







第一步:CycleGan介绍
AnimeGAN是来自武汉大学和湖北工业大学的一项研究,采用的是神经风格迁移 + 生成对抗网络(GAN)的组合。

第二步:AnimeGAN网络结构
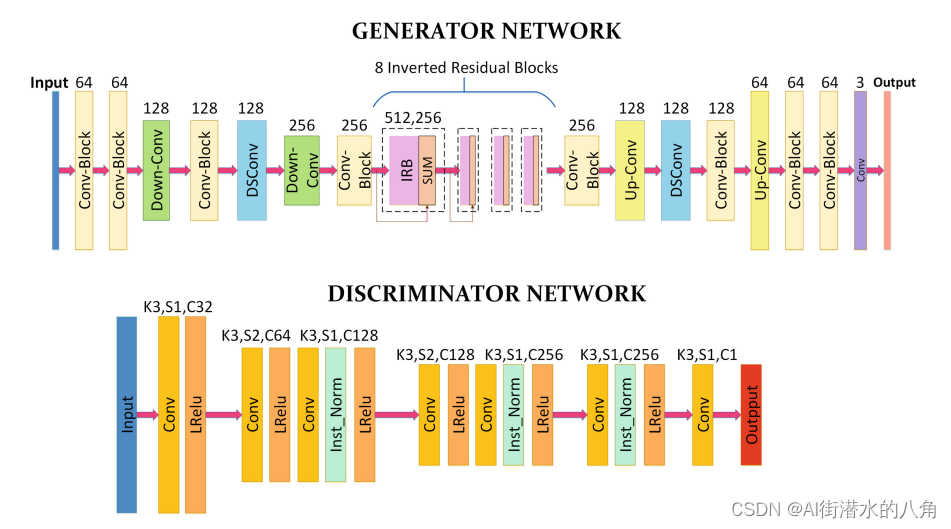
第三步:模型代码展示
from tools.ops import *
import tensorflow as tf
def Conv2D(inputs, filters, kernel_size=3, strides=1, padding='VALID', Use_bias = None):
if kernel_size == 3:
inputs = tf.pad(inputs, [[0, 0], [1, 1], [1, 1], [0, 0]], mode="REFLECT")
return tf.contrib.layers.conv2d(
inputs,
num_outputs=filters,
kernel_size=kernel_size,
stride=strides,
biases_initializer= Use_bias,
normalizer_fn=None,
activation_fn=None,
padding=padding)
def Conv2DNormLReLU(inputs, filters, kernel_size=3, strides=1, padding='VALID', Use_bias = None):
x = Conv2D(inputs, filters, kernel_size, strides,padding=padding, Use_bias = Use_bias)
x = instance_norm(x,scope=None)
return lrelu(x)
def dwise_conv(input, k_h=3, k_w=3, channel_multiplier=1, strides=[1, 1, 1, 1],
padding='VALID', stddev=0.02, name='dwise_conv', bias=False):
input = tf.pad(input, [[0, 0], [1, 1], [1, 1], [0, 0]], mode="REFLECT")
with tf.variable_scope(name):
in_channel = input.get_shape().as_list()[-1]
w = tf.get_variable('w', [k_h, k_w, in_channel, channel_multiplier],regularizer=None,initializer=tf.truncated_normal_initializer(stddev=stddev))
conv = tf.nn.depthwise_conv2d(input, w, strides, padding, rate=None, name=name, data_format=None)
if bias:
biases = tf.get_variable('bias', [in_channel * channel_multiplier],initializer=tf.constant_initializer(0.0))
conv = tf.nn.bias_add(conv, biases)
return conv
def Separable_conv2d(inputs, filters, kernel_size=3, strides=1, padding='VALID', Use_bias = None):
if kernel_size==3 and strides==1:
inputs = tf.pad(inputs, [[0, 0], [1, 1], [1, 1], [0, 0]], mode="REFLECT")
if strides == 2:
inputs = tf.pad(inputs, [[0, 0], [0, 1], [0, 1], [0, 0]], mode="REFLECT")
return tf.contrib.layers.separable_conv2d(
inputs,
num_outputs=filters,
kernel_size=kernel_size,
depth_multiplier=1,
stride=strides,
biases_initializer=Use_bias,
normalizer_fn=tf.contrib.layers.instance_norm,
activation_fn=lrelu,
padding=padding)
def Conv2DTransposeLReLU(inputs, filters, kernel_size=2, strides=2, padding='SAME', Use_bias = None):
return tf.contrib.layers.conv2d_transpose(inputs,
num_outputs=filters,
kernel_size=kernel_size,
stride=strides,
biases_initializer=Use_bias,
normalizer_fn=tf.contrib.layers.instance_norm,
activation_fn=lrelu,
padding=padding)
def Unsample(inputs, filters, kernel_size=3):
'''
An alternative to transposed convolution where we first resize, then convolve.
See http://distill.pub/2016/deconv-checkerboard/
For some reason the shape needs to be statically known for gradient propagation
through tf.image.resize_images, but we only know that for fixed image size, so we
plumb through a "training" argument
'''
new_H, new_W = 2 * tf.shape(inputs)[1], 2 * tf.shape(inputs)[2]
inputs = tf.image.resize_images(inputs, [new_H, new_W])
