









最新最强,跟Sora同样DiT架构的StableDiffusion3.0模型开源了,很多人都说意味着AI图像领域的开源战胜闭源,还没用上的朋友,快跟我解锁你的“无限高质量生图”吧!

本篇文档为「视频教程」配套资料,包含详细图文步骤和下载链接,适用于初次上手SD的小伙伴。建议先看一遍「视频教程」,了解流程后再照着文档操作,非常容易上手!
「视频教程」在我视频号最新一期~
网络有问题✈️的朋友,文档最后有我打包好的“汉化ComfyUI+SD3.0模型”网盘链接,可以一键下载~
第一步 下载模型
-
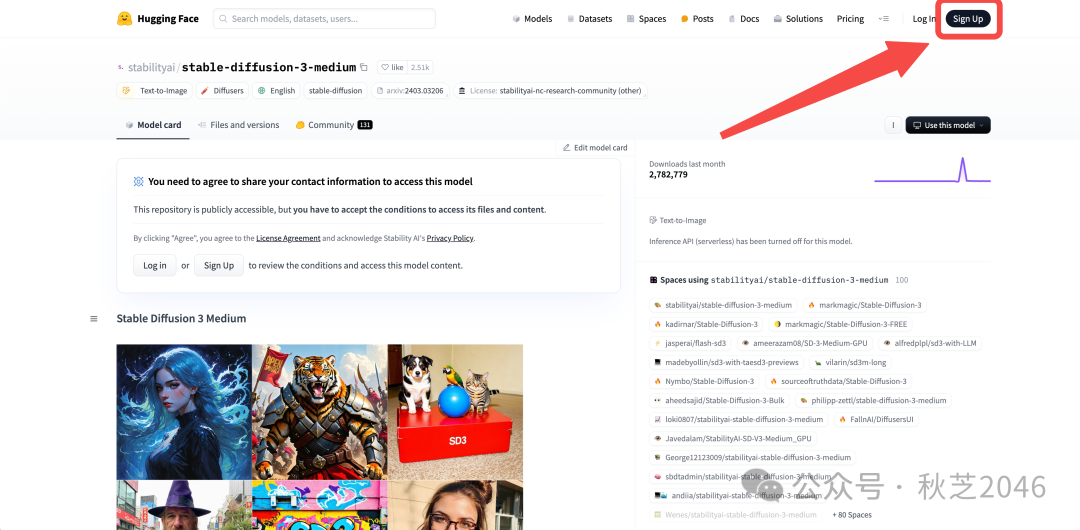
打开Hugging Face官网Stable Diffusion 3.0模型下载地址:https://huggingface.co/stabilityai/stable-diffusion-3-medium
-
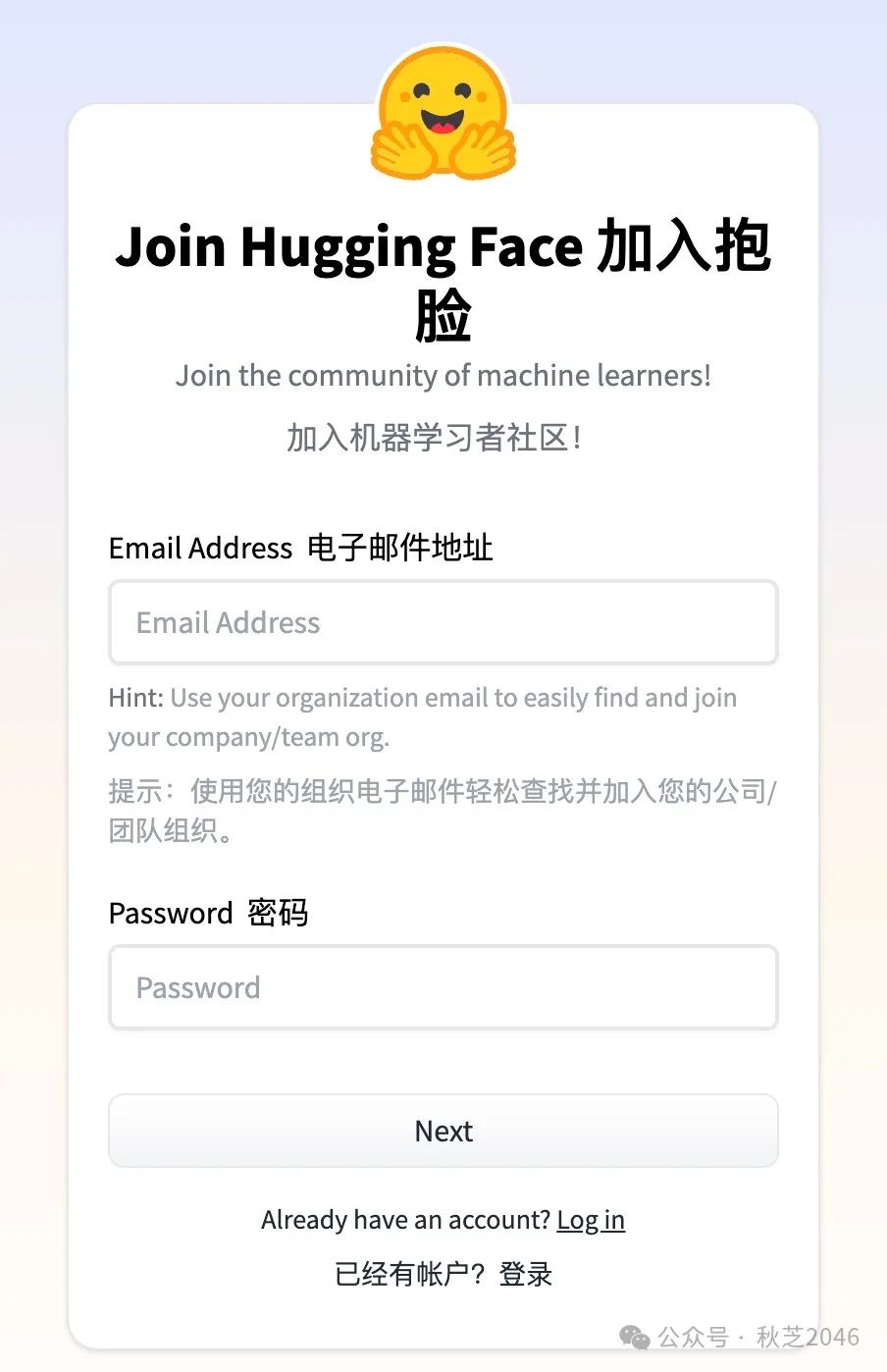
点右上角的“Sign up”进入注册界面,填写邮箱地址免费注册。
-
-
回到第1步打开的SD3.0下载地址,点选“Files and versions”,
