








文章目录
- 1. Motivation
- 2. Contribution
- 3. Method
- 4. Experiment
-
- 4.1 BoTNet improves over ResNet on COCO In- stance Segmentation with Mask R-CNN
- 4.2. Scale Jitter helps BoTNet more than ResNet
- 4. 3 Relative Position Encodings BoostPerformance BoTNet
- 4.4 Why replace all three c5 spatial convolutions?
- 4.5 BoTNet improves backbones in ResNet Family
- 4.6 BoTNet scales well with larger images
- 4.7 Comparison with Non-Local Neural Networks
1. Motivation
作者认为虽然堆叠更多层可以改善backbone的性能,但是隐式的结果来建模全局依赖(global dependencies),而不需要太多层,可以成为一种powerful和scalable的方案。
Although stacking more layers indeed improves the performance of these backbones [72], an explicit mechanism to model global (non-local) dependencies could be a more powerful and scalable solution without requiring as many layers.
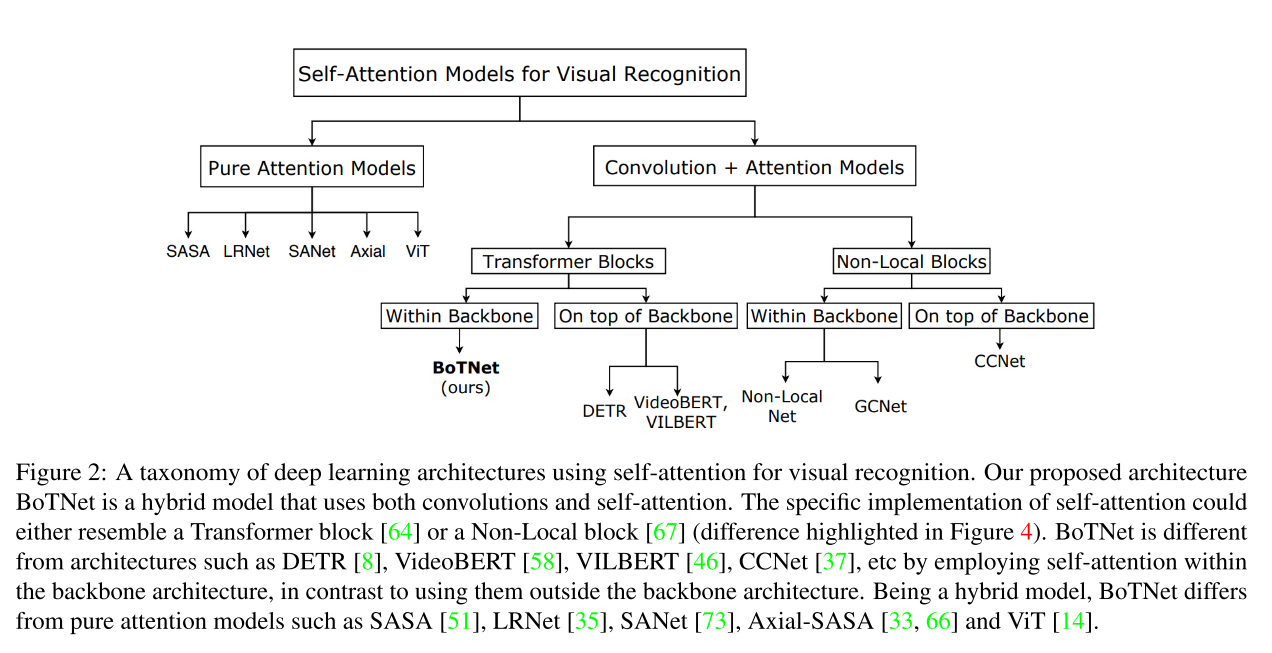
如图2所示,作者还将目前用于视觉识别的自注意力进行分类。先分为了Pure Attention Models和Convolution + Attention Models,然后将后者继续分为了Transformer Blocks 和 Non-Local Blocks,二者进一步可以细分为Within Backabone 和 On top of Backbone2类。
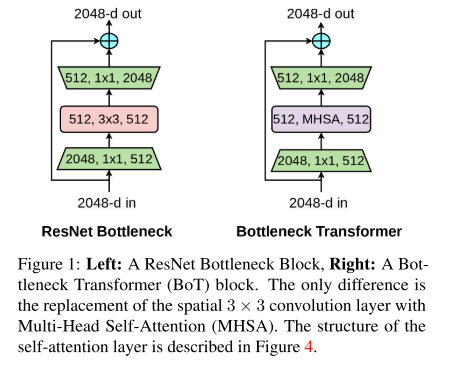
作者认为带有MHSA层的resnet bottleneck blocks可以看作为是一种带有bottleneck的Transformer blocks。同样可以做到残差连接。
对于在视觉中使用self-attention有2个challenge,(1)图片是1024x1024的分辨率,(2)对于自注意力的内存开销增大。对于这2点作者制定了2种联合的构思,(1)是使用卷积,从大图像上学习抽象和低分辨率的特征图;(2)使用全局self-attention,来处理和合并卷积后的特征图所包含的信息。
(1) Use convolutions to efficiently learn abstract and low resolution featuremaps from large images;
(2) Use global (all2all) self-attention to process and aggregate the information contained in the featuremaps captured by convolutions
2. Contribution
本文提出了BoTNet,一种包含self-attention的新的backbone,通过将ResNet中的最后三个bottleneck blocks的空间卷积替换为全局self-attention,可用于图像分类,目标检测以及实例分割领域。
Without any bells and whistles, BoTNet achieves 44.4% Mask AP and 49.7% Box AP on the COCO Instance Segmentation benchmark using the Mask R-CNN framework.