return Separable_conv2d(filters=filters, kernel_size=kernel_size, inputs=inputs)
def Downsample(inputs, filters = 256, kernel_size=3):
'''
An alternative to transposed convolution where we first resize, then convolve.
See http://distill.pub/2016/deconv-checkerboard/
For some reason the shape needs to be statically known for gradient propagation
through tf.image.resize_images, but we only know that for fixed image size, so we
plumb through a "training" argument
'''
new_H, new_W = tf.shape(inputs)[1] // 2, tf.shape(inputs)[2] // 2
inputs = tf.image.resize_images(inputs, [new_H, new_W])
return Separable_conv2d(filters=filters, kernel_size=kernel_size, inputs=inputs)
class G_net(object):
def __init__(self, inputs):
with tf.variable_scope('G_MODEL'):
with tf.variable_scope('b1'):
inputs = Conv2DNormLReLU(inputs, 64)
inputs = Conv2DNormLReLU(inputs, 64)
inputs = Separable_conv2d(inputs,128,strides=2) + Downsample(inputs, 128)
with tf.variable_scope('b2'):
inputs = Conv2DNormLReLU(inputs, 128)
inputs = Separable_conv2d(inputs, 128)
inputs = Separable_conv2d(inputs, 256, strides=2) + Downsample(inputs, 256)
with tf.variable_scope('m'):
inputs = Conv2DNormLReLU(inputs, 256)
inputs = self.InvertedRes_block(inputs, 2, 256, 1, 'r1')
inputs = self.InvertedRes_block(inputs, 2, 256, 1, 'r2')
inputs = self.InvertedRes_block(inputs, 2, 256, 1, 'r3')
inputs = self.InvertedRes_block(inputs, 2, 256, 1, 'r4')
inputs = self.InvertedRes_block(inputs, 2, 256, 1, 'r5')
inputs = self.InvertedRes_block(inputs, 2, 256, 1, 'r6')
inputs = self.InvertedRes_block(inputs, 2, 256, 1, 'r7')
inputs = self.InvertedRes_block(inputs, 2, 256, 1, 'r8')
inputs = Conv2DNormLReLU(inputs, 256)
with tf.variable_scope('u2'):
inputs = Unsample(inputs, 128)
inputs = Separable_conv2d(inputs, 128)
inputs = Conv2DNormLReLU(inputs, 128)
with tf.variable_scope('u1'):
inputs = Unsample(inputs,128) # The number of the filters in this layer is 128 while it is 64 in the graph of the paper. Please refer to the code.
inputs = Conv2DNormLReLU(inputs, 64)
inputs = Conv2DNormLReLU(inputs, 64)
out = Conv2D(inputs, filters =3, kernel_size=1, strides=1)
self.fake = tf.tanh(out)
def InvertedRes_block(self, input, expansion_ratio, output_dim, stride, name, reuse=False, bias=None):
with tf.variable_scope(name, reuse=reuse):
# pw
bottleneck_dim = round(expansion_ratio * input.get_shape().as_list()[-1])
net = Conv2DNormLReLU(input, bottleneck_dim, kernel_size=1, Use_bias=bias)
# dw
net = dwise_conv(net, name=name)
net = instance_norm(net,scope='1')
net = lrelu(net)
# pw & linear
net = Conv2D(net, output_dim, kernel_size=1)
net = instance_norm(net,scope='2')
# element wise add, only for stride==1
if (int(input.get_shape().as_list()[-1]) == output_dim) and stride == 1:
net = input + net
return net
第四步:运行


第五步:整个工程的内容
代码的下载路径(新窗口打开链接):基于深度学习神经网络AnimeGAN转动漫系统

有问题可以私信或者留言,有问必答

















 1755
1755

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









