






DoNews12月26日消息,三星电子于 2022 年年底宣布,携手韩国互联网巨头 Naver,共同投资 AI 半导体解决方案。

能效是英伟达 H100 的 8 倍,三星携手 Naver 发布新 AI 芯片© 由 DoNews 提供
一年之后,两家公司在 AI 半导体方面已有重大突破,研制出了首款解决方案芯片,其能效是英伟达 H100 产品的 8 倍。
双方推进的半导体解决方案,专门针对 Naver 的 HyperCLOVA X 大型语言模型,定制了一块现场可编程逻辑门阵列(FPGA)芯片。
Naver 表示这款芯片采用了 LPDDR 内存,能效是 Nvidia 的 AI GPU 的八倍。
两家公司之间的合作重点是使用三星的先进工艺技术,结合利用计算存储、内存处理 (PIM)、近内存处理 (PNM) 和计算快速链路 (CXL) 等高科技内存解决方案,并整合 Naver 在软件和 AI 算法方面的实力。
内存计算有两种形式, 一种是将计算资源以高带宽的连接方式集成到主存单元中 (一般称
之为近数据计算, near data computing, NDC) [11] , 另一种是直接利用存储单元做计算 (一般称之为存内计算, compute in memory, CIM) [12] . 这两种形式都很大程度减少了中央处理器和主存之间的数据移动, 从而达到提升系统性能并降低能耗的目的.
为缓解传统冯 · 诺依曼架构中总线上的数据传输问题, 近数据计算在存储周边放置计算单元, 这就需要高速通道进行连接. 因此, 近数据计算通常依赖于 3D 堆叠的内存结构, 如图 2 所示. 近数据计算系统中通常有一个或多个 NDC cube, 它们与 CPU 或者 GPU 相连接 (如图 5 所示 [15]), 多个 NDC cube 之间可能也会存在连接. 目前基于 3D 堆叠的近数据计算的研究主要集中在: (1) NDC cube 模块与现有系统的集成方式; (2) NDC cube 和 CPU/GPU 之间, NDC cube 之间的连接方式, 通信方式以及一致性协议; (3) NDC cube 中逻辑层的设计; (4) NDC 数据映射方式; (5) NDC 的软硬件接口及上层系统软件支持. 除了基于 3D 堆叠内存结构的 NDC, 还有基于 2D NVM 的 NDC 结构, 主要思想是对 NVM 中现有外围电路进行改造, 以支持特定类型的计算.
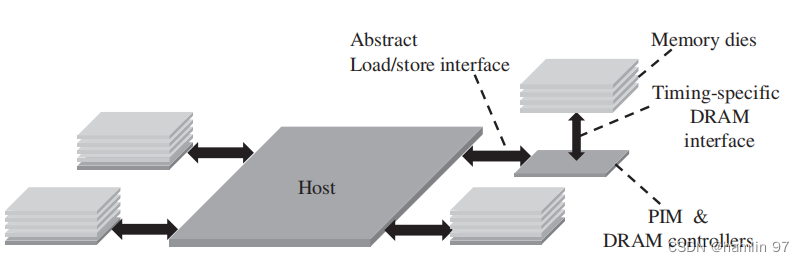
Figure1 NDC系统架构
近数据处理架构
Tom-PIM架构
TOP-PIM [15] 提出了一种近数据计算的架构, 如图 2 所示, 存储单元不直接堆叠在中央处理器上, 而是堆叠在内存处理器上, 与中央处理器进行交互. TOP-PIM 在选择内存处理器时, 考虑了能耗和热量的限制, 充分分析大量应用在性能和能耗方面的特征. TOP-PIM 认为面向吞吐量的 GPU 核更适用于高带宽高数据并行的场景. 实验表明, 在 22 nm 的工艺下, TOP-PIM 可以减少 76% 的能耗, 且仅带 来 27% 的性能损失. TOP-PIM 测试的不是某种特定类型的应用, 无法对特定类型应用加速; 另外, 它将整个应用都放到内存计算中执行, 而内存计算中的计算资源更适用于单指令多数据流的计算, 难以 支持复杂的多样的计算. 因此, TOP-PIM 在性能上不如传统冯 · 诺依曼系统.
