









写在前面
本篇文章仅整理归纳 LoRA 训练思路及步骤,以及遇到的问题和解决方案的整理。希望对新手炼丹师们有所启发和帮助

● LoRA是什么
LoRA 是 Low-Rank Adaptation 的缩写,最早在2021年论文《LoRA:Low-Rank Adaptation of Large Language Models》中提出。是一种大语言模型低秩适配器,简单来说就是它可以降低模型可训练参数,使其尽量不损失模型表现的大模型微调方法。
在此之前,StableDiffusion 只能通过使用 Dreambooth 的方法训练大模型,如果对大模型的效果不满意,那么就只能从头开始,重新训练,但是大模型的训练要求高,算力要求大,速度慢。自从 LoRA 被引入 StableDiffusion 后,大大降低了训练门槛,并扩宽了产出模型的适用范围。这就使得我们这些对 AI 绘画感兴趣的非专业人员,也可以在家用电脑上尝试训练自己的 LoRA 模型。
LoRA 的出图原理和理论知识在网上已经有很多,在此不做赘述,感兴趣的小伙伴可自行查找。
● LoRA 训练前的准备
LoRA 训练对显卡有一定要求,同时需要安装一些方便训练的软件。
首先,对电脑配置的要求主要来自显卡,需要显卡有足够的显存,其他配置不太差就可以。显卡的选择中显存是第一要素,SD1.5 版本的底模 6G 显存勉强可用,8G 显存就可以比较流畅的生成图片和炼制 LoRA,12G 可以流畅的使用 Preambooth 微调大模型。
然后,就是推荐下载几个后续方便训练的软件,帮助新手小白降低训练难度,提升炼丹效率。
还有其他一些 LoRA 训练丹炉,感兴趣的小伙伴也可以自行下载试用。
● LoRA 训练具体步骤
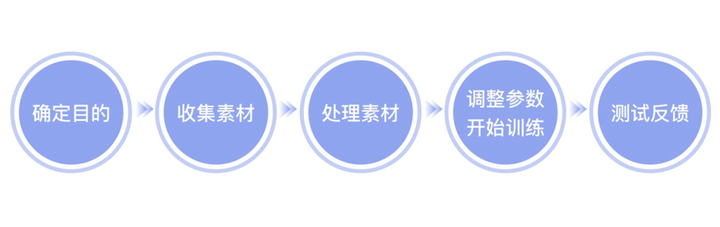
1.确定目的
在训练 LoRA 模型之前,我们需要首先明确自己需要训练什么类型的 LoRA,模型大致分成了几个大类:人物角色、画风/风格、概念、服饰、物体/特定元素等。
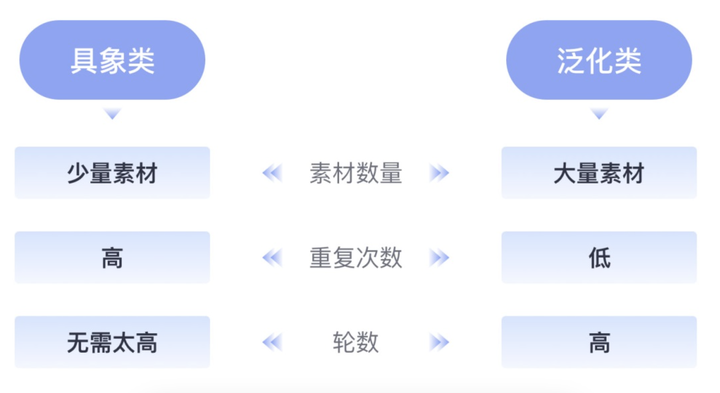
我只简单的划分为两类:具象类和泛化类,具象类如:一个物体、一种姿势、一种服装、一个人物、某个特定元素等都可以划归为具象类。泛化类如:某种场景、某种艺术风格、色彩风格等。

前期明确目的的训练能更好的确定要找素材的数量及选择的大模型类型,为后面的具体训练打好基础。
2.收集素材
注意:[大模型的选择] 和 [图片质量] 都是收集素材的关键!
收集素材阶段,我们仍然按照第一步中的训练目的,分为具象类和泛化类。
具象类 LORA:
数量:在具象训练中并不是素材越多越好,一般建议 20 张左右即可 素材要求: 不同角度,不同背景,不同姿势,不同服饰,清晰无遮挡的图片 注意:如果同质化的素材太多,容易造成权重的偏移
泛化类 LORA:
数量:在泛化类训练中需要素材多一些,建议 50 张以上
注意:这种情况不需要特别在意同质化,但也切勿非常接近的素材占比过高
质量:代表画面的品质,如1girl 结合 high quality 使用来获得高质量图像。
主体:画面主要内容,这是任何提示的基本组成部分
代表动作/场景:描述了主体在哪里做了什么。
风格:画面风格(可选)
细节补充:可以使用 艺术家,工作室,摄影术语,角色名字,风格,特效等等
3.处理素材
从这一步起,我们会使用到上文提到的软件。处理素材主要包括统一素材尺寸、生成标签和优化标签