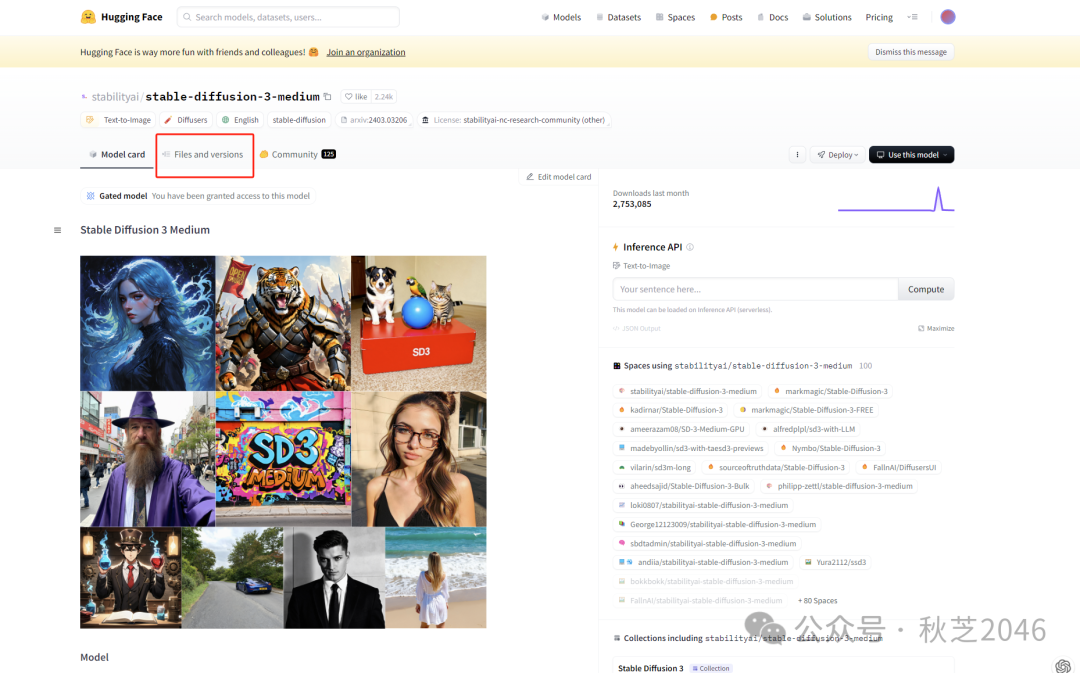
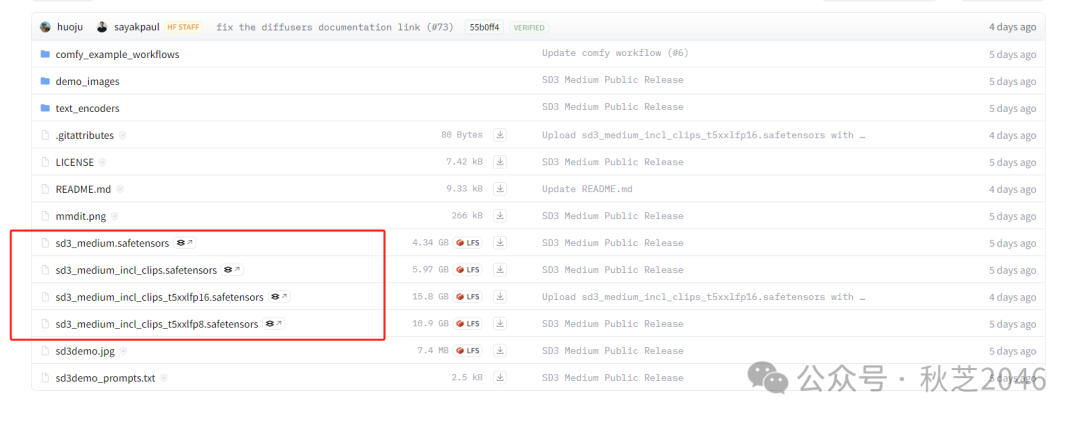
下方表格中“sd3_medium”开头的文件就是SD3的模型啦。
-
第一个“sd3_medium.safetensors”就是SD3.0 medium版本的基础模型。(据说之后还会开源更大的large 和x large版本,不过这个中杯已经很不错了。)
-
- 后面带“incl_clips”字段的是包含它的预训练的模型,下面两个t5xxfp16/fp8是两个预训练版本,效果上16比8有更高的精度。
-
选择适合你的模型下载:
-
- 需要高精度图片的选择fp16版本
- 用笔记本或者显卡一般的朋友选fp8版本就够用啦
- 如果没有独立显卡,就选择第一个基础版本,可以用cpu来解码
-
点击你选择的模型文件,跳转之后点击download下载按钮。
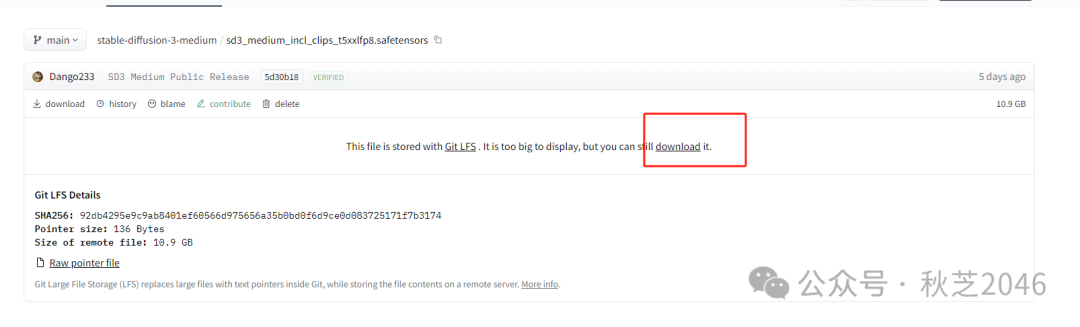
- 模型下载位置随意就好,后面会把它移动到正确位置的。
提示:模型文件尺寸较大,注意磁盘空间噢!