we present a simple adaptation of the BoTNet design for image classification, resulting in models that achieve a strong performance of 84.7% top-1 accuracy on the ImageNet benchmark while being up to 2.33x faster in “compute”1 time than the popular EfficientNet models on TPU-v3 hardware.
3. Method
3.1 Architecture Network
从表1可以很直观的看出,作者将最后一层c5最后三个bottleneck block的3x3的卷积核替换为了MHSA层(如图1,4所示),并定义为BoT blocks。
Replace only the final three bottle- neck blocks of a ResNet with BoT blocks without any other changes. Or in other words, take a ResNet and only replace the final three 3 × 3 convolutions with MHSA layers (Fig 1, Table 1).
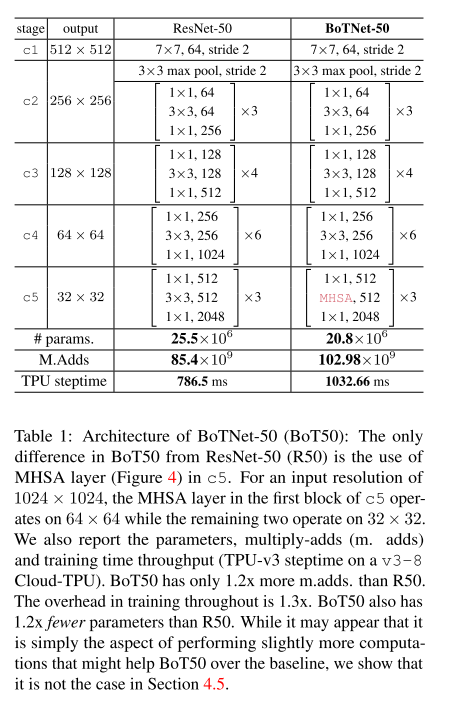
因为resnet中的c5的前一个3x3卷积核的步长为2(也就是HxW 变为了 H/2 X W/2),而后2个3x3的卷积核的步长为1;但对于self-attn结构来说是没有stride这个参数,因此对于第一个Bot Blcok,在all2all attention后使用一个2x2的avg pool,步长为2进行缩放。
3.2 MHSA
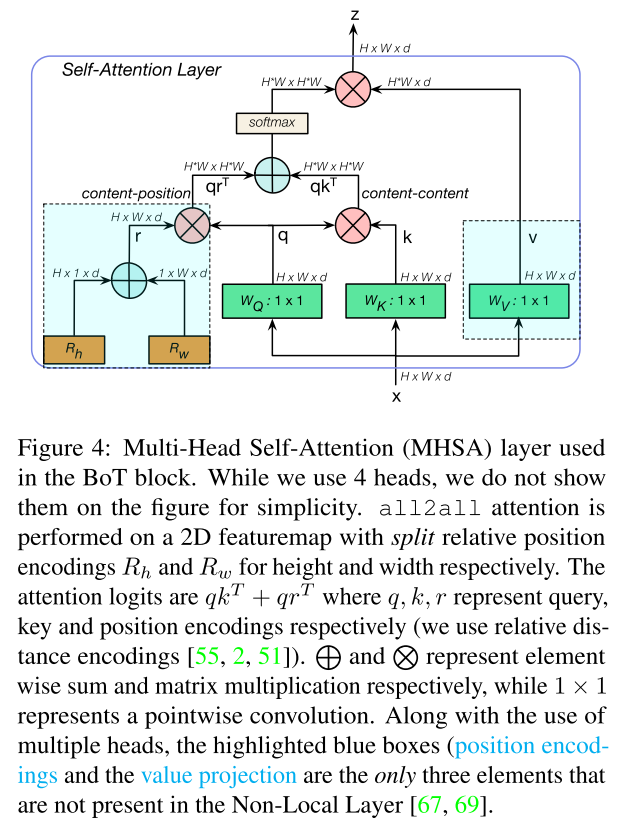
如图4所示,为BOT block中的MHSA层,其中蓝色部分position encoding 以及value projection是Non-Local Layer中没有出现的部分。其中position encoding使用的是Relative Position Encoding,对于图像的width以及height进行位置编码。