a、统一素材尺寸
可以使用修改图片工具对图片尺寸进行批量处理,至少保证一边为 512px,但必须是 64 的倍数。横竖图可放一起训练。也可以使用美图秀秀或者PS自行裁剪

b、生成标签
我使用的是秋叶大佬提供的 StableDiffusionWebUI,启动SD-训练-图像预处理。
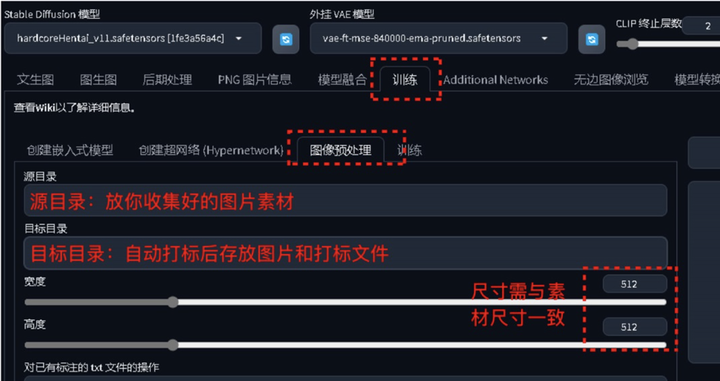
在你的随便一个盘,建2个文件夹,我简单的命名为1和2 (1文件夹放你收集好的图片素材即为「源目录」 。2文件夹不需要管,等到SD自动打标完,会将打标文件和你的图片自动存放在2文件夹内即为 「目标目录」),调整宽度和高度与你的素材尺寸保持一致
复制文件夹1和2的地址,分别粘贴到源目录和目标目录的位置。
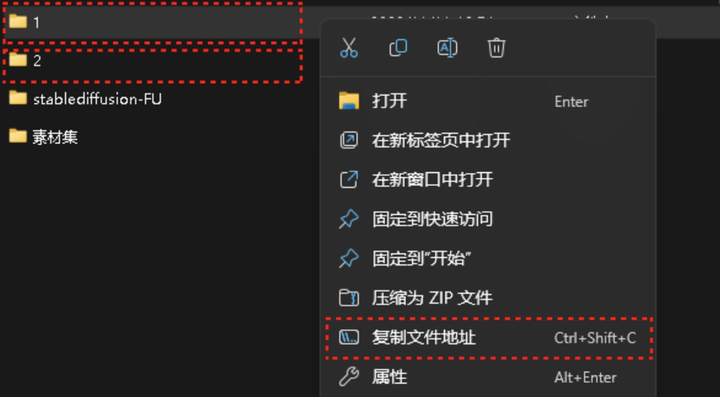
有两种生成标签的方式: BLIP 即自然语言标签,比如“1个女孩在草地上开心的跳舞”, Deepbooru 即词组标签 (常用) ,比如“1个女孩,草地,跳舞,大笑”。一般选择使用 Deepbooru生成标签
当 SD 界面右侧出现 Preprocessing fnished,就表示SD已经帮你自动打标好了。
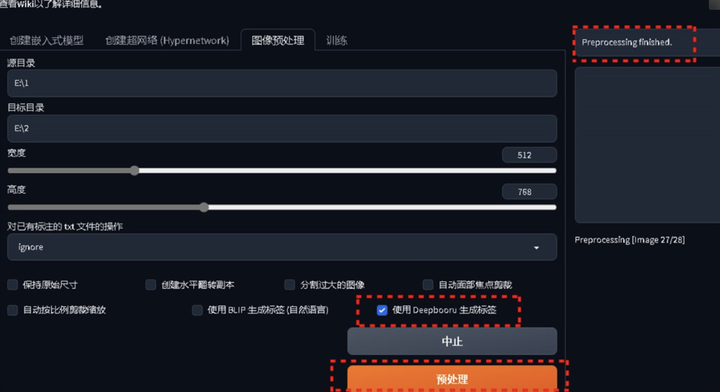
注意
「源目录」和「目标目录」复制的文件地址一定不要带引号,不然后面会报错!!