第二步 安装ComfyUI
模型下载好之后我们需要再下载一个用来操作它的用户界面,也就是著名的comfyui,这是一个专门为sd设计的节点式用户操作界面。
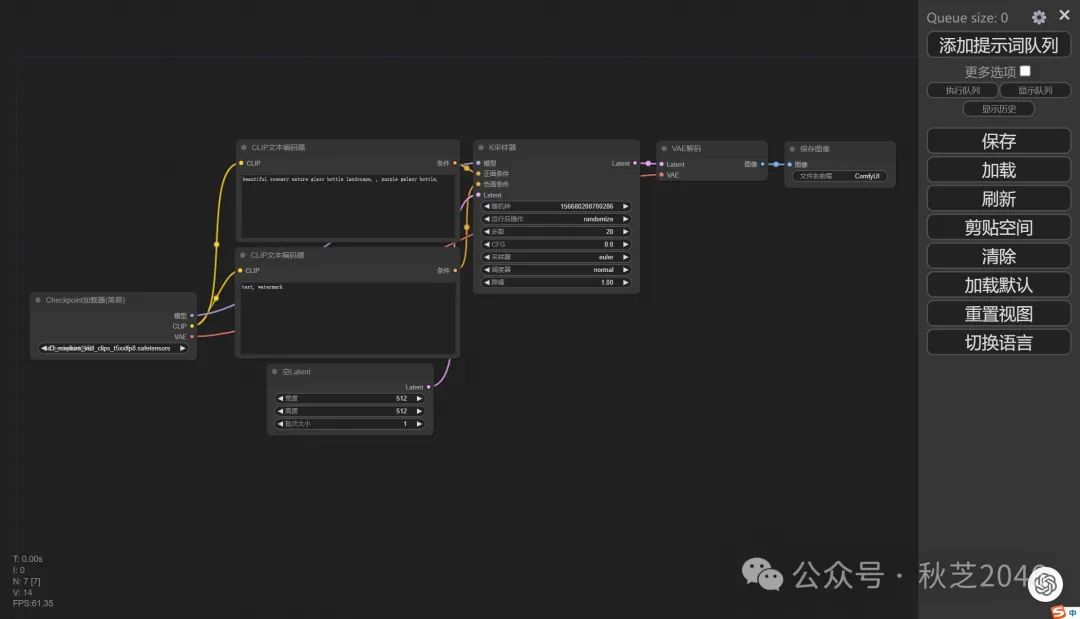
不要被看似复杂的界面吓退,实际上节点就是一个一个的运算步骤,每个步骤可以用连线自由连接出你想要的运行路径。不用担心,我们等下就来了解基础用法,实在是很简单!
- 打开Github官网ComfyUI下载地址:https://github.com/comfyanonymous/ComfyUI
- 下拉页面,找到“Readme”(有兴趣的小伙伴可以阅读一下,这是开源大佬们为了让你更好抄更好使用而写的说明。看不懂的话没关系,继续往下翻~)
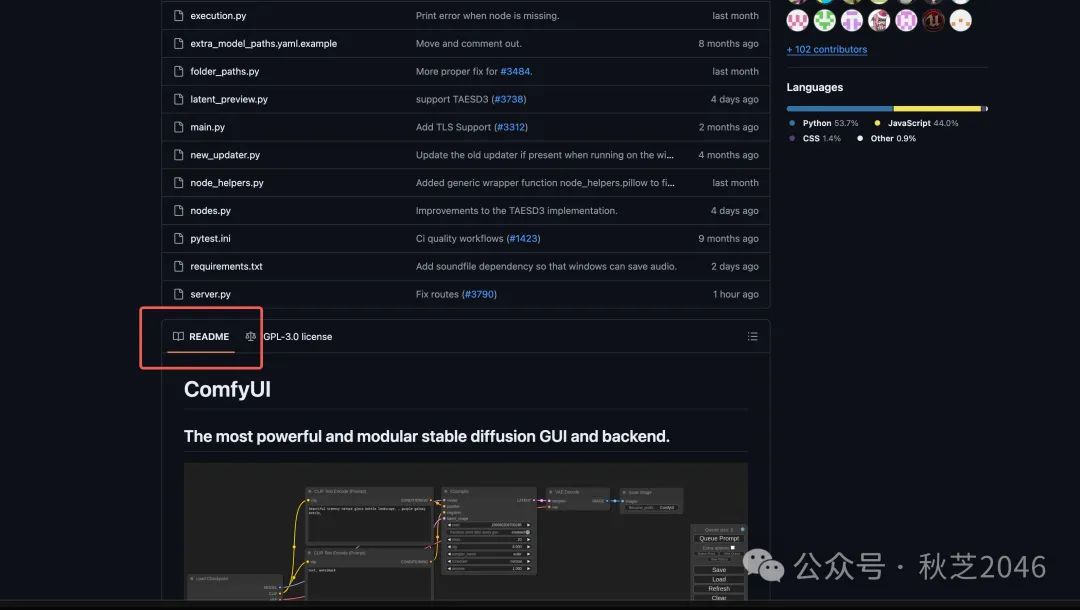
在下方找到“windows”标题,点击下面的“releases page”选项。
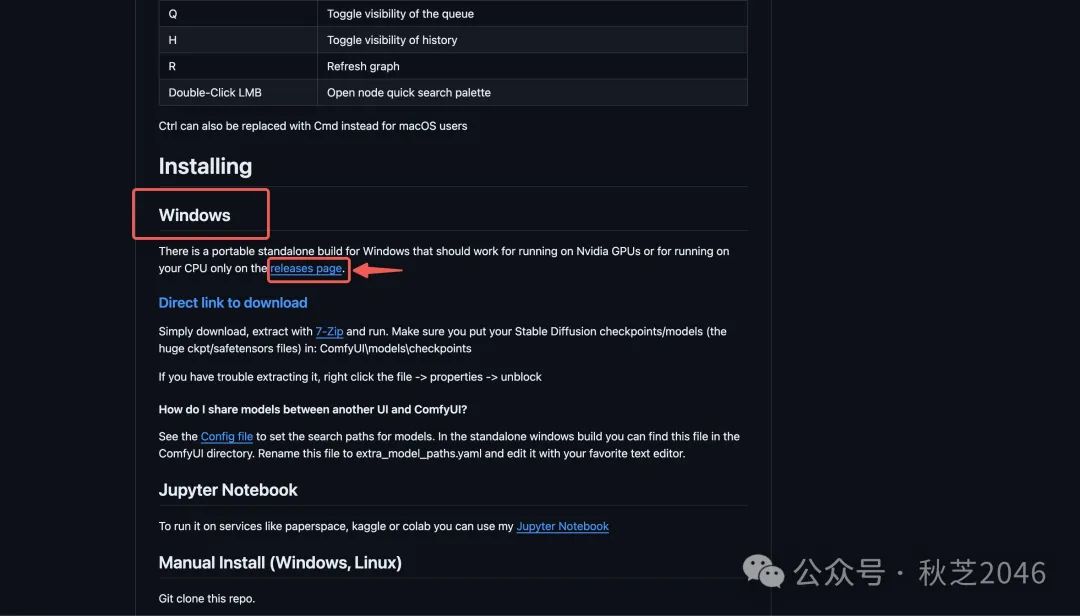
- 跳转到下载页面,点击下载这个稳定版本。
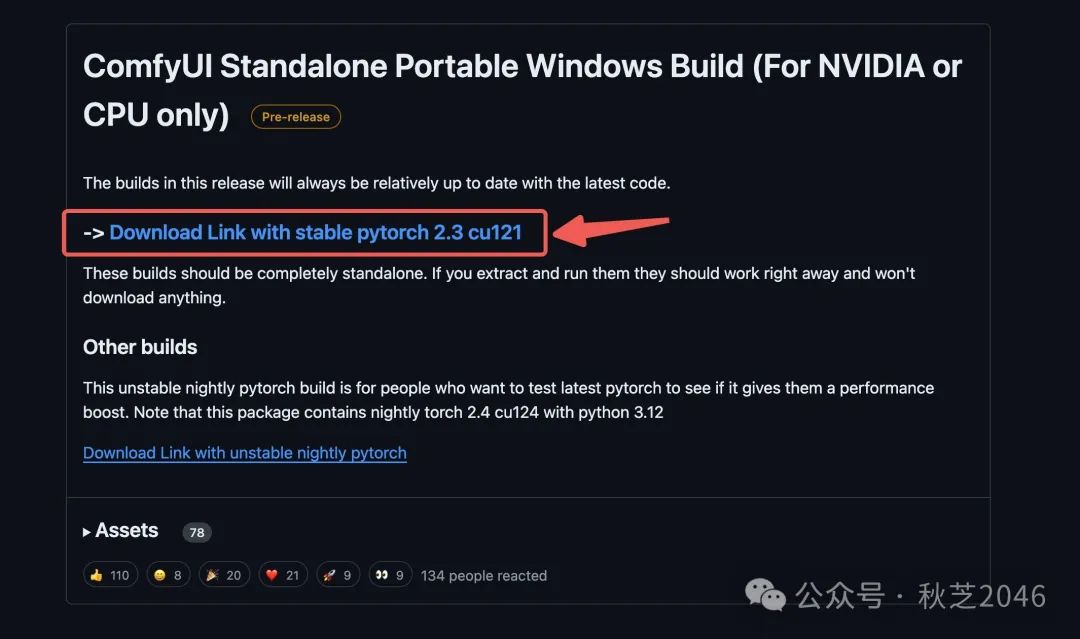
