







目录
制作系统盘 & ubuntu20系统安装 &机械盘挂载 & 网络配置 &RAID简介
软件的配置& 基础软件安装 &搜狗输入法配置&远程SSH相关&系统默认内核&数据闭环设备
docker安装&镜像拉取加速&去除sudo限制&修改镜像存储位置&docker compose&docker 命令汇总
anconda安装&conda环境创建&pytorch-gpu安装&容器基础配置错误集&cuda安装&cudnn安装
机械盘热插拔&NFS远程挂载&数据闭环系统&docker简介&docker基本概念&docker数据卷
linux常见基础命令&vscode编辑器搭建&vscode虚拟环境使用&vscode的debug功能&vscode远程链接服务器
1.4 深度学习镜像
- 深度学习环境搭建步骤大致分为:安装GPU驱动 ---> 安装nvidia-docker --> 拉取带有dudnn/cuda的镜像 --> 创建容器 --> 安装conda【下节叙述】-->导出容器为镜像传递
1. GPU驱动安装
- 前提:一定不能更新内核
1. 在1.1 的第2节讲述过,关闭系统内核更新问题;
2. 如果内核发生更新,推荐新手直接重装系统,参考1.1的第2节;
3. 也可以尝试降低内核,设定服务器启动时自动启用内核,参考1.2的第5节
- 更新软件包列表:sudo apt-get update
- 查看推荐安装驱动:ubuntu-drivers devices
- 安装相关驱动:sudo apt install ubuntu-drivers-common nvidia-driver-xxx
注释:xxx是系统推荐的驱动版本,如535
- 重启系统:reboot
- 进入Perform Mok Management界面:Enroll Mokè Continueè yesè Rebootè GPU正常工作
- 查看驱动版本:nvidia-smi 显示的CUDA为最高版本的cuda
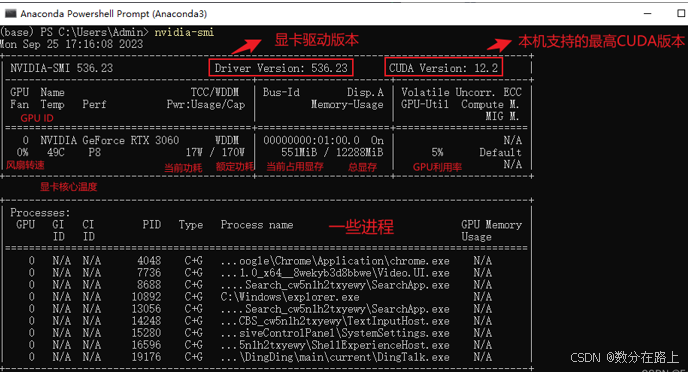
上述展示指标,需要重点记忆,后续深度学习需要经常进行查看,也会重新叙述。
lightdm安装:sudo apt-get install lightdm ---> 跳转界面选择lightdm ---> reboot
2. nvidia docker
- 原因:nvidia-docker 解决了Docker 只能使用 CPU 的资源问题,可以使用GPU,其已经更新为NVIDIA Container Toolkit
- 安装前提:安装NVIDIA驱动、docker
- 安装步骤
- 添加NVIDIA的GPG秘钥:curl -s -L https://nvidia.github.io/nvidia-docker/gpgkey | sudo apt-key add -
- 获取操作系统发行信息:distribution=$(. /etc/os-release;echo $ID$VERSION_ID)
- 添加Nvidia的软件包存储库:curl -s -L https://nvidia.github.io/nvidia-docker/$distribution/nvidia-docker.list | sudo tee /etc/apt/sources.list.d/nvidia-docker.list
- 更新源:sudo apt update
- 安装软件包: sudo apt install -y nvidia-container-toolkit
- 重启docker: sudo systemctl restart docker
3. 深度学习镜像查找拉取
- 概述:拉取带有NVIDIA GPU的docker镜像,然后创建相关容器,可以证明nvidia docker(nvidia-container-toolkit)安装成功。
一般来说,基于nvidia/cuda创建后续深度学习的环境,且大部分深度学习基于的cuda版本为11.1,torch版本为1.9.0
- 前提条件: 具有GPU驱动、NVIDIA-Docker(nvidia-container-toolkit)
- 拉取镜像:登录docker hub --> 输入nvidia/cuda查找镜像--> 进入“Tags”查找指定版本镜像拉取命令 (如 docker pull nvidia/cuda:11.1.1-cudnn8-devel-ubuntu20.04)
拉取镜像的tag一般包含:系统版本(ubuntu20),cuda版本(11.1) , 带有cudnn 的devel版本
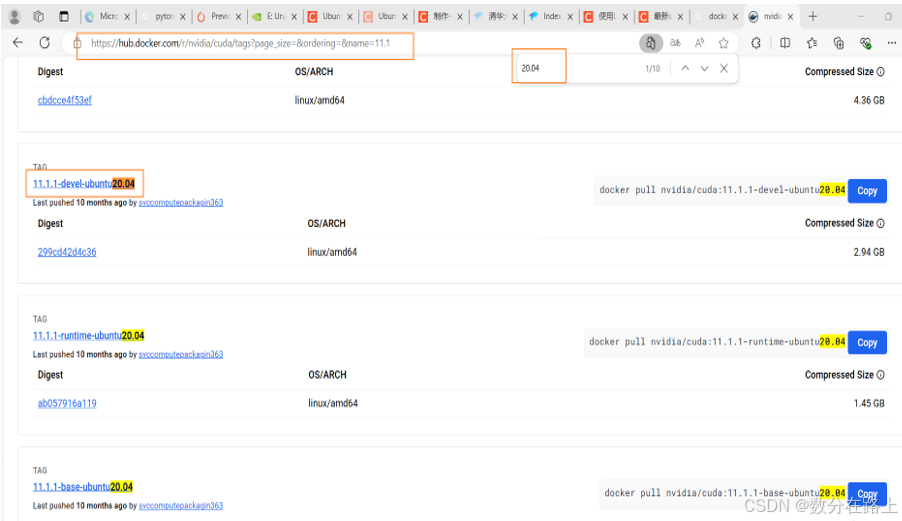
4. 深度学习容器创建
- 创建命令:sudo docker run -it --name deeplean_env --shm-size=32G --privileged=true --gpus all --net=host -v /mnt/volume_1T/docker_relate/docker_env:/deep_lean_env -v /etc/localtime:/etc/localtime:ro -v /tmp/.X11-unix:/tmp/.X11-unix -e DISPLAY=unix$DISPLAY -e GDK_SCALE -e NVIDIA_DRIVER_CAPABILITIES=compute,utility -e LANG=en_US.UTF-8
