






- 获取网页内容 -> (获取代码)->渲染
- 处理数据
- 储存和分析数据:数据库,ai,数据可视化
一、HTTP请求和响应:超文本传输协议
- 请求->
- 响应<-
HTTP请求
三部分:请求行(方法类型、资源路径:额外信息 查询参数、协议版本)、请求头(主机域名、客户端的相关信息、想接收的数据类型)、请求体(其他任意数据)
get方法:获得数据:得到网页内容
post方法:创建数据:提交表单
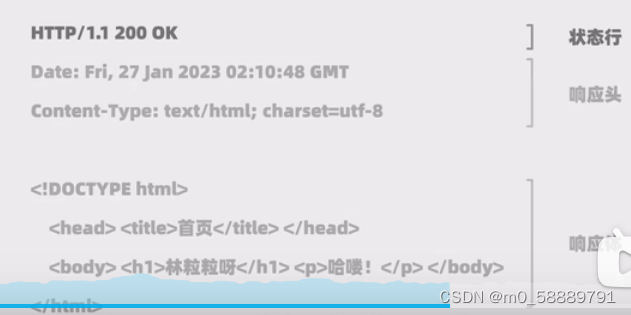
HTTP响应
三个部分:状态行(协议版本、状态码 对应、状态消息 对应)、响应头(告知客户端的信息:生成响应的时间、返回内容类型、编码)、响应体(和内容类型对应的内容)
















 823
823











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