- 将下载好压缩包解压,然后进入根目录。
-
这两个就是运行comfyui的批处理文件,根据你的电脑选择合适的双击打开:
-
- 没有独立显卡就选择“run_cpu”
- 有独立显卡的选择“run_nvidia_gpu”
如果不知道自己电脑有没有独立显卡的话,可以在群里询问,我看到会尽快回复~还有热心群友也可以帮助你~
第三步 界面汉化
(英语课代表或者想练习英文的小伙伴可以跳过)
- 打开GitHub社区ComfyUI语言汉化包下载地址:https://github.com/AIGODLIKE/AIGODLIKE-ComfyUI-Translation
- 点击展开右上角“Code”选项,点选“Download ZIP”
- 将下载好的压缩包解压,然后将里面唯一的文件夹拷贝到ComfyUI根目录下的“ComfyUI>custom node”文件夹。
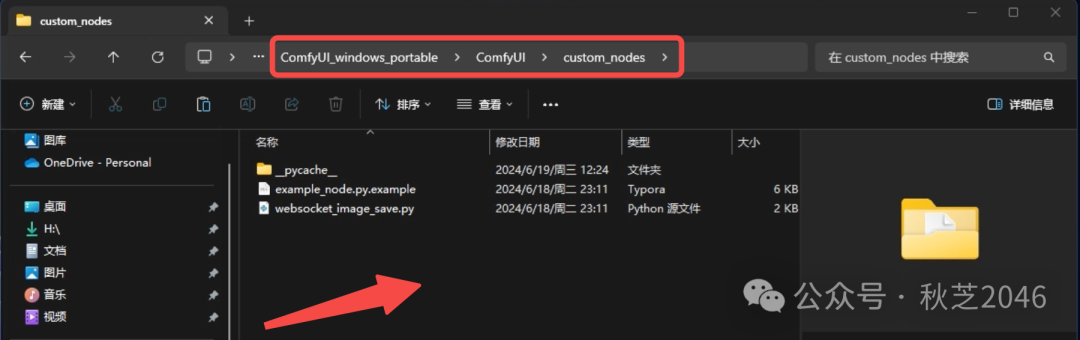
- 重启ComfyUI(关掉浏览器 + 终端,重新进comfyui根目录点“run_nvidia_gpu”或者“run_cpu”)
