









前言
现在网络上有许多免费的 Stable Diffusion AI 图片生成工具,例如 Fast Stable Diffusion XL、Stable Diffusion Online 和 Tensor Art 等。这些工具都是基于免费模型,许多人可能想尝试直接在电脑上运行。
过去的安装步骤需要 Python,对于普通用户来说可能有些困难。今天小妹分享一个更简单的方法:“ComfyUI”,它可以让你轻松地在本地运行 Stable Diffusion AI 绘图。
ComfyUI 不仅支持 Windows,还有 Mac 版本。有兴趣的用户可以访问 GitHub 了解如何安装,本教程主要针对 Windows 用户。
第一时间白嫖各种软件,一定这样做
为您推荐
Windows 11 LTSC RTM 正式版,ISO 下载…
微软牛x,Microsoft Edge 手机版现在支持安装所有扩展
如何在Windows 中安装 Stable Diffusion,目前最简单的运行方式
想在 Windows 中运行 Stable Diffusion,只需要4 个步骤,不用任何技术背景:
- 下载 ComfyUI
- 下载指定 Stable Diffusion
- 把下载的文件放进 ComfyUI 资料夹内
- 开始 AI 绘图
注意事项
在进行绘图时,需要注意 Prompt 只能输入英文,不支持中文输入。

通过今天分享的 ComfyUI,用户还可以安装 ComfyUI Manager 管理工具,从而获得更多 Node,实现更高品质和更多控制性的 AI 绘图,有兴趣的用户可以自行研究。
1. 下载 ComfyUI
访问 ComfyUI 的项目地址,往下滑找到“Installing”,点击“Direct link to download”就会开始下载,文件约 1.34GB,格式是 7z(可以通过 Winrar 或 7zip 进行解压,最新版 Windows 11 无需第三方软件即可解压)。
所有的下载链,请在文章末尾获取。
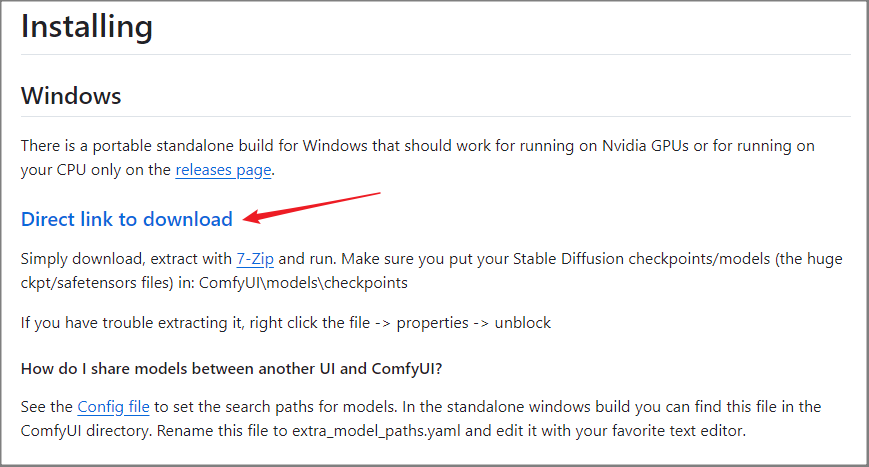
下载好后解压缩,解压缩后的文件是 4.81 GB,相当大,再加上模型,建议至少保留 50GB 的储存空间。
