








提出一个新的适用于视觉任务的backbone,主要是以multi-head attention替换ResNet中的3x3卷积。并提出一种新的self-attention模式,在引入relative position enconding的情况下,效果不错。
摘要
本文提出一种backbone:BoTNet,适用于多种视觉任务,包括图片分类、目标检测和实例分割的backbone网络。
BoTNet将ResNet最后三个bottleneck blocks的空间卷积替换为global self-attention。
在减少参数量的同时,提高了在目标检测和实例分割上的性能。使用Mask R-CNN框架的BoTNet,在COCO实例分割数据集上,达到了44.4% Mask AP和49.7%Box AP,超过了ResNeSt。将BoTNet用于图片分类时,在ImageNet上达到了84.7%的准确率,在TPU-v3上的运行速度相较EfficientNet,快了3倍。
code for the BoT block:botnet.py · GitHub
引言
尽管卷积操作可以高效地捕捉局部信息,但诸如目标检测、实例分割、关键点检测等视觉任务需要对长距离依赖建模。以实例分割为例,获取大范围区域内的场景信息,对学习目标间的关系是很有用的。为了获得这样的信息,基于卷积的网络需要堆叠多层。尽管大量的堆叠,的确改善了这些Backbone的效果,但是建模全局依赖关系,可能是一个更好的解决方法。
视觉任务中,使用self-attention的一个简单方法是:用multi-head self-attention (MHSA)替代卷积层。
(1)SASA、SANet、Axial-SASA,提出使用不同格式的self-attention (local, global, vector, axial, etc)替代ResNet botleneck中的卷积。
(2)Vision Transformer (ViT),将无重叠的patches经过线性映射后,输入堆叠Transformer blocks。

从另一个角度看,有MHSA层的ResNet bottleneck blocks可以被视作有着Bottleneck stucture的Transformer blocks。因此,本文称ResNet Bottleneck blocks with the MHSA为Bottleneck Transformer (BoT) blocks。
在视觉任务中使用self-attention,存在下列挑战:(1)相较于图片分类(224 x 224),目标检测和实例分割的图片尺寸更大(1024 x 1024)。(2)self-attention的内存和计算scale quadratically with spatial dimensions(与空间维度呈二次关系O(n^2)),造成训练和推理的开销。
为了解决这些问题,本文设计如下:(1)使用卷积从大图片中,学习得到低分辨率的特征图;(2)使用全局(all2all)self-attention去处理和聚合特征图中的信息。这种混合设计:(1)可以使用已经较为成熟的卷积和all2all self-attention;(2)让attention在更小分辨率的特征图上工作。
对于BoTNet,它的修改仅仅有:使用BoT blocks取代ResNet的最后三个bottleneck blocks。具体来说,使用MHSA层取代ResNet的最后三个3x3卷积。


近期工作
(1)和Transformer的联系:ResNet bottleneck blocks with Multi-Head Self-Attention (MHSA)可以被视作有着bottleneck structure的Transformer blocks(1、对channel的转换;2、残差连接)。不同:(1)Normalization:Transformer使用Layer Normalization,BoT blocks使用Batch Normalization;(2)Non-Linearities(?):Transformers在FFN block中使用一个non-linearity,而BoT使用了三个;(3)Output projections:MHSA在Transformer中包含一个输出映射,而BoT中没有;(4)使用SGD而不是Transformer中的Adam optimizer。
(2)Connection to DETR:DETR是完全使用Transformer来执行region proposals和localization of objects。DETR是在backbone之外使用Transformers。即本文是提出一种Backbone,因此无法和作为检测框架的DETR或R-CNN比较。使用了Mask R-CNN和Faster R-CNN框架,暂还未使用DETR。由于BoTNet在小目标上的良好表现,本文猜测这也许可以改善DETR在小目标识别上的缺陷。
(3)Connection to Non-Local Neural Nets:Non-Local Nets在Transformer和Non-Local-Means算法之间建立了连接。他们将Non-Local模块插入到ResNet最后或最后两个blockgroups(c4, c5)中。BoTNet是一个基于卷积和Transformer的混合结构。(1)蓝色高亮的部分:position encodins和value projection并未在Non-Local Layer中使用。(2)NL blocks的channel factor reduction of 2,BoT中是4;(3)NL blocks作为额外的blcoks插入到ResNet中。

方法

把ResNet c5中的3个3x3卷积换成了MHSA,具体过程如下图所示,其中Rh和Rw是split relative position enconding。+和x分别是element wise sum和matrix multiplication。因为ResNet的c5中,第一个3x3卷积的stride是2,但是transformer不是一个strided operation,因此对第一个BoT block,我们使用了一个2x2 average-pooling。

Relative Position Encodings:为了使attention operation position aware,基于Transformer的结构都使用了position encoding。同时指出relative-distance-aware positon(来自self-attention with relative position representations,Attention augmented convolutional networks和Stand-alone self-attention in vision models)更适合视觉任务。这说明除了内容信息,不同位置特征的相对距离也很重要。
实验
batch-size = 64,APbb是average over IoU thresholds
(1)multi-scale jitter有用

(2)相对位置编码有益的,绝对位置编码甚至是有害的

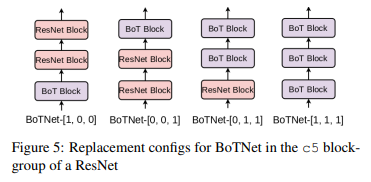
(3)BoT block放在ResNet-50不同位置

(4)对ResNet family都有用

(5)和Non-Local Neural Networks的比较
















 5037
5037











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