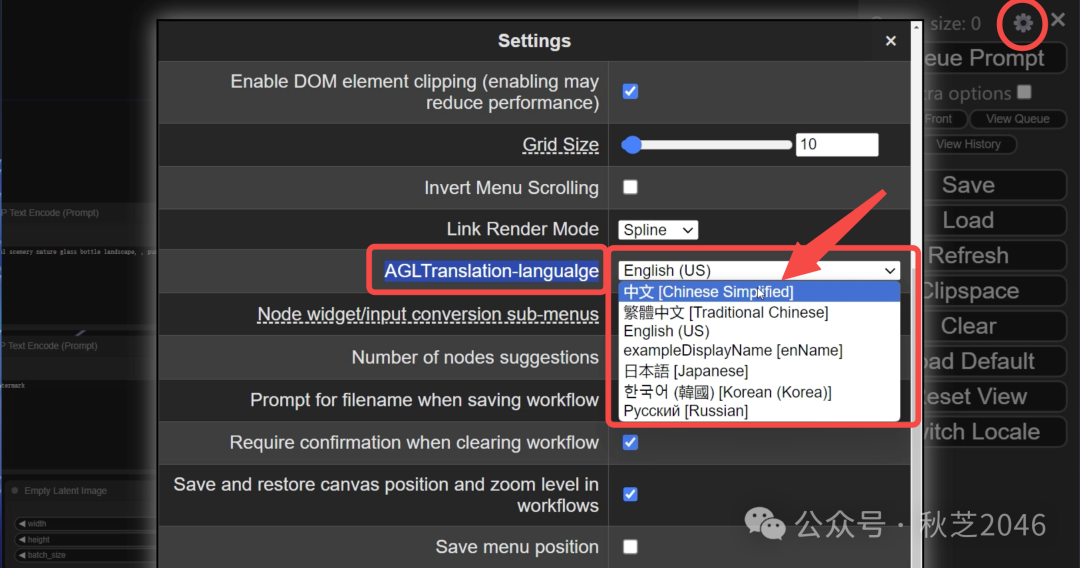
- 打开ComfyUI设置界面(右上角齿轮图标),在AGLT Translation-language选项后面选择“中文”。
第四步 加载模型
- 打开ComfyUI的根目录,点击comfyui,找到里面的models文件夹。
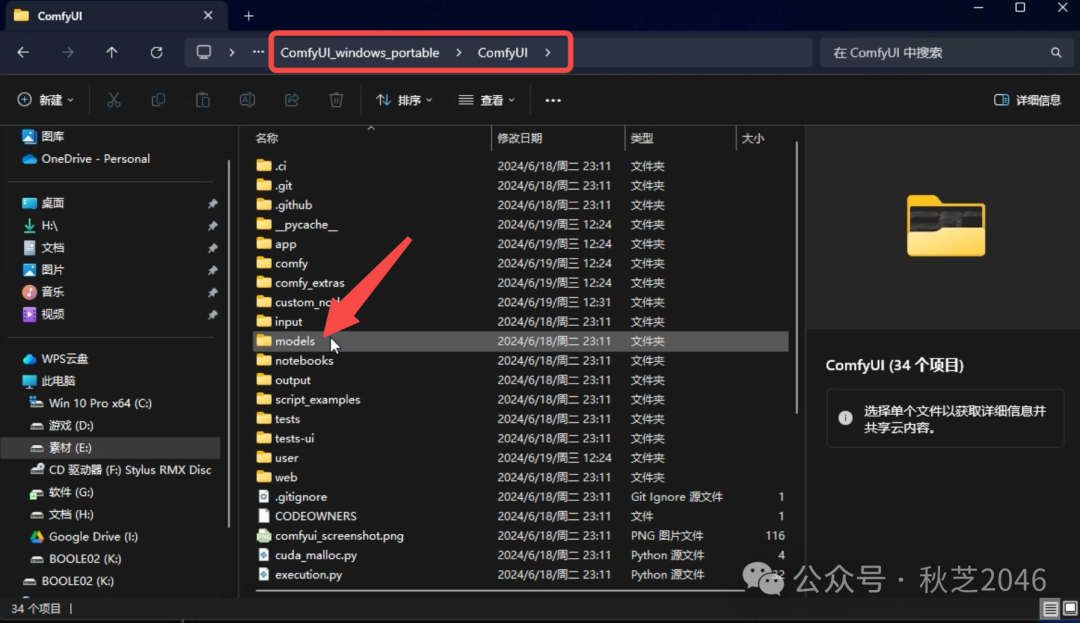
【拓展知识】models文件夹里的各个文件夹,是用来对不同模型分类存放的,我们刚下载的SD3.0 medium的分类叫做checkpoint,就是基于基础模型的微调版本。AI生图都最少需要一个checkpoint来主要生成,其他比如lora、controlnet、embeddings等类别的模型,都是在checkpoint的基础上附加效果。例如比较常见的人物lora就是可以让你生成的人物都长一个样子。
- 将下载好的SD3.0模型文件,拖到models文件夹下的checkpoint文件夹中。
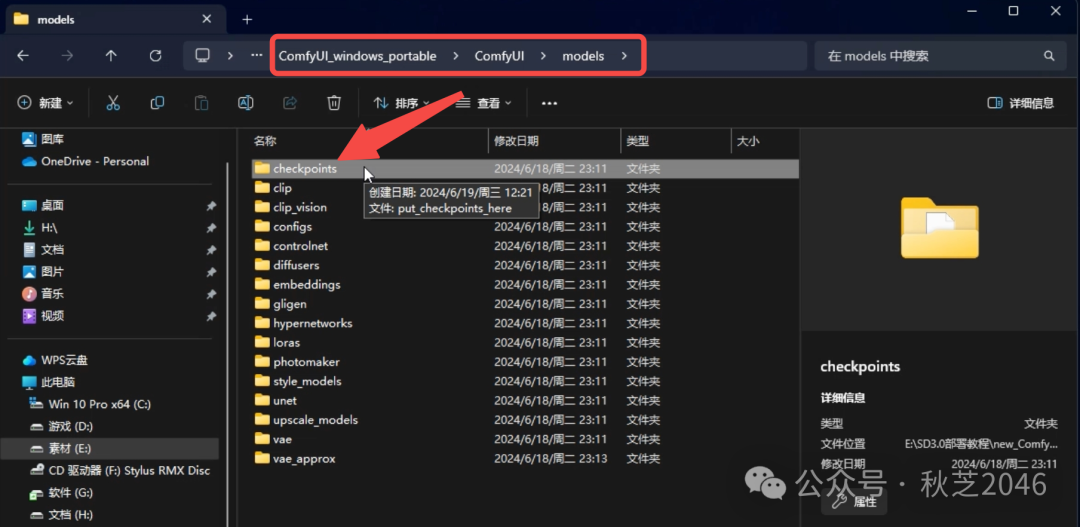
- 刷新ComfyUI,然后在最左侧的模型加载器节点中就可以选择到SD3.0模型了。