TOM 的提出是为了解决大数据时代 GPU 与 主存之间带宽小的问题, 除了通过编译器静态分析代码块并选择合适的代码块放到内存计算中执行之 外, TOM 还分析预测了哪些数据会被放到内存计算中的代码块访问, 并将这些数据放在相应代码块 执行的 NDC cube 中, 以此来减少各个 NDC cube 之间的通信. TOM 中的代码分析和数据映射都对 上层透明, 程序员可非常方便地使用内存计算. 实验显示, TOM 平均能提高 GPU 的主流应用 30% 的性能.
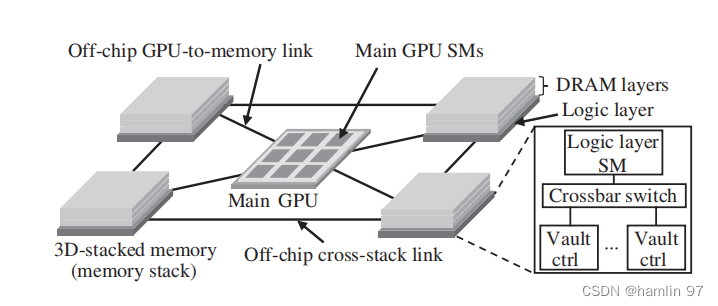
Figure2 TOM架构
PEI架构
PEI [13] 提出了一套内存计算和现有系统结合的软硬件接口. PEI 将内存计算指令计算单元 (PCU) 放在每个主处理器核以及每个内存计算核上, 使得指令可在主处理器端或内存计算端执行; 同时还加入了内存计算管理单元 (PMU), 与 LLC (last level cache) 以及主存控制器相互合作. 它的主旨是使用能够计算的存储指令和特殊指令实现简单的内存计算指令, 供上层应用所用. 在现有的顺序编程模型基础上, PEI 加入硬件单元来监测数据的局部性, 根据数据的局部性自动决定哪些操作在内存计算单元里执行. 因此, 内存计算系统能和现有的编程模型、缓存冲突处理机制, 以及虚拟内存管理很好地协作. 图3 和 4 分别给出了主处理器端和存储端内存计算指令的执行步骤, 从中可以看出, PEI 能和现有的系统结构很好地协作.
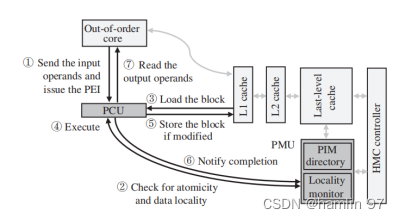
Figure3 主机端支持近存数据指令执行
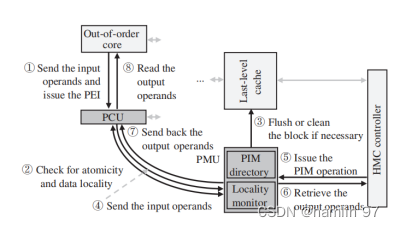
Figure4存储端支持近存数据指令执行
HRL可重构近存架构
HRL [14] 针对 NDC cube 逻辑层设计时, 片上功耗和面积限制与高带宽和充足计算量的矛盾, 提出了可重构的逻辑阵列, 能够灵活适用于大量的数据密集型应用. HRL 发现, ASIC 的设计性能好但缺少灵活性, 无法支持大量应用. FPGA 和 CGRA 通过可编程性提供了充足的灵活度. 但是 FPGA 是以比特为粒度的计算单元和互联单元可编程的硬件, 片上面积开销大; CGRA 能支持复杂数据流的强 大互联, 能耗比 FPGA 更高, 在特殊计算和不规则数据上灵活度低, 性能不佳. 因此, HRL 提出了混合可重构的逻辑阵列, 用作 NDC cube 的逻辑层, 包含了 FPGA 块和 CGRA 块. 图 5 呈现了 HRL 阵列结构, 其中, FU (function unit) 是用类 CGRA 块实现的, 保证面积和能效比, 能够支持数学运算和逻辑操作, 包括加法、减法、乘法, 和比较操作; CLB (configurable logic block) 是用类 FPGA 块实现的, 用来实现一些不规则的控制逻辑和特殊函数 (比如神经网络中的激活函数); OMB (output multiplexer block) 是由多个多工器组成的, 放置在靠近输出的位置, 用来支持计算分支, 例如树形、瀑布型, 和并行型计算, 是一种能同时节省片上面积和能耗开销的分支实现方式. 另外, HRL 没有配置类似 FPGA的 BRAM 缓存, 因为内存计算应用通常数据局部性差, 大缓存是额外负担, 不能提高系统的效率. 如上所述, HRL 综合了 FPGA 能耗低和 CGRA 面积利用率高的优点, 比基于 FPGA 的 NDC 系统性能高 2.2 倍, 比基于 CGRA 的 NDC 系统性能高 1.7 倍.