打开刚才建的2文件夹,就可以看到图片和自动生成的标签了。txt文本中的就是SD自动打好的标签。
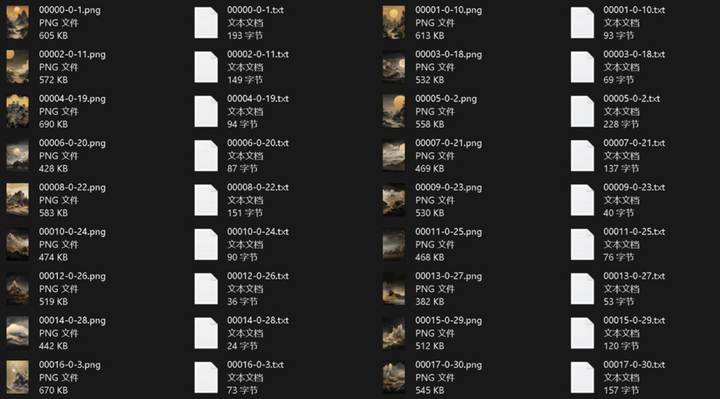
C、优化标签
第一次训练时我没有优化标签直接训练 LORA,最后的 LORA 效果不是很理想,第二遍训练又新增了素材数量,同时优化了标签。
优化标签一般有两种方式: 1) 保留全部,不做删减,用此方法比较方便,但是需要用精准的关键词,才能还原想要的效果;2) 删除部分特征标签,我使用的是此方法,
批量修改关键词的工具 BooruDatasetTagManager,很多大佬推荐过,界面比较原始,好用的点是可以批量增删改查关键词,并且可以通过调整关键词位置来调整权重。当然你也可以使用 VsCode 或者直接用 txt 调整都可以
下载完后,直接双击 exe 文件运行,就会出现此界面。界面分为三个区域,分别是「数据集区域」「图片标签区域」「数据集内所有标签区域」。标签相关的区域右侧都有操作,可以增加、删除,翻译、上下移动标签,常用的就是这几个功能。

选中文件-读取数据集目录可导入数据集;选中界面-翻译标签,可翻译所有标签,标签可拖动上下移动,更改权重,最后全部修改完别忘记保存更改
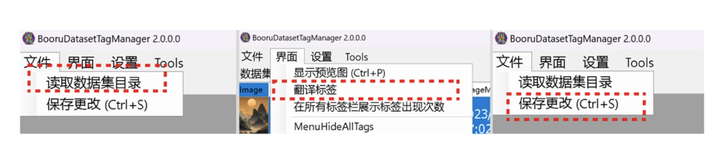
数据集导入后,就可以开始对照图片素材对标签进行删改,需要注意的是标签提示词的前后顺序代表着标签的权重,越靠前的标签权重也就越大,所以我们可以把想要的效果或风格标签放在前面,像背景干净这类标签尽量靠后。
标签优化方法: 删减掉训练风格或者需要生成内容的相关词。比如我要生成 「手绘插画」的 LORA 模型,就需要保留图片素材中手绘插画风格相关的内容作为自带特征,那么就将与手绘插画相关的词语标签删除,增加触发词“shouhui或者chahua”。将“shouhui或者chahua”触发词与其风格相关的词关联,当你填写触发词后就会自带此风格。

