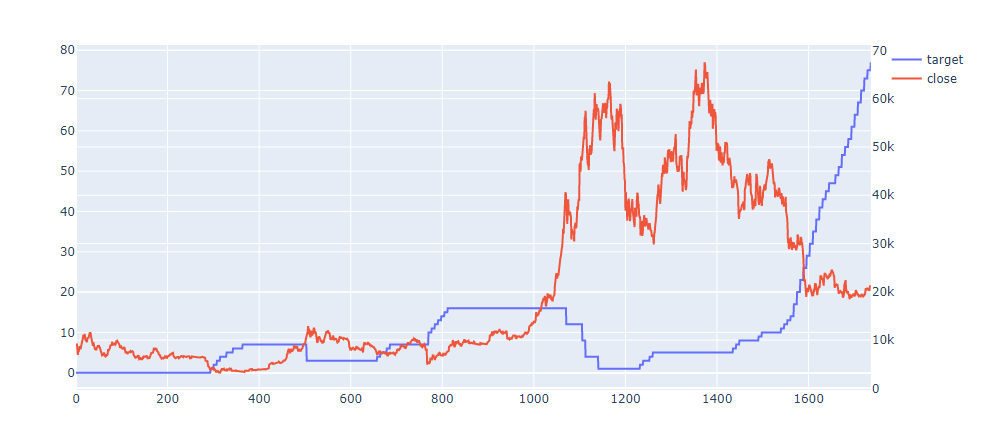
查看持仓和比特币价格走势图
import plotly.graph_objs as go
import numpy as np
import matplotlib.pylab as plt
target = go.Scatter(
x=df4.index,
y=df4.target,
name="target",
)
close = go.Scatter(
x=df4.index,
y=df4.close,
name='close',
xaxis='x',
yaxis='y2'
)#标明设置一个不同于trace1的一个坐标轴)
layout = go.Layout(
yaxis2=dict(anchor='x', overlaying='y', side='right')#设置坐标轴的格式,一般次坐标轴在右侧
)
fig = go.Figure(data=[target,close],layout=layout)
fig.show()
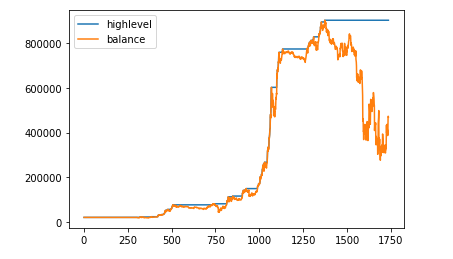
df4[["highlevel","balance"]].plot()
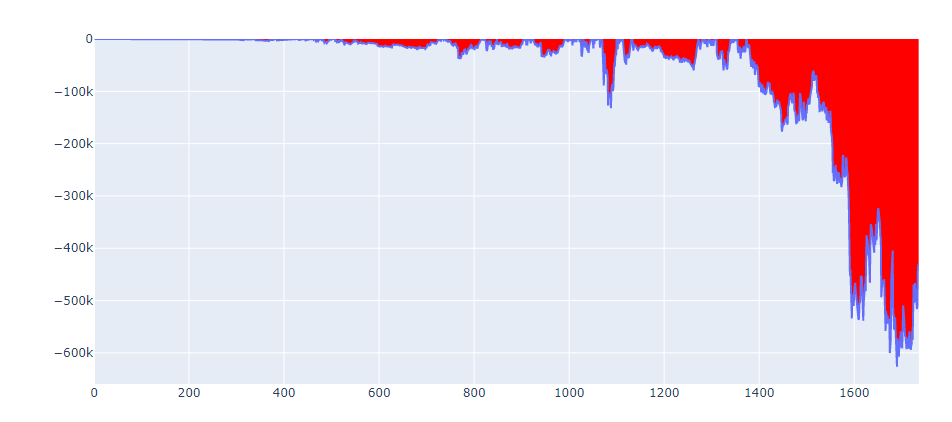
drawdown_scatter = go.Scatter(
x=df4.index,
y=df4["drawdown"],
fillcolor="red",
fill='tozeroy',
mode="lines",
name="Drawdown"
)
fig = go.Figure(data=drawdown_scatter)
fig.show()
5. 文末
大家可以集思广益,建模思路有很多,策略也有很多,其中可以修改一些参数,可能结果会更好看一些。欢迎各位大佬私信我,共同讨论。



















 2753
2753

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