- -e GDK_DPI_SCALE nvidia/cuda:11.1.1-cudnn8-devel-ubuntu20.04 /bin/bash
- 说明1: 常见docker命令见1.3 的第6节
- 说明2: 创建成功验证
- nvidia-smi查看驱动; nvcc –version 查看cuda版本
- 一般来说,cuda版本可以低于 nvidia-smi查看的驱动版本
- 说明3:容器中,类似于一个才装配的ubuntu系统环境,需要我们重新配置一些环境,常见的配置包含:
- 镜像中已包含:cuda/cudnn环境 【如果没有安装,参考下节1.5】
- 基础加速器:阿里云镜像加速、 配置ssh 【参考1.2】
- 基础安装包:apt-get -y install locales wget git net-tools
- anaconda:参考下节1.5。
- 说:4:上述创建命令含义
- sudo docker run: 赋权创建docker容器,且可以使用显卡; (有时用nvidia-docker)
- -it:-i表示保持容器一直运行;-t表示为容器重新分配一个伪终端;-d表示以守护(后台)模式运行容器;通常使用-it创建的容器称为交互式容器;而-id创建的容器称为守护式容器;
- --name deeplean_env:表示创建的容器名称为deeplean_env;
- --shm-size=32G :容器中共享内存大小;
- --privileged=true:容器中启动进程时不添加任何安全限制;
- --gpus all :可用服务器上所有的GPU资源
- --net=host:主机本机运行,更好的访问网络
- -v /mnt/volume_1T/docker_relate/docker_env:/deep_lean_env:表示本机路径(/mnt/volume_1T/docker_relate/docker_env)与容器路径(/deep_lean_env)之间挂载关系
- -v /etc/localtime:/etc/localtime:ro:容器时间与本地时间一致
- 图形可视化界面:-v /tmp/.X11-unix:/tmp/.X11-unix(共享本地unix端口);-e DISPLAY=unix$DISPLAY(修改环境变量DISPLAY);-e GDK_SCALE -e GDK_DPI_SCALE(显示效果相关环境变量)
- -e NVIDIA_DRIVER_CAPABILITIES=compute,utility: 设置 NVIDIA 驱动的功能集,compute 功能集通常用于 GPU 加速的计算任务,utility 功能集则包括一些实用工具功能
- -e LANG=en_US.UTF-8: 设置应用程序的语言和字符编码
- nvidia/cuda:11.1.1-cudnn8-devel-ubuntu20.04:基于的镜像名称和标签
- /bin/bash:进入容器的初始化指令
说明:如果容器中无法显示中文,可是使用sudo docker exec -it 容器名称 env LANG=C.UTF-8 /bin/bash 进入容器如
5. 容器导出为镜像
- 背景:在日常工作中,跨设备进行深度学习环境复刻,往往是通过将容器打包成镜像传递方式进行;
- 打包基本步骤:清除缓存 ---> 打包镜像
apt clean && rm -rf /tmp/* /var/tmp/* /var/lib/apt/lists/* /var/cache/apt/* # 系统缓存
pip cache purge rm -rf $(pip cache dir)/* # pip缓存
conda clean –all # conda缓存
本地容器打包成镜像:sudo docker commit 容器id 镜像名:版本号(tag)
镜像导出为压缩包:sudo docker save -o 路径/压缩文件名称 镜像名:版本号(tag)
加载本地镜像:sudo docker load –i 压缩镜像名(tar)
- 注意事项:在我日常工作中,经常出现由容器打包成的镜像无法再其他设备导入,其解决办法一般是重新导出一份镜像即可。 【一般导出镜像可以先本地load测试】
- 说明:在理论上来说,创建基础版本的深度学习镜像,需要基于dockerfile创建,优点是镜像的大小相对小很多,易于传递使用,但该部分相对来说知识量较多,目前我遇到的上述方式打包镜像对比原始镜像大了约7-8G,个人感觉这个大小对于服务器来说是微不足道的。
参考博文



















 905
905

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