4.调整参数/开始训练
至此,准备工作就完成了,可以开始准备正式训练 LORA 了,我使用的还是秋叶大佬的 LORA 训练器 SD-Trainer,选择新手训练模式
添加图片注释,不超过 140 字(可选)
在新手训练开始之前需要先明确几个概念
重复次数 (Repeat) : 每一张素材的重复次数需要在文件夹名以「数字_名称」的方式设定,如训练集 chahua 重复次数 10,则文件夹命名为 10_chahua。
训练轮数 (Epoch) : 整个训练集按照重复次数训练一次为一轮 10 轮就是 10*10 为每一张训练 100 次
在操作过程中也同样要考虑具象类和泛化类不同来调整参数,具象类需要在每一轮提高次数以求精准度,泛化类就降低次数提高轮数,不需要那么精准,一轮轮去训练。新手训练模式下,我们只需要调整这几个参数即可。
进入新手模式后需要选择训练 LORA 使用的大模型
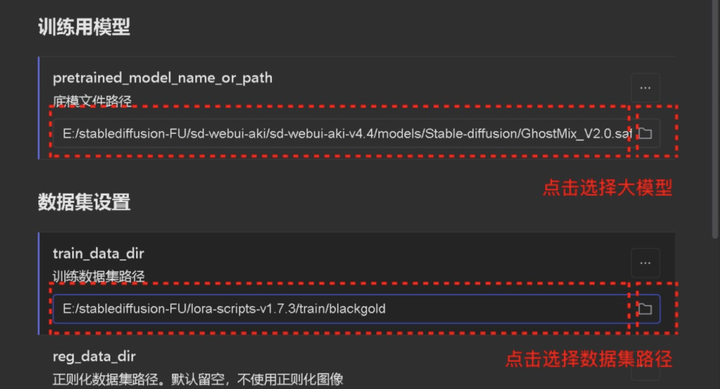
底模文件路径,选择你要训练 LORA 使用的大模型,直接点击右侧的小文件夹选择即可。
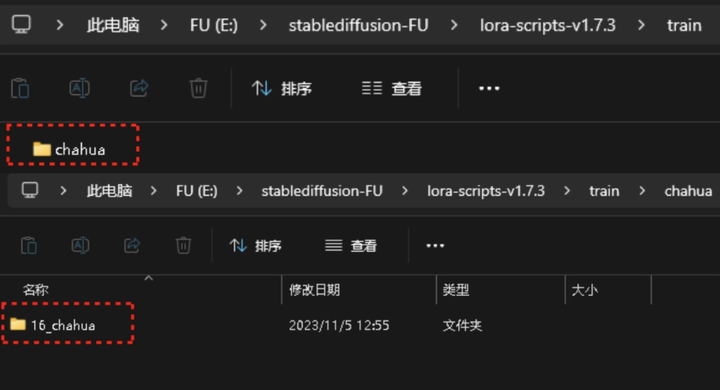
训练数据集路径: 在选择这一步之前,需要现在 sd/lora-scripts-v1.7.3/train 这个文件夹下建一个文件夹,比如我建的叫 “chahua”,再打开 “chahua” 文件夹在里面建一个“数字_英文名”的文件夹,将之前打标好的图和标签一起复制到“数字 英文名”的文件中 (如训练 chahua 重复次数 16,则文件夹命名为 16_chahua)
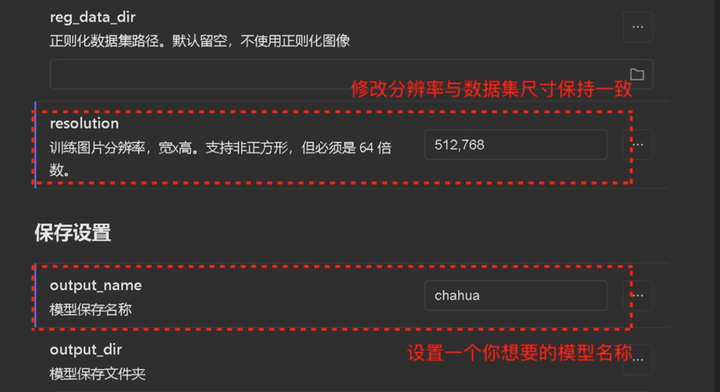
修改分辨率 (之前数据集的尺寸是多少,这里就用多少) 保存设置: 保存模型的名称修改成你想要的名称
点击开始训练,就可以在终端看到它正在疯狂训练中…这个时间会比较久,慢慢等待就好。
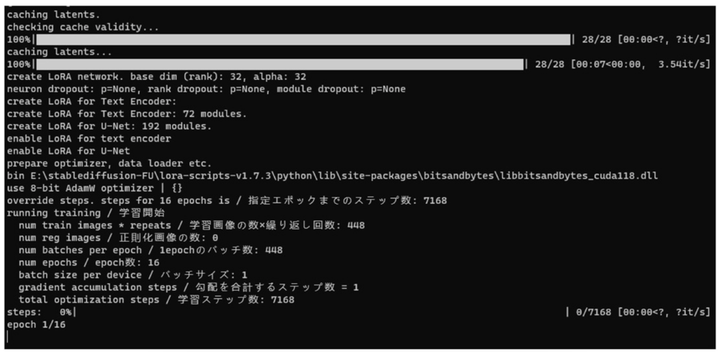
当出现“训练完成”字样后,表明你的 LORA 模型已经初步完成了训练,我是晚上开着电脑自己跑的,用时9小时…初步训练完 LORA 模型,我们就可以对 LORA 进行测试,来验证我们的 LORA 训练成果,以及了解这个 LORA 的最佳参数