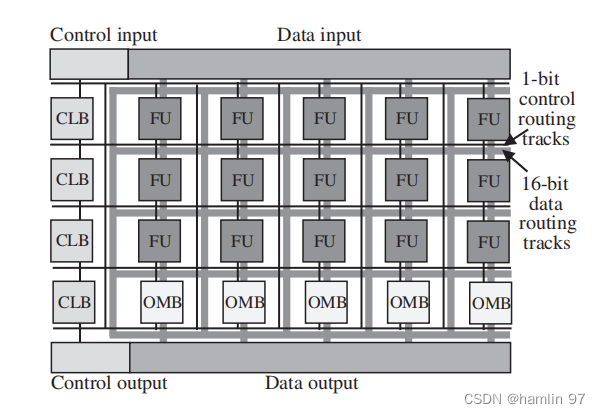
Figure5.近数据计算可重构逻辑层阵列
Neurocube架构
Neurocube [35] 是一个针对神经网络计算设计的可编程、可扩展, 且节能的近数据计算系统架构. 图 是 Neurocube 架构, 左边是普遍使用的 NDC cube 结构, 右边是逻辑层设计. 逻辑层采用了细粒度可编程的设计模型, 以灵活支持神经网络计算. 其中, 每个PE有多个MAC 单元支持神经网络中最常用的乘加操作, 同时还有存储权值的寄存器和缓存以及相应的计数器. 图6是 Neurocube 的执行流程. 它首先将神经网络存储到 NDC cube 的存储单元中, 包括每层数据、神经元状态、连接权值. 当一个层处理好之后, 与中央处理器交互一次, 然后执行下一层. Neurocube 通过对逻辑层硬件、数据映射方式、片上互联, 以及编程方式的精心设计, 使得神经网络计算在 NDC cube 中能够高效执行. 实验显示, 相比于 GPU 系统, Neurocube 有 4 倍的每瓦计算效率提升, 与 ASIC 系统相比, 灵活性更好、扩展能力更强.