解压缩后会看到有两个批处理文件“run_cpu.bat”和“run_nvidia_gpu.bat”,就如同文件名称,如果你有 NVIDIA 显卡且 VRAM 超过 8GB,那就使用 run_vidia_gpu,比起 CPU 绘图速度会快很多。
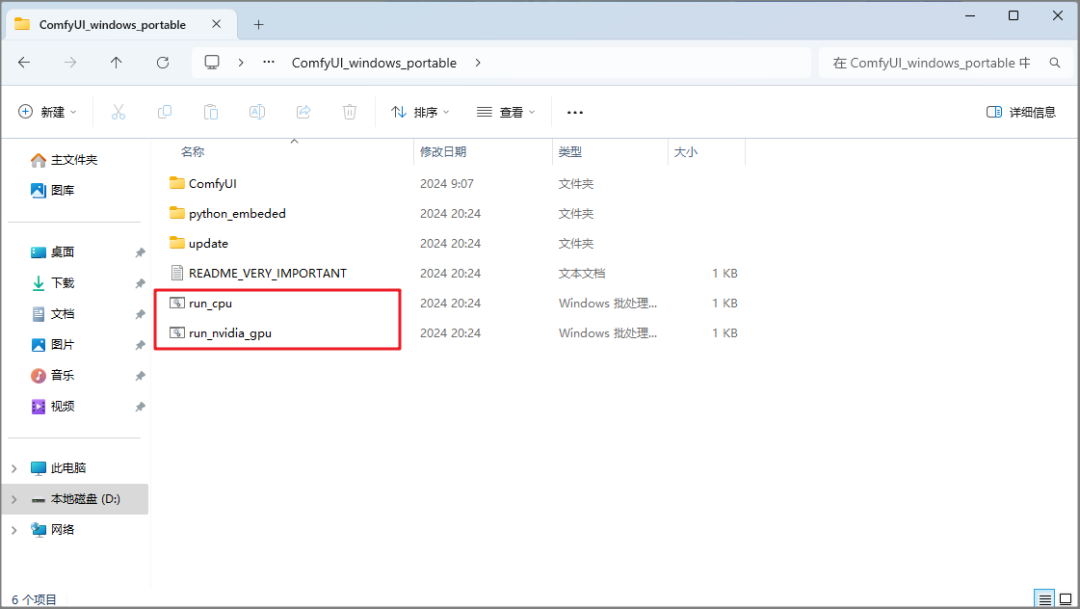
鼠标双击 “run_cpu.bat”,会跳出一个命令提示窗口,等待几秒,接着就会看到浏览器打开 ComfyUI 的操作界面,看起来好像很难,但实际上非常简单,后面会有详细介绍。
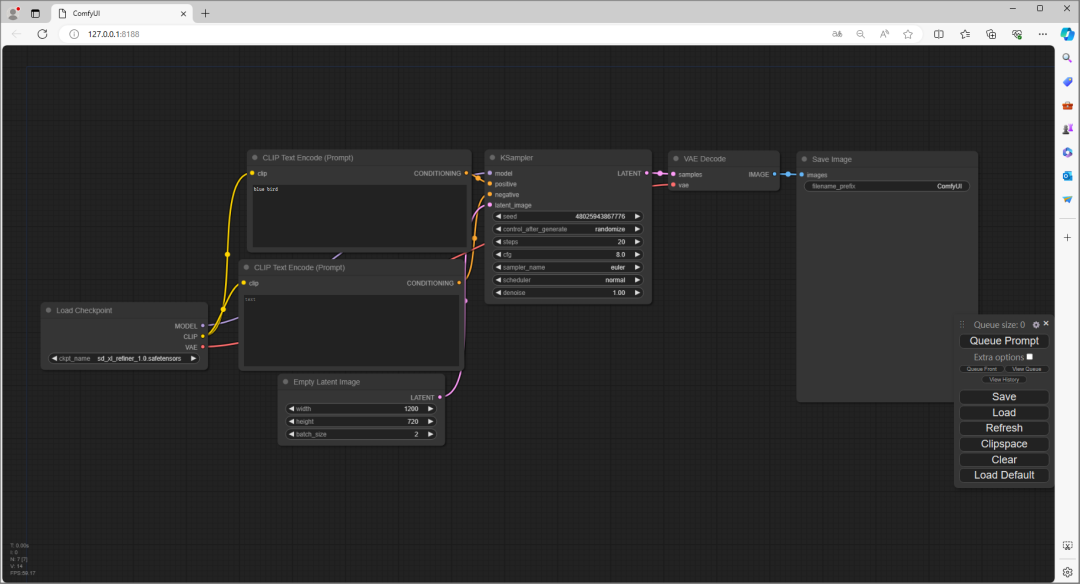
目前一开始没有任何模型,所以最左边 Load Checkpoint 没有任何东西可选。
所以接下来就是下载并添加模型数据。
2. 下载指定 Stable Diffusion 模型
总共有 3 个模型文件需要下载:
- Stable Diffusion XL Base 1.0
- Stable Diffusion XL Refiner 1.0
- SDXL-VAE
首先下载 Base 1.0,访问下载的页面后往下滑。
下载后面扩展名为"safetensors"的文件,这是 Stable Diffusion XL 的基础模型。