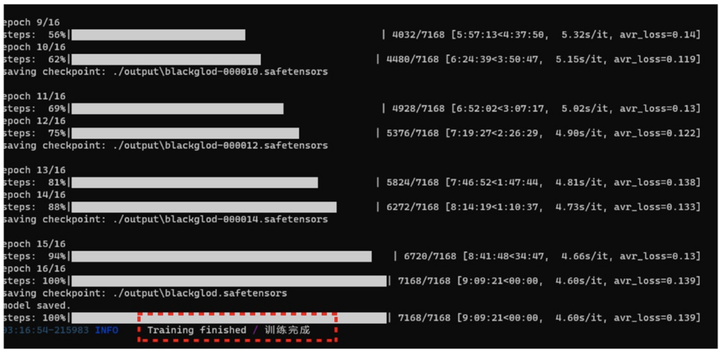
在 sd/lora-scriipts-v1.7.3/output 文件夹中就可以看到我们生成的 LORA 模型了,因为我设置的是 2 步保存一个 Lora 模型,16 步,所以有 8 个 LORA 的阶段稿。(没有数字的这个是最后的 LORA)
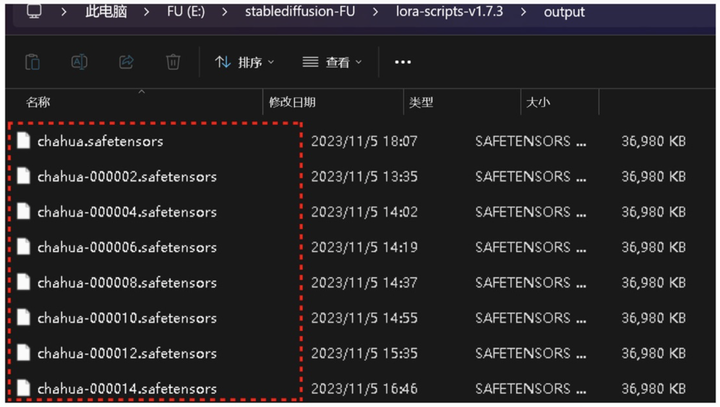
5.测试反馈
通过测试我们可以对比大模型、不同阶段 LORA、迭代步数、采样方法等生图效果,从而帮助我们对比生成的模型,选择更好的 LORA 模型。
a、loss图
每次训练的 loss 图都是独一无二的,loss 曲线只是参考,重点要观察 loss 逐步降低的状态,loss 越低,拟合度就会越高,过低也有可能会过拟合,需要找到合理值,可以通过 loss值来选择几个训练好的 lora 模型进行 xyz 序列图测试,从而选择更好的 Lora 模型
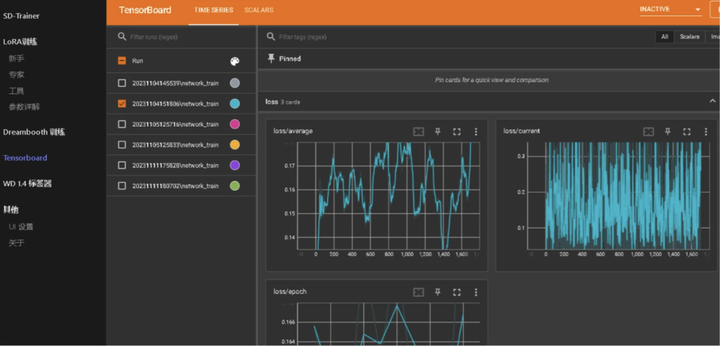
b、xyz序列图
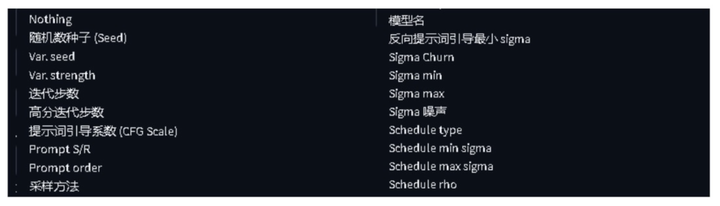
xyz 序列图是一个参考值,能看出不同权重对 LORA 的影响,以及过拟合,欠拟合的程度。需要多生图去测试加深对模型的判断
我是用 xyz 序列图进行反馈: 在使用之前需要先给 Stable-Diffusion 安装一个插件 AdditionalNetworks,这个插件可以帮助我们测试多个 LORA 不同权重的效果。安装成功后,会有图片所示部分。
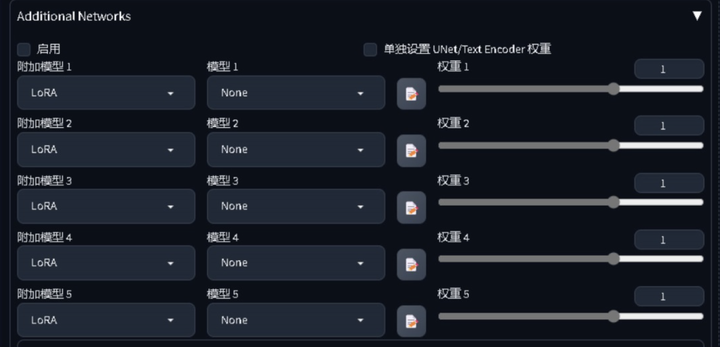
虽然在训练模型前已经选定了大模型,但我还是会根据 LORA 的类型,选择不同的大模型进行跑图测试,选择更多合适的大模型.
在 SD 的脚本中选择“xyz图表”,X轴类型选择“大模型”,选择电脑中有的合适的大模型,点击生成即可。
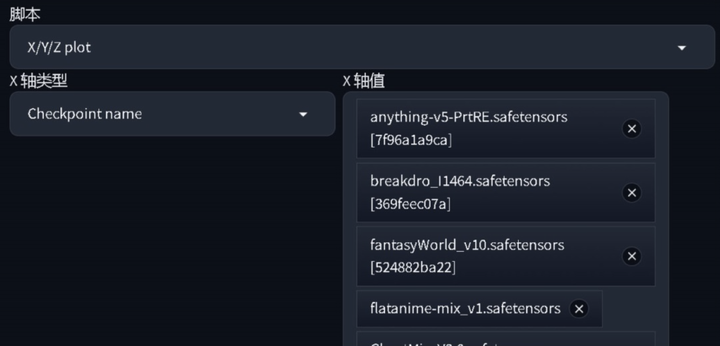