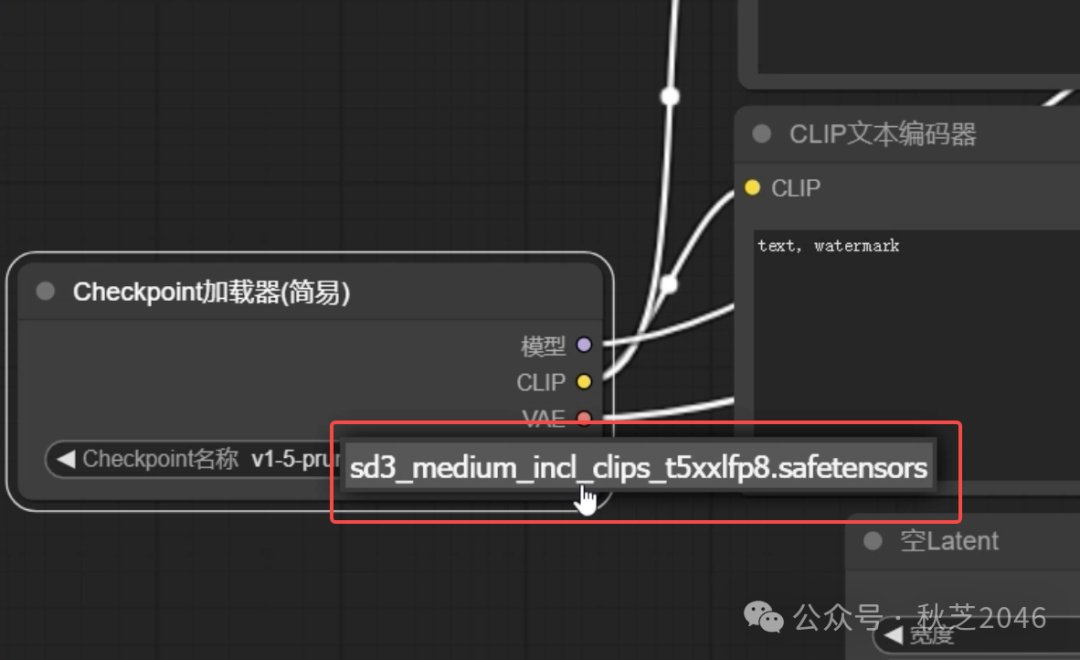
第五步 ComfyUI基础使用方法
1 节点简介
默认提供的这个节点流程,就可以满足基础的图片生成了。我们把这组节点分为五个部分进行介绍。
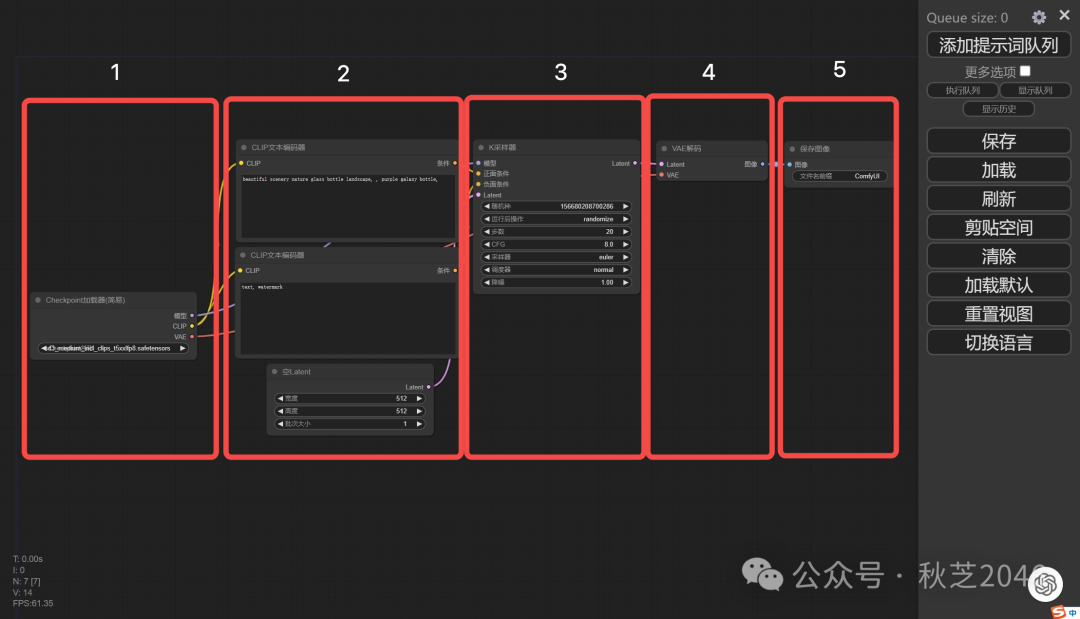
第1部分
这个节点是模型加载器,负责加载你要用来生成图片的模型,以后下载了各种模型都可以在这里选择和切换。
第2部分
这一列是我们会最常用的区域,用于控制AI生成时候的约束条件。三个节点从上到下分别是:
- 正向提示词,也就是想要生成的内容,比如“one girl,sunshine”;
- 反向提示词,填写不希望出现的内容元素,一般用于避免水印和畸形等;
- 空的潜空间图像,因为stablediffusion是在一个潜在的空间中不停的去噪(其实潜在空间就是不存在的空间,是一个以数字表示的空间),最后得出我们要的图片。这里的前两项设置潜空间图片的大小,也是在控制我们最后输出的图像要多大分辨率尺寸。最后一项批次大小,即一次生成多少张图。
提示:注意,即便界面汉化了,但生图的提示词都还是要翻译英文进行填写!