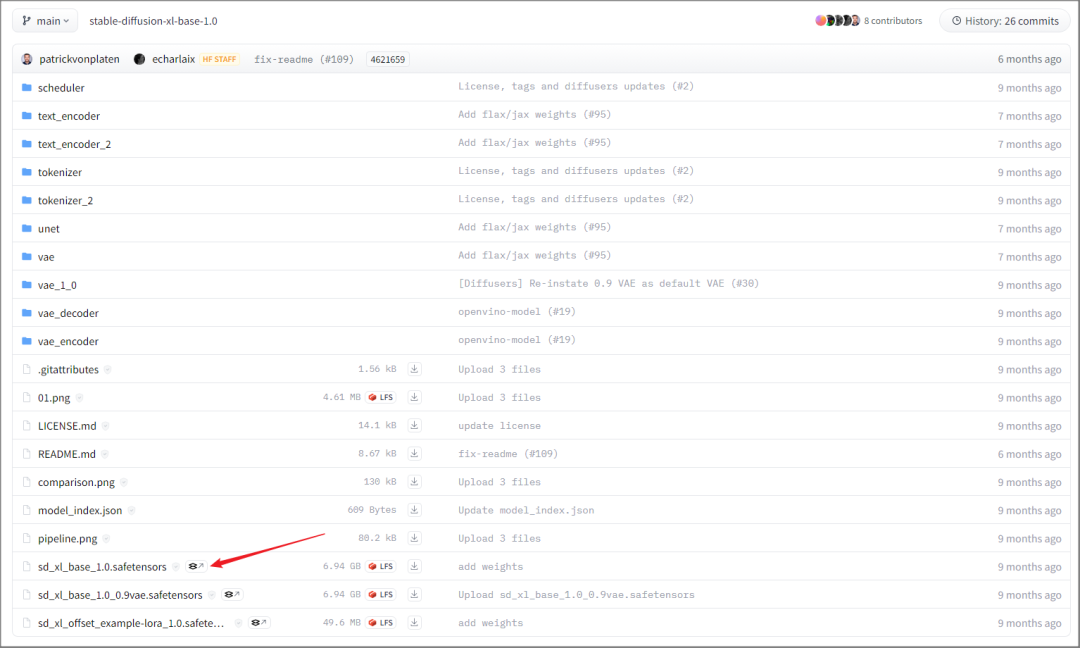
再来是 Stable Diffusion XL Refiner 1.0,一样是下载扩展名为"safetensors"的文件。
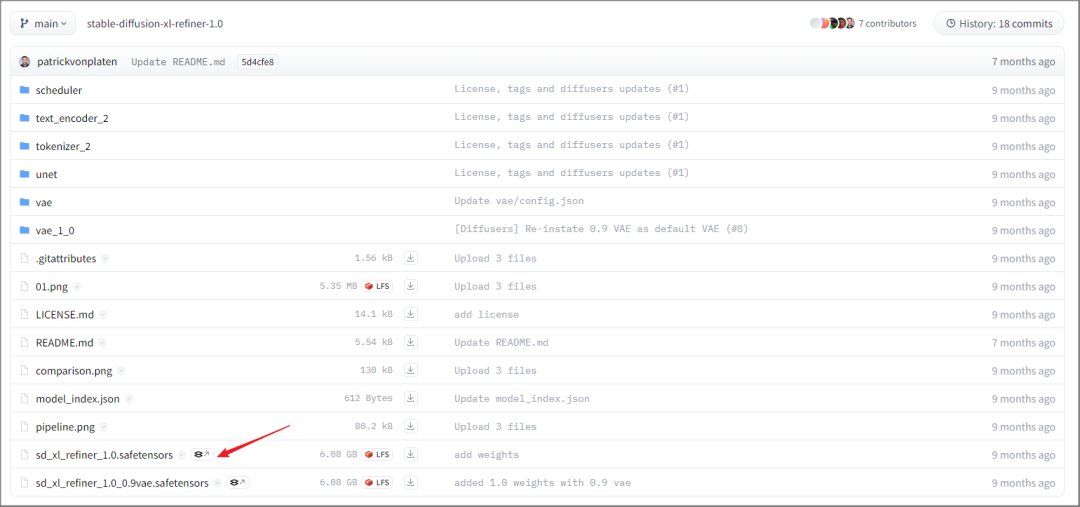
最后是 SDXL-VAE,也是下载扩展名为"safetensors"的文件。
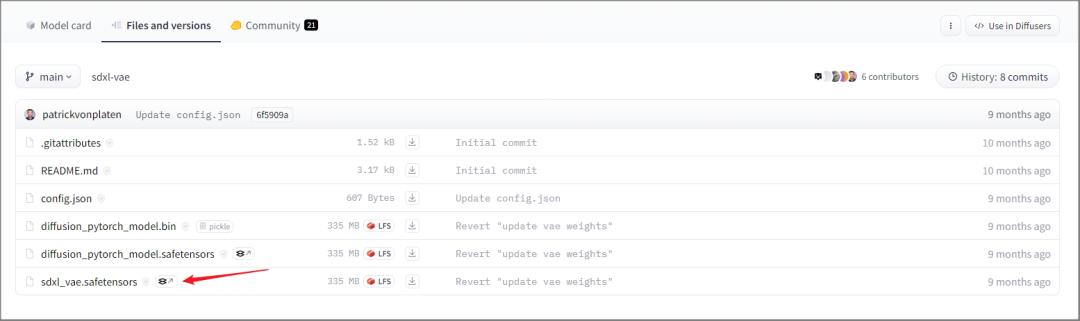
目前所有需要的文件已经完成。
3. 把模型文件放进 ComfyUI 文件夹内
下载后有三个模型文件,"sd_xl_base_1.0.safetensors"和"sd_xl_refiner_1.0.safetensors"放在同一个文件夹,“sdxl_vae.safetensors”则是另一个。
"sd_xl_base_1.0.safetensors"和"sd_xl_refiner_1.0.safetensors"就放在“ComfyUI(第一次下载的压缩包解压后)”文件夹下的“ComfyUI_windows_portable\ComfyUI\models\checkpoints”文件夹中,未来如果下载其他别人优化过的模型,也是放在这边。