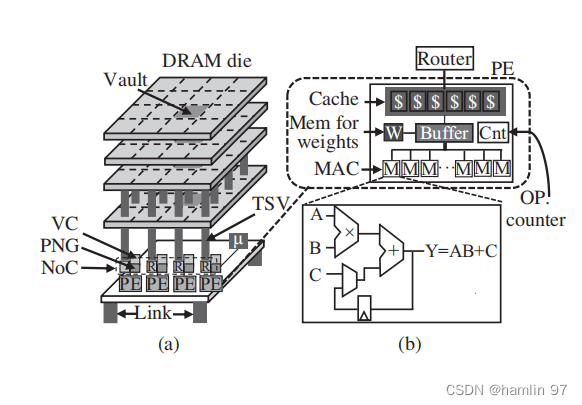
Figure6. Neurocube 的微结构和它的逻辑层中处理单元的微结构
不同于针对机器学习设计的注重优化乘加 (MAC) 操作的近数据计算系统, Co-ML [36] 提出, 虽然包含 MAC 操作的卷积层等计算占整个机器学习过程的比例大, 但这些计算是计算密集型的, 数据复用性好, 计算/字节比率高 (即一个字节从内存中读出来之后用来计算的次数多); 事实上, 机器学习过程中, 约 32% 的时间用于数据密集型计算, 这些计算的计算/字节比率低. 图6展示了神经网络中低计算/字节比率的计算部分. Co-ML 将这些低计算/字节比率的计算部分放在近数据计算端, 把 MAC等操作放在主处理器上做. 实验显示, Co-ML 在机器学习的数据密集型计算上的加速达到了 20 倍, 总体有 14% 的性能提升.
GraphPIM 架构
GraphPIM [38] 是一个针对图计算的, 基于商用 HMC2.0 的近数据计算完整解决方案. GraphPIM主要解决利用近数据计算运行图计算的两大挑战: (1) 应该把图计算应用的哪些部分放到 NDC cube中执行; (2) 如何把部分计算放到 NDC cube 中执行, 即如何提供中央处理器和近数据计算处理器的接口. GraphPIM 发现, 在图计算中, 原子操作是损害性能的主要原因, 因此应该把原子操作放到内存端, 避免不规则的数据访问带来的大通信开销. GraphPIM 使用现有的中央处理器指令, 把中央处理器端的原子操作指令映射到近数据处理端, 并使用无缓存的配置. 在 GraphPIM 架构下, 上层应用程序员无需额外的工作, 现有的指令集结构也不需要改动, 就可以在图计算的负载中使用近数据计算. 图 7 是 GraphPIM 的系统结构, GraphPIM 在图数据管理和硬件支持方面做了改动. 在虚拟地址空间中, GraphPIM 使用传统系统的指令绕过缓存来分配图数据; 在硬件端, GraphPIM 在中央处理器上加了一个 POU (PIM offloading unit) 用来决定哪些操作放到 NDC cube 中执行. 此外, GraphPIM 充分分析了图计算应用特征, 判断出哪些部分放到近数据处理端做会有性能提升. 实验显示, GraphPIM与传统用 HMC2.0 当做主存的冯 · 诺依曼系统结构相比, 有 2.4 倍的性能提升和 37% 的能耗节约。
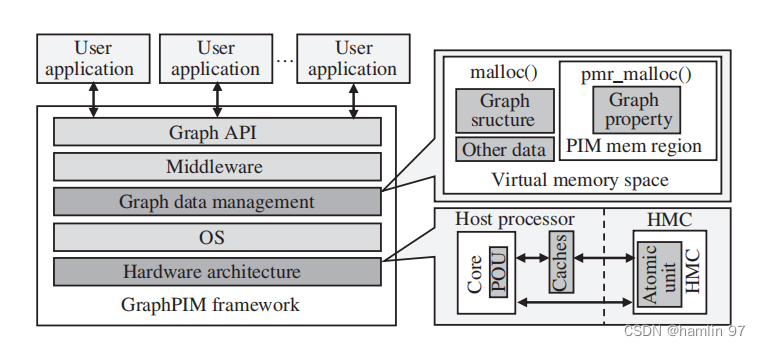
Figure7. GraphPIM 的系统架构
近数据处理挑战
近数据处理(NDP)和计算存储设备(CSD)在提高数据处理效率和降低能耗方面展现出巨大潜力,在接收多种新编程范式,保持PIM缓存一致性和支持复杂的虚拟内存方面仍面临挑战。此外,对于存储内处理(ISP),设计灵活且高效的架构,特别是在处理安全问题和文件系统集成方面仍待解决。
- 编程模型方面,代码卸载是NDP面临的一个实际挑战,因为它需要在主机侧进行多种修改,包括指令集架构(ISA)调整与编程。内存并行性将通过编程模型、库和语言实现。对于包含多个异构处理器的核心平台,需统一编程框架,以便于管理核心并行性,同时协调异构设备和主机CPU之间的交互。
- 安全性方面,保障具有计算能力的SSD的安全性至关重要,以防止对传统SSD操作干扰或对其他应用程序数据破坏修改。已经提出了使用名为IceClave的可信执行环境(TEE)来防御存储内的漏洞和攻击,这种TEE考虑了存储内工作负载特性和闪存特性。然而,像Intel的软件保护扩展(SGX)解决方案不适合现代SSD处理器解决硬件更改问题。
- 文件系统方面,存储内的数据访问可能仅限于块级别,这限制了可用编程模型类型,以及需要设定在ISP引擎内部访问元数据文件系统,以检索所需信息的机制。为CSD配备像Linux这样的操作系统有助于挂载文件系统,并支持Linux OS任何语言应用程序开发。同时,支持主机和驱动器系统操作双同步,以解决由于两个操作系统在同时访问内存阵列以及存储介质会出现的问题。