第3部分
K采样器节点。在SD中采样的过程也就是生成的过程,所以这个节点中其实就是控制一些生成参数。刚刚入门的小伙伴先保持默认即可,之后可以挨个调整参数,逐渐摸索他们的效果。也可以期待我后续的进阶教程~
这里先大致介绍一下里面各项参数的含义,之后我会继续做教程介绍生图过程中这些参数的具体作用:
- 随机种:种子值用于初始化生成过程中的随机数。相同的种子值和其他参数设置将生成相同的图像。不同的种子值会生成不同的图像。这对于生成具有一致性的图像或对比不同设置的效果非常有用。
- 运行后操作:这里是设定种子的生成方式,random(随机)就是随机生成,每张图会重新随机生成一个种子;increment(增加)就是种子数字每一次生成增加1;decrement(减少)就是每次生成后种子减1;fixed(固定)就是固定种子的数字,在提示词不变的情况下,固定种子会生成比较一致的图像。
- 步数:采样步骤数决定了生成图像的迭代次数。更多的步数通常会提高图像质量,但会增加生成时间。步数的选择需要在质量和生成速度之间找到平衡,太低会导致图片模糊,过高也可能出现“鬼图”。
- CFG:这是一种调节图像生成过程中的控制参数,用于平衡生成模型的创造性和保真度。较高的CFG值会使生成图像更贴近输入提示,但过高可能会导致图像不自然。较低的CFG值则可能导致图像更具创造性但可能与提示无关。
- 采样器:采样器类型决定了使用的采样算法,如DDIM、PLMS、Euler等。每种采样器有不同的生成图像的特性,一些采样器可能更快,而另一些则可能生成质量更高的图像。
- 调度器:调度器控制采样过程中噪声的衰减和添加方式。不同的调度器可能会影响图像的细节、平滑度和收敛速度。常见的调度器类型包括线性调度、余弦调度等。
- 降噪:这个参数控制在生成过程中应用的降噪强度。较高的降噪强度可能会使图像更平滑,但也可能导致细节丢失。较低的降噪强度则可能保留更多细节但增加噪点。
第4部分
VAE解码器,它负责把潜空间中去噪完成的图像,从数字表示转换到真实的像素空间,解码成我们能看得见的图像。
第5部分
保存和预览图片的节点。不用解释了吧~
2 基础使用方法
了解了这些节点的功能后,我们可以看到节点之间用彩色的线连接起来,代表着数据运算的走向。在每个节点中,数据都是从左到右流动的。所以我们也按照从左到右的顺序挨个进行调整。
算的走向。在每个节点中,数据都是从左到右流动的。所以我们也按照从左到右的顺序挨个进行调整。
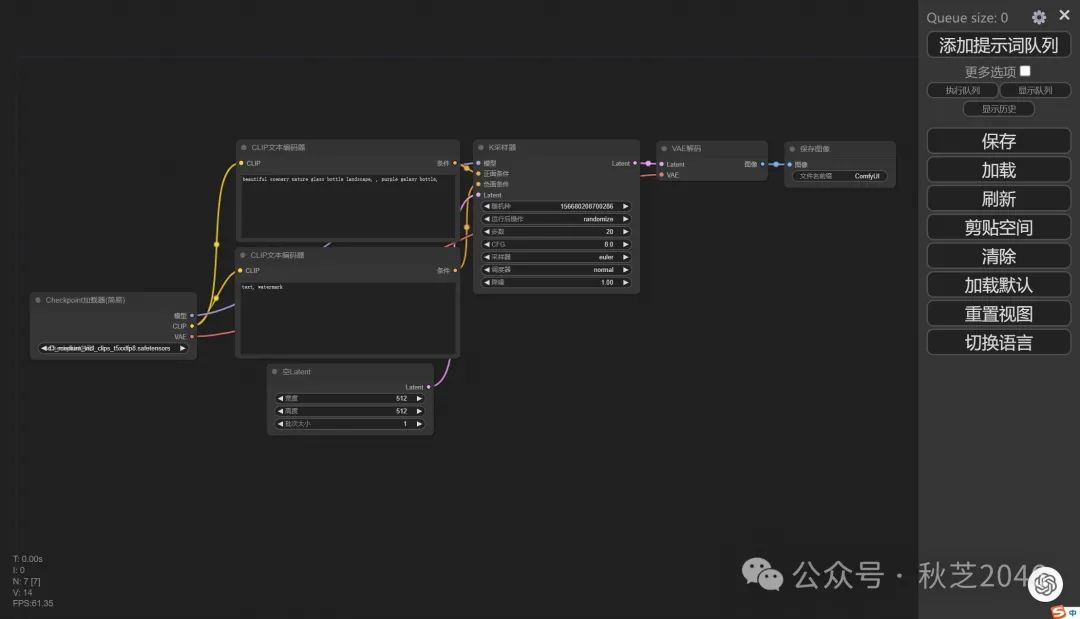
在模型加载器中选择刚才安装好的SD3.0模型
填写正向提示词、反向提示词(⚠️注意用英语!)