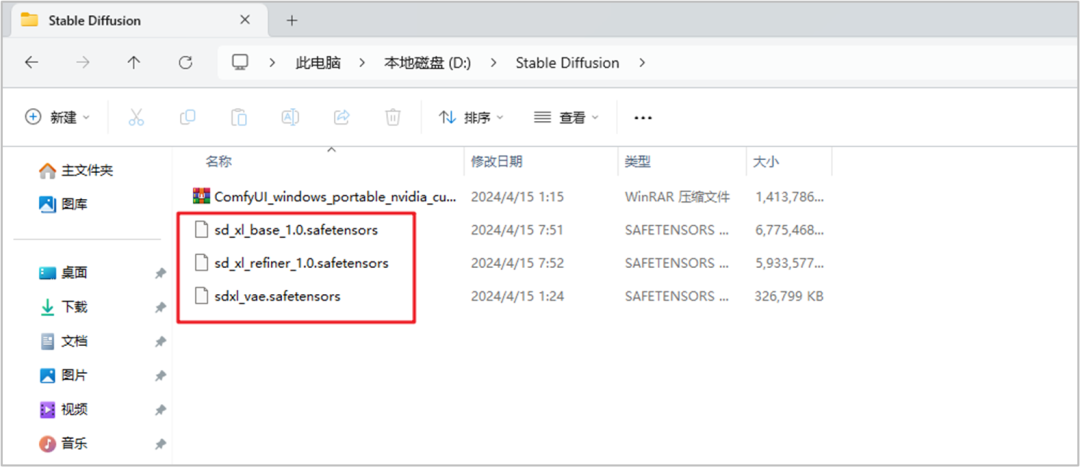
“vae”则是放在“ComfyUI_windows_portable\ComfyUI\models\vae”文件夹中。完成之后,再次执行 ComfyUI,鼠标双击 “run_cpu.bat”。
4. 开始AI 绘图
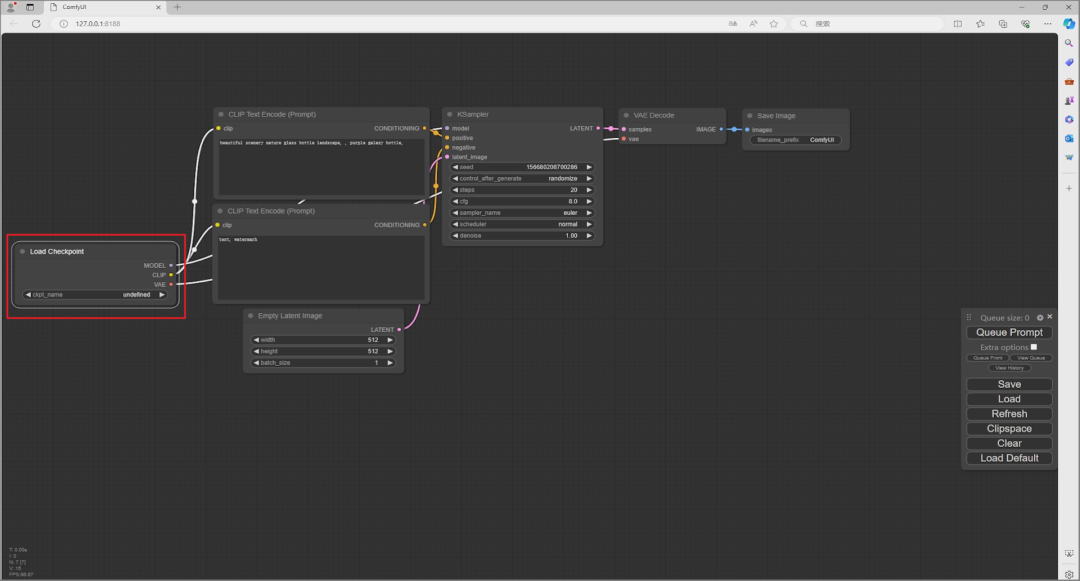
回到ComfyUI的界面后,在“Load Checkpoint”选框中,就能选择刚刚放进文件夹的 SDXL 模型。以“Base”为例,简单来说,“Load Checkpoit”就是选择你要用的模型。
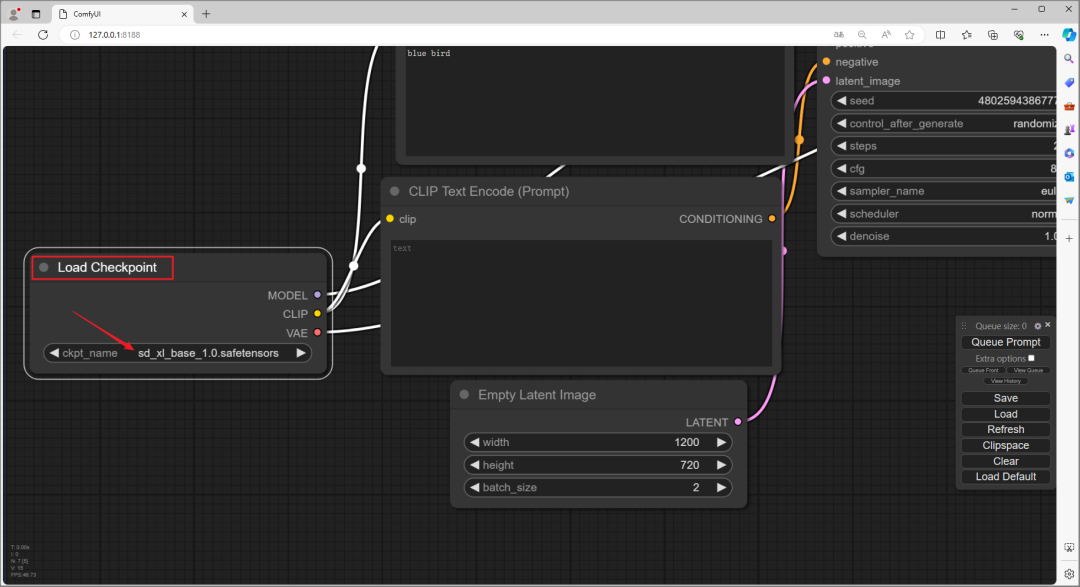
“CLIP Text Encode”部份,上方“Prompt”,就是输入你要的图片描述,下方则是不想出现在图片里的描述。
在上面输入“blue Car”,生成蓝色的车子,下方输入“text”,不要出现文本。
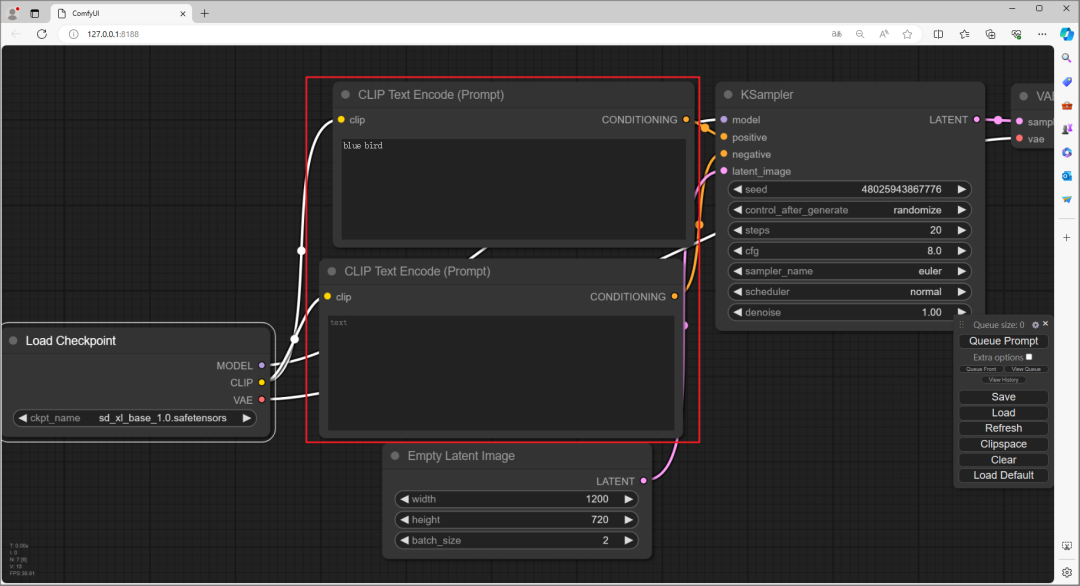