这样就可以横向对比,哪个大模型出图效果更好,更适合此 LORA 选定了大模型后,我们可以测试几个 LORA 在多少权重下生图效果最好。
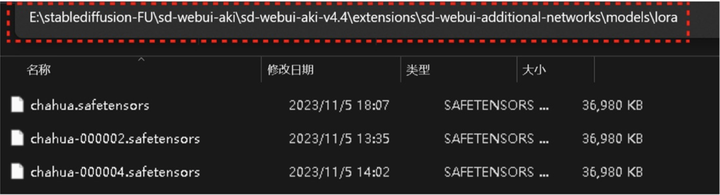
首先需要把已经训练好的 LORA 模型从 output 文件夹 ( sd/lora-scriipts-v1.7.3/output) 复制出来,放到文件夹 (sd-webui-aki/extensions/sd-webui-additionalnetworks/models/lora) 中,刷新后就可以在 SD 中看到你训练的 8 个模型
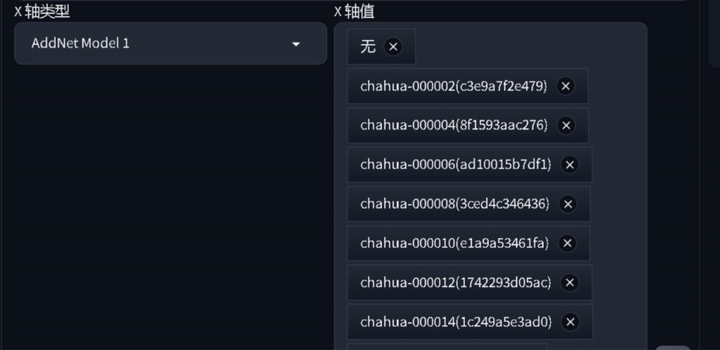
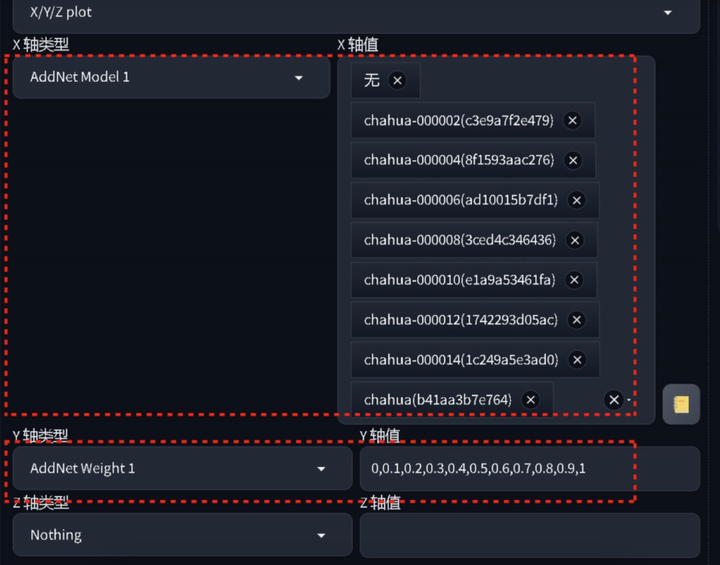
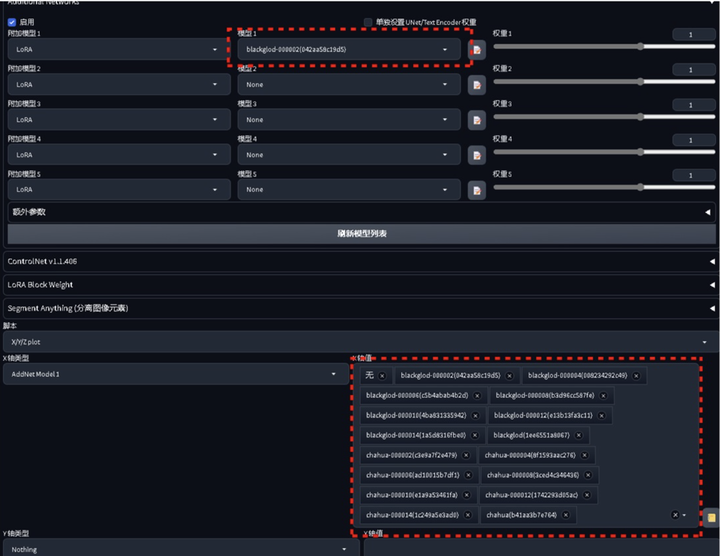
选择xyz图表,X轴类型选择附加模型1,X轴值选择生成的8个LORA模型,Y轴类型选择附加模型权重1,Y轴值可以自行填写,我是按照从0-1的权重进行对比的。
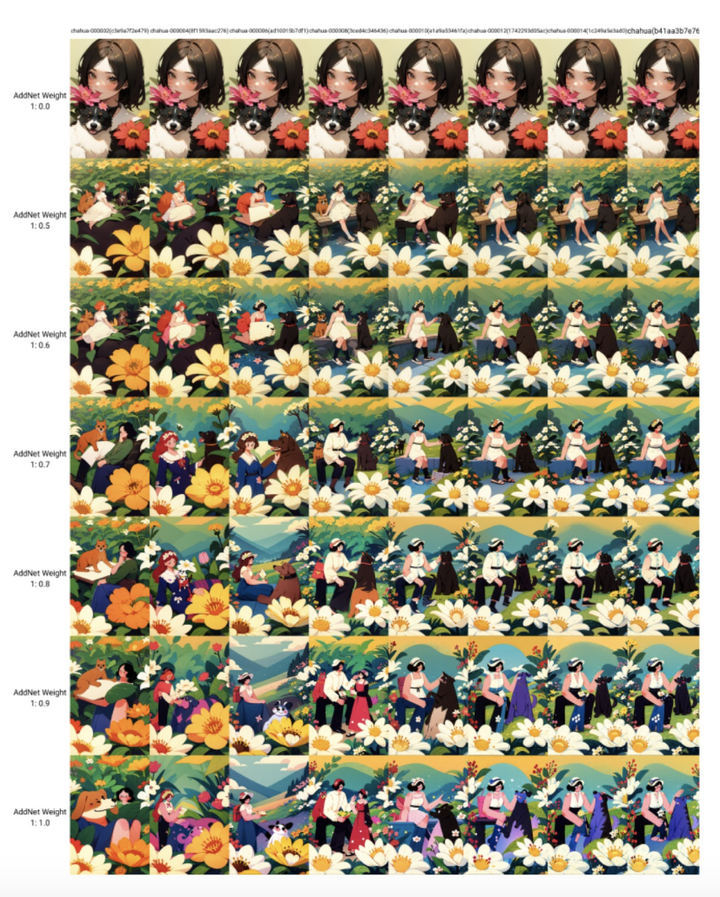
通过生成的xyz测试图,就可以对比看到哪个 LORA 模型在多少权重下生成的效果是最好的。最终就可以选定我们的 LORA 模型终稿
同样的,也可以用此方法来测试不同采样方式哪种效果更好