3.3 Relative Position Encoding
需要构造出距离矩阵D,以及可训练的相对位置编码矩阵P(可以使用nn.embedding或者nn.parameter,构成一种字典的索引方法。i —> P[i]),其中按照论文的想法,RPE是添加在K,V中的(传统的绝对位置编码是添加在Q,K中的),并且P在网络中训练的,P的embeding为 [ 2 k + 1 , d m o d e l / n h e a d ] [2k+1, d_{model}/n_{head}] [2k+1,dmodel/nhead](注意,在attention is all you need中的absolute position encoding的 维度是d_model)。例如,对于句子中的L个words,需要设置一个截断因子K,如图4所示,对于第i个单词来说,第j个单词与它的相对距离为i,那么之间的相对距离就是j-i(但如果 j − i < k j-i<k j−i<k 或者$ j - i >k$,那么单词i与j之间的相对距离就都是K了,然后根据这个索引,去寻找对应P矩阵中的值。
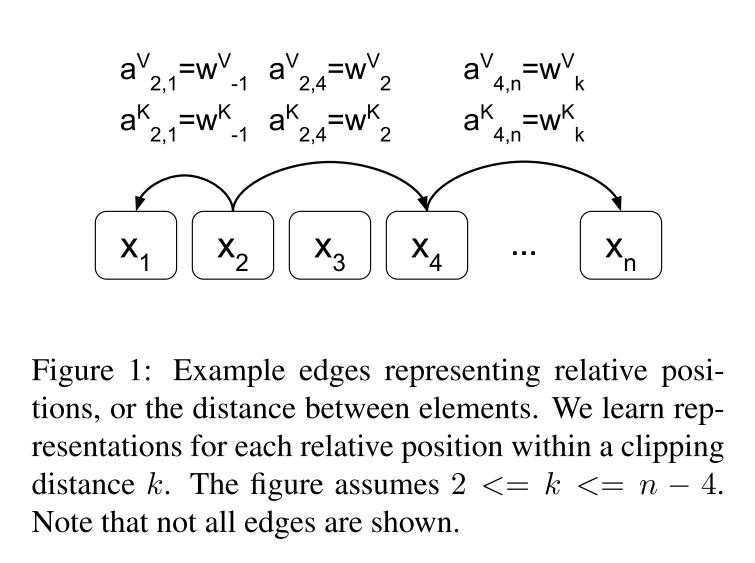
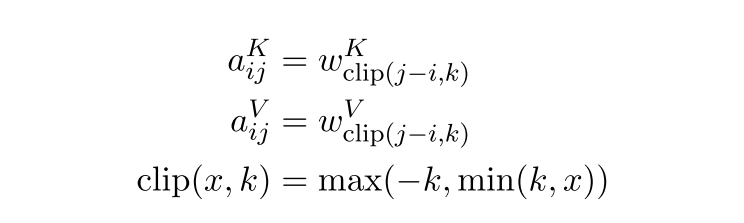
位置编码就是对每一个word或者pixel的所有的dimension进行编码,涉及到2个参数,pos以及d_i ,i是[0,d_model]。RPE满足分配率,因此可以将公式3拆开为公式4,需要注意的是PRE的维度和原始的q,k,v不同。需要考虑nheads。
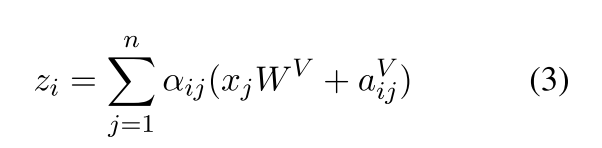
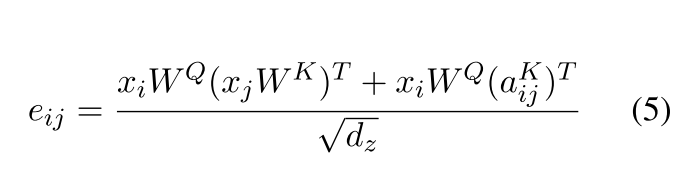
class RelativePosition(nn.Module):
def __init__(self 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章
















 5037
5037











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