为了解决这些问题,研究人员提出了各种解决方案。例如,Lee等人开发了一个PIM框架,将PIM编程和执行概念与多核环境中的并行程序相匹配。SNIA TWG提出了一个CSD的草案文档,旨在通过使用API标准化软件应用程序接口定义,提供一种访问卸载计算设备的方法。此外,Ruan等人介绍了基于虚拟文件抽象的INSIDER,它作为主机侧编程模型,通过API访问以创建文件。Schmid等人介绍了一种近存储计算感知的文件系统,利用存储资源而不直接暴露FPGA上的物理存储位置。
这些研究和开发工作表明,尽管NDP和CSD在实际应用中面临挑战,但通过不断的技术创新和标准化工作,它们有望在未来的数据处理和存储系统中发挥重要作用。
近数据计算小结
近数据计算中逻辑层的设计较为灵活, 可以针对不同系统的需求设计通用的处理器或者专用的加速器. 在设计针对通用应用的近数据计算系统时, 由于放到内存端的通用处理器一般性能较弱, 需要 考虑自动化地分割应用程序的计算部分, 把能从近数据计算中获益的部分放到内存中处理. 在设计针对特定类型应用的近数据计算系统时, 需要仔细分析应用特点, 抽取算子, 设计对应的数据流. 除了逻辑层的设计, 近数据计算系统结构设计还需要考虑: 各个内存块之间的连接方式, 包括通信方式和数据一致性协议、数据映射策略、与现有系统集成方式、软硬件接口设计.
参考文献:
- Jiwon Choe ,Amy Huang ,Tali Moreshet ,Maurice Herlihy ,R. Iris Bahar Concurrent Data Structures with Near-Data-Processing: an Architecture-Aware Implementation,SPAA ’19, June 22–24, 2019, Phoenix, AZ, USA
- Donews:能效是英伟达 H100 的 8 倍,三星携手 Naver 发布新 AI 芯片
- Mutlu O, Ghose S, G´omez-Luna J, et al. Processing data where it makes sense: enabling in-memory computation. Microprocessors Microsyst, 2019, 67: 28–41
- Farmahini-Farahani A, Ahn J H, Morrow K, et al. NDA: near-DRAM acceleration architecture leveraging commodity DRAM devices and standard memory modules. In: Proceedings of 2015 IEEE 21st International Symposium on High Performance Computer Architecture (HPCA). Burlingame: IEEE, 2015. 283–295
- Hsieh K, Ebrahimi E, Kim G, et al. Transparent offloading and mapping (TOM): enabling programmer-transparent near-data processing in GPU systems. In: Proceedings of ACM/IEEE 43rd Annual International Symposium on Computer Architecture (ISCA), 2016. 44: 204–216
- 黄璜,张乾 . 存算一体技术产业发展研究[J]. 信息通信技术与政策, 2023,49 (6):


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