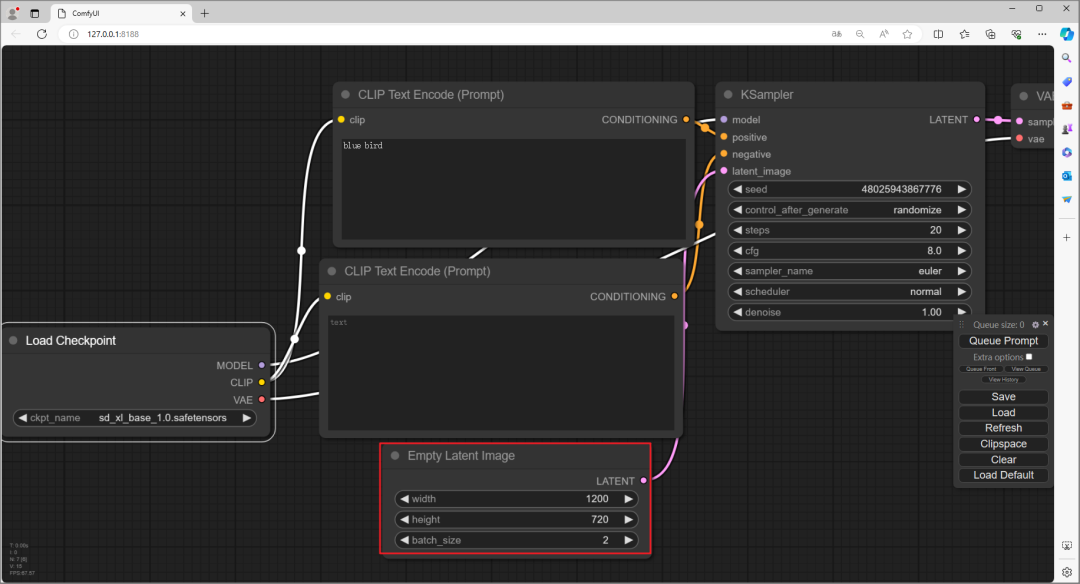
“Empty Latent Image”是图片解析度和一次生成几张的设置,小妹设定成1200×720,一次生成 2 张图片。
“KSampler”是图片更细节的设置,这部份可以全部都保留预设,生成完后再慢慢调整,看每一个设定的差异。
以上都设置好后,按右边的“Queue Prompt”就会开始执行。画面中出现绿色框框的地方,就是目前运行到的位置。
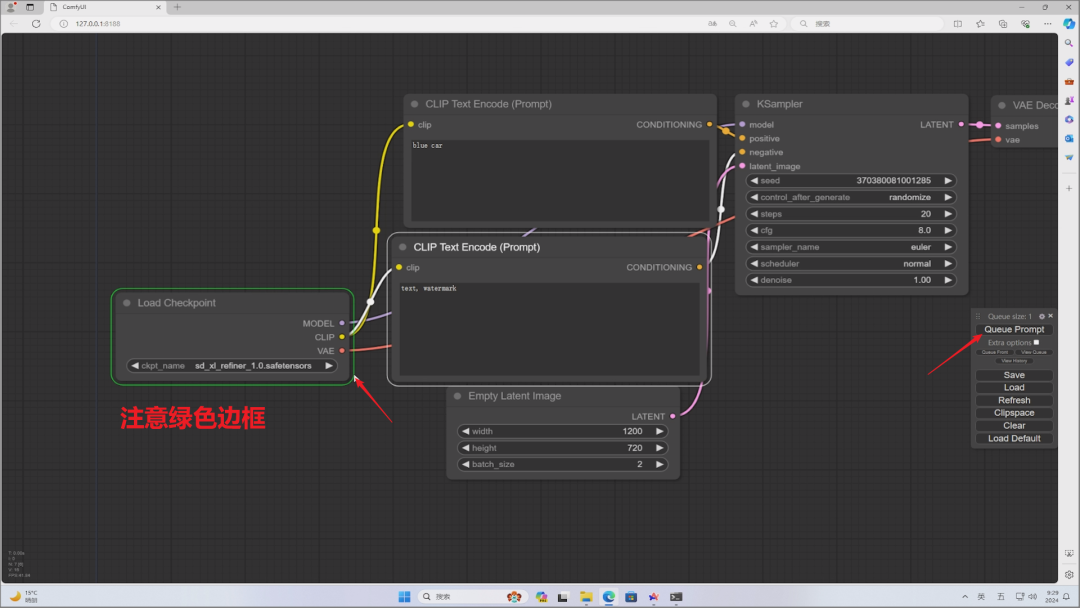
完成后,产生出的 AI 图片会显示在最右边“Save Image” 中。
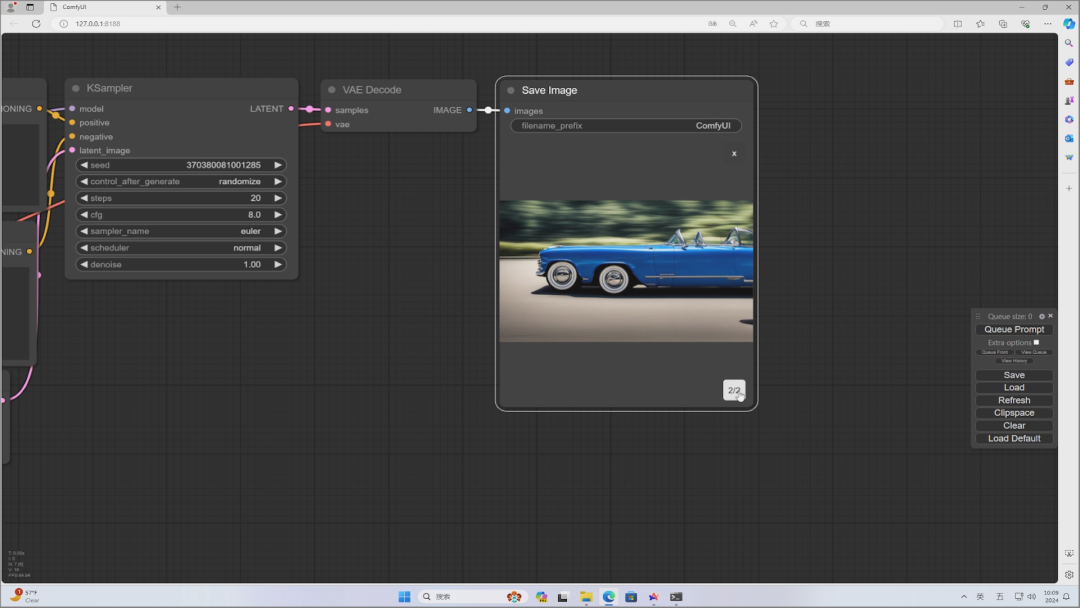
如果满意的话,在图片上点击鼠标右键,选择“Save Image”就能下载到电脑里。
5. 下载更多优化模型
想要玩玩看其他人优化过的模型,可以到 CIVITAI 这个网站,有超多Stable Diffusion 模型可免费下载。
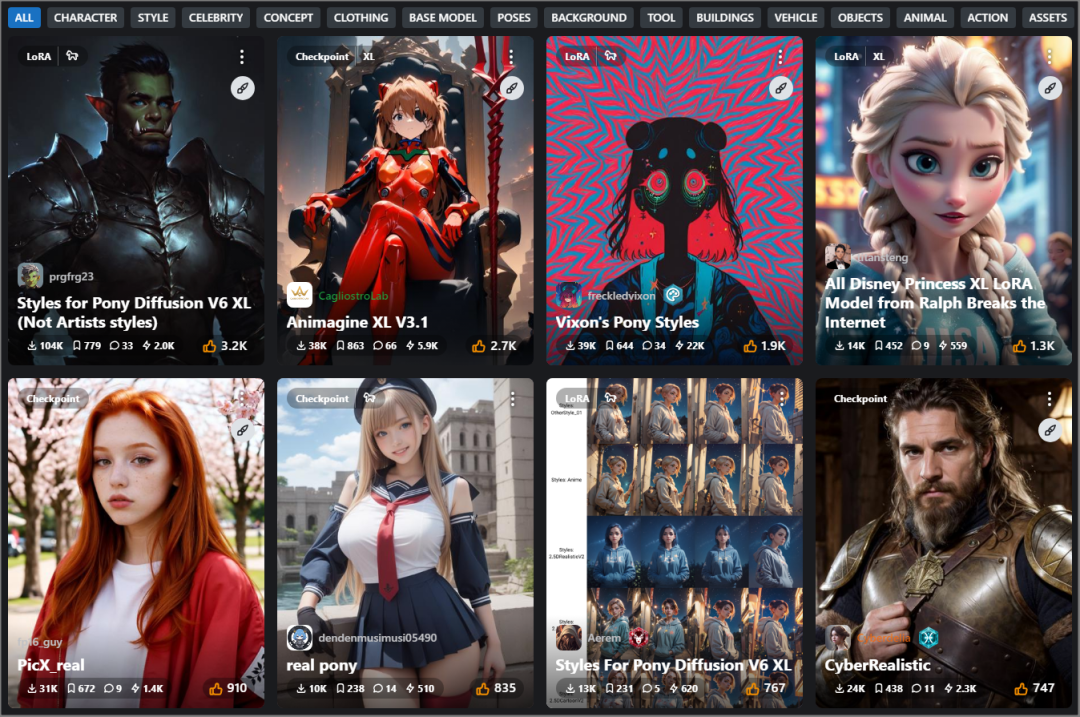