甚至迭代步数等很多参数都可以通过xyz的对比进行确认,xyz有非常多的参数可以对比,感兴趣的可以自己跑跑试试
至此一整套我自己生成 LORA 的方法已经汇总整理完毕,没有实践之前也感觉困难重重,但是真的做起来,就感觉没有那么难了,再整理成文章,就又感觉更清晰了一些。下面是我在炼丹中遇到的一些问题和我的解决方法
● 问题汇总及解决方案
1.页面文件太小,无法完成操作的报错
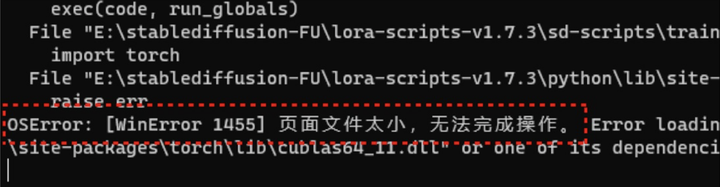
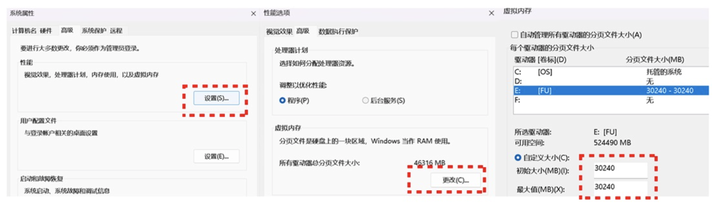
这应该是虚拟内存不足的情况。win电脑设置-系统-系统信息-高级系统设置,系统属性-高级-性能-设置-高级-虚拟内存-更改,增加虚拟内存即可
2.Additionalnetwork 选择模型显示“无”
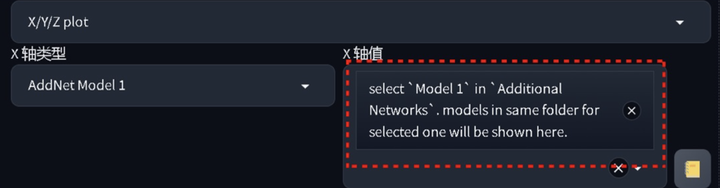
这个问题首先需要看看你的 LORA 模型是不是放在正确的文件夹中,正确的地址应该是 sd-webui-aki/extensions/sd-webui-onalnetworks/models/lora,如果位置正确,仍然报错,可以尝试先在 Additional Networks 中选择一个 LORA,然后在去 xyz 轴中删去不需要的 LORA。
注意:确保所有的名字都不要有中文,包含大模型如果有中文,改成拼音或英文不然会有不知名的报错
● LORA的应用
LORA 现在已经广泛应用于商业场景中,将 IP 形象训练成 LORA 就大大节省了运营去根据不同活动不同场景结合 IP 绘制的时间,在电商领域,可以将衣服训练成 LORA,就不需要请模特,或者拍摄,直接用 AI 生成模特,使用 LORA 给 AI 模特穿上特定的服饰,很多需要真人出镜拍摄的场景,也可以使用 LORA 模型,让一切变的简单可操作
IP 形象 LORA
IP 形象 LORA 的应用可以快速生成符合 IP 形象的设计方案,更灵活的应用在不同的场景中,IP 形象 LORA 将整个设计过程更简化,让设计师能更专注于提升作品的审美价值,提高设计的多样性和丰富性提升设计效率
无论是在线上的运营海报、开屏页、banner 等还是在线下的 KT 版、海报物料等,都可以很好的应用