在潜空间图像控制节点选定希望生成的图像尺寸,以及希望同时生成几张图片。(建议第一次生成就用默认的512*512尺寸,批次大小不要超过4)
(新玩家可以跳过)调整采样器参数。
点击右上角的“添加提示词队列”
等待生成。
生成过程中运行到的节点会有绿色高亮表示。
默认参数下的生成时间根据电脑性能不同,大概从几十秒到几分钟不等。
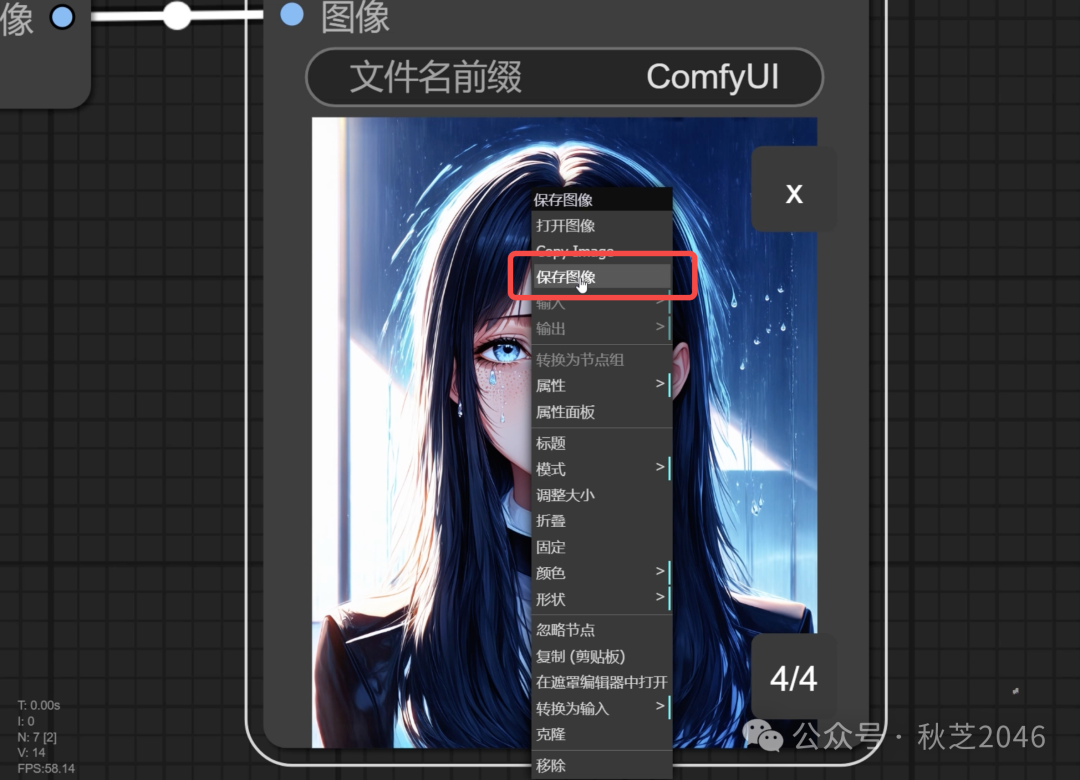
图像生成完成后,就会出现在保存图像节点下。可以点击预览,对于满意的图片可以右键选择“保存图像”存储
调整过布局和参数的工作流可以在界面右侧选择“保存”,存储到自己习惯的位置。下次直接把保存好的“.json”文件拖进ComfyUI界面,就可以调用之前的工作流啦。
以上就是本篇教程的全部内容啦,希望大家踊跃的尝试起来 ~入门AI应用真的没有那么难~
如果你还是觉得太麻烦了,那也可以到Liblib云端体验一下SD3.0,有免费的额度!
模型体验地址:https://www.liblib.art/sd
- 最近很多催更我都有收到!只不过最近忙于搬家,更新比较慢还请大家多多谅解~大量干货内容正在马不停蹄的赶来途中!
- 一直有很多小伙伴来问我AI到底该怎么学?提示词、生图、音乐等等那么多应用该从哪儿开始?网上信息太多了该怎么分辨?我也很想为大家解答,但是碍于做视频产量实在太低了,根本说不过来!
- 所以悄悄透露,我正在筹备一个超干货的AI知识社区,方便小伙伴们快速入门AI应用,掌握实用AI技巧,了解前沿科技资讯。我也会在社区里持续为大家答疑解惑,敬请期待吧!~
关于AI绘画技术储备
学好 AI绘画 不论是就业还是做副业赚钱都不错,但要学会 AI绘画 还是要有一个学习规划。最后大家分享一份全套的 AI绘画 学习资料,给那些想学习 AI绘画 的小伙伴们一点帮助!
👉[[CSDN大礼包:《StableDiffusion安装包&AI绘画入门学习资料》免费分享]](安全链接,放心点击)
对于0基础小白入门:
如果你是零基础小白,想快速入门AI绘画是可以考虑的。
一方面是学习时间相对较短,学习内容更全面更集中。
二方面是可以找到适合自己的学习方案
包括:stable diffusion安装包、stable diffusion0基础入门全套PDF,视频学习教程。带你从零基础系统性的学好AI绘画!
1.stable diffusion安装包 (全套教程文末领取哈)
随着技术的迭代,目前 Stable Diffusion 已经能够生成非常艺术化的图片了,完全有赶超人类的架势,已经有不少工作被这类服务替代,比如制作一个 logo 图片,画一张虚拟老婆照片,画质堪比相机。
最新 Stable Diffusion 除了有win多个版本,就算说底端的显卡也能玩了哦!此外还带来了Mac版本,仅支持macOS 12.3或更高版本。

2.stable diffusion视频合集
我们在学习的时候,往往书籍源码难以理解,阅读困难,这时候视频教程教程是就很适合了,生动形象加上案例实战,一步步带你入坑stable diffusion,科学有趣才能更方便的学习下去。

3.stable diffusion模型下载
stable diffusion往往一开始使用时图片等无法达到理想的生成效果,这时则需要通过使用大量训练数据,调整模型的超参数(如学习率、训练轮数、模型大小等),可以使得模型更好地适应数据集,并生成更加真实、准确、高质量的图像。

4.stable diffusion提示词
提示词是构建由文本到图像模型解释和理解的单词的过程。可以把它理解为你告诉 AI 模型要画什么而需要说的语言,整个SD学习过程中都离不开这本提示词手册。

5.SD从0到落地实战演练

如果你能在15天内完成所有的任务,那你堪称天才。然而,如果你能完成 60-70% 的内容,你就已经开始具备成为一名SD大神的正确特征了。
这份完整版的学习资料已经上传CSDN,朋友们如果需要可以微信扫描下方CSDN官方认证二维码免费领取【保证100%免费】
















 3521
3521

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