下载方式也很简单,需注册会员,然后打开喜欢的模型页面,右侧就能看到下载图示。
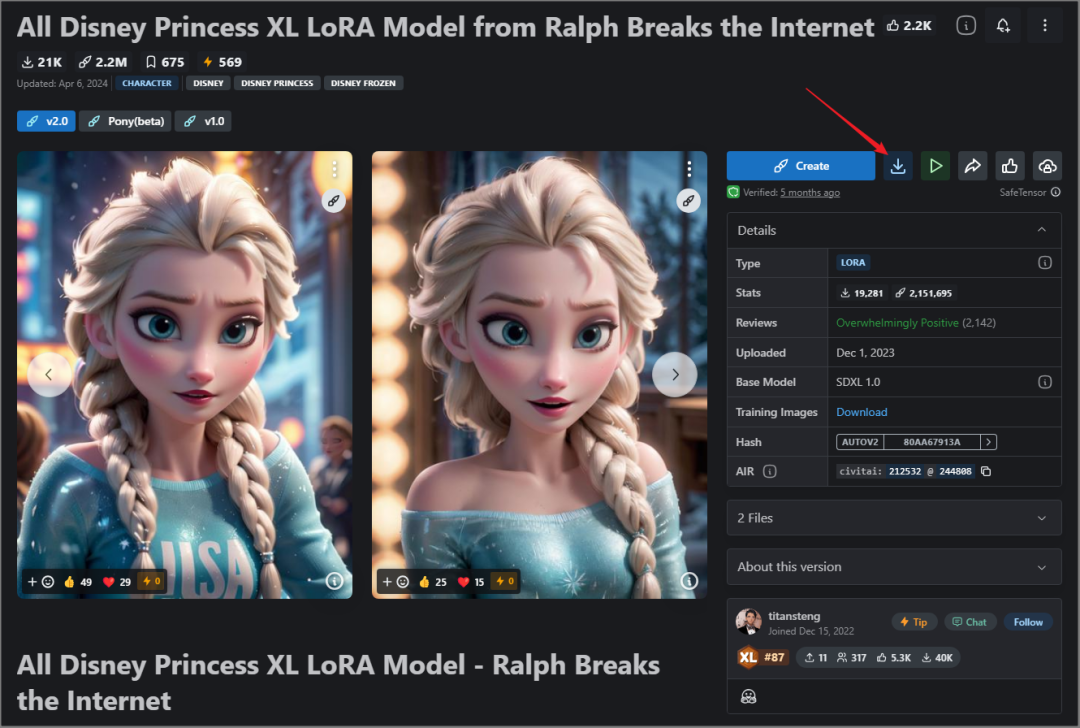
另外“CIVITAI”也有提供线上测试功能,建议可以先试试看是不是你想像中那样,要不然每一个模型文件都非常大,会花很多下载时间,也占用电脑空间。
下载的模型一样放在“ComfyUI_windows_portable\ComfyUI\models\checkpoints”文件夹中,再次打开“ComfyUI”就能使用。
而且不仅有静态模型,还有动态模型,如果你的电脑配置足够强大,尤其是显卡,这些模型足可以玩出各种花样。
关于AI绘画技术储备
学好 AI绘画 不论是就业还是做副业赚钱都不错,但要学会 AI绘画 还是要有一个学习规划。最后大家分享一份全套的 AI绘画 学习资料,给那些想学习 AI绘画 的小伙伴们一点帮助!
👉[[CSDN大礼包:《StableDiffusion安装包&AI绘画入门学习资料》免费分享]](安全链接,放心点击)
对于0基础小白入门:
如果你是零基础小白,想快速入门AI绘画是可以考虑的。
一方面是学习时间相对较短,学习内容更全面更集中。
二方面是可以找到适合自己的学习方案
包括:stable diffusion安装包、stable diffusion0基础入门全套PDF,视频学习教程。带你从零基础系统性的学好AI绘画!
零基础AI绘画学习资源介绍
👉stable diffusion新手0基础入门PDF👈
(全套教程文末领取哈)

👉AI绘画必备工具👈

👉AI绘画基础+速成+进阶使用教程👈
观看零基础学习视频,看视频学习是最快捷也是最有效果的方式,跟着视频中老师的思路,从基础到深入,还是很容易入门的。

温馨提示:篇幅有限,已打包文件夹,获取方式在:文末
👉大厂AIGC实战案例👈
光学理论是没用的,要学会跟着一起敲,要动手实操,才能将自己的所学运用到实际当中去,这时候可以搞点实战案例来学习。

👉12000+AI关键词大合集👈

这份完整版的学习资料已经上传CSDN,朋友们如果需要可以微信扫描下方CSDN官方认证二维码免费领取【保证100%免费】
















 855
855











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









