









声明
不定期更新自己精读的论文,通俗易懂,初级小白也可以理解
涉及范围:深度学习方向,包括 CV、NLP、Data fusion、Digital Twin
 论文标题:Bottleneck Transformers for Visual Recognition
论文标题:Bottleneck Transformers for Visual Recognition
论文链接:https://arxiv.org/abs/2101.11605v1
论文代码:https://github.com/tensorflow/tpu/tree/master/models/official/detection
发表时间:2021年8月
创新点
1、提出一种简单架构 BoTNet
2、提出一种具有自注意力机制的 ResNet 块
Abstract
我们提出了 BoTNet,这是一种概念上简单但功能强大的主干架构,它结合了用于多个计算机视觉任务的自注意力,包括图像分类、对象检测和实例分割。通过仅在 ResNet 的最后三个块中用全局自注意力替换空间卷积并且没有其他更改,我们的方法在实例分割和对象检测方面显着改进了基线,同时还减少了参数,而延迟开销最小。
通过 BoTNet 的设计,我们还指出了具有自注意力的 ResNet 块可以被视为 Transformer 块。没有任何花里胡哨,BoTNet 使用 Mask R-CNN 框架在 COCO Instance Segmentation benchmark 上实现了 44.4% 的 Mask AP 和 49.7% 的 Box AP;超过了在 COCO 验证集上评估的 ResNeSt 之前发表的最佳单一模型和单一尺度结果。
最后,我们展示了对 BoTNet 设计的简单改编以用于图像分类,从而使模型在 ImageNet 基准测试中实现了 84.7% 的 top-1 准确率,同时在“计算”方面比流行的模型快 1.64 倍 TPU-v3 硬件上的 EfficientNet 模型。 我们希望我们简单而有效的方法能够为未来视觉自注意力模型的研究奠定坚实的基础。
Method

BoTNet-50 架构是由 ResNet-50 修改得到,由图中可知是由 ResNet-50 中的 stage-c5 中的 3*3 卷积变成了 MHSA(多头自注意力机制)
MHSA

BoT 块中使用的多头自我注意 (MHSA) 层
all2all 注意力是在 2D 特征图上执行的,其高度和宽度分别具有分割的相对位置编码 Rh 和 Rw
注意最终是 qkT + qrT,再进入 softmax 层中进行
其中 q、k、r 分别代表查询、键和位置编码(作者使用相对距离编码)
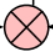 和
和 ![]() 分别代表矩阵乘法和逐元素求和,而 1 × 1 代表逐点卷积。
分别代表矩阵乘法和逐元素求和,而 1 × 1 代表逐点卷积。
















 2212
2212











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