电商 LORA
通过 LORA 模型训练,可以训练出属于自己的电商 AI 模特,让其穿上指定的服饰,也有很多电商背景 LORA 模型,布局、光影、拍摄都不需要了,大大节省了请模特和拍摄的时间人力物力成本

建筑及空间 LORA
训练室内或建筑风格的 LORA,可以结合 controlnet 一起使用,快速根据客户实际户型结构出效果图,大大提升了效率

LORA 的应用场景还有很多,也有很多未被探索出的使用场景,大家可以多多尝试探索,训练自己专属的 LORA。
● 总结
最后,写了这么多,总结回顾一下 LORA 的训练步骤就这么简单的五步:
1、收集素材 2、秋叶大佬 SDWebUi 打标签 3、BooruDatasetTagManager 改标签 4、秋叶大佬 LORA 训练器训练 LORA 5、测试训练好的 LORA
最后的最后,总结一下炼制 LORA 的几个关键点:
1、素材库非常重要,在我们收集素材的时候就一定要保证素材的高质量高清晰度,这可以使我们的 LORA 训练从源头上保证质量。
2、不要迷信别人给的参数,由于你的素材库、模型训练目的等的不同,不要盲目照抄别人提供的参数,别人的参数仅可作为参考包括我在文章中提到的数据。
3、多测试,多尝试。新手期可以先以成功炼出一个 LORA 为小目标,提升自己的信心,然后就可以多尝试使用专业版,多了解其他参数的含义,尝试具象类和泛化类 LORA 模型训练的不同,说不定会有意想不到的效果。
关于AI绘画技术储备
学好 AI绘画 不论是就业还是做副业赚钱都不错,但要学会 AI绘画 还是要有一个学习规划。最后大家分享一份全套的 AI绘画 学习资料,给那些想学习 AI绘画 的小伙伴们一点帮助!
对于0基础小白入门:
如果你是零基础小白,想快速入门AI绘画是可以考虑的。
一方面是学习时间相对较短,学习内容更全面更集中。
二方面是可以找到适合自己的学习方案
包括:stable diffusion安装包、stable diffusion0基础入门全套PDF,视频学习教程。带你从零基础系统性的学好AI绘画!
需要的可以微信扫描下方CSDN官方认证二维码免费领取【保证100%免费】

1.stable diffusion安装包 (全套教程文末领取哈)
随着技术的迭代,目前 Stable Diffusion 已经能够生成非常艺术化的图片了,完全有赶超人类的架势,已经有不少工作被这类服务替代,比如制作一个 logo 图片,画一张虚拟老婆照片,画质堪比相机。
最新 Stable Diffusion 除了有win多个版本,就算说底端的显卡也能玩了哦!此外还带来了Mac版本,仅支持macOS 12.3或更高版本。

2.stable diffusion视频合集
我们在学习的时候,往往书籍难以理解,阅读困难,这时候视频教程教程是就很适合了,生动形象加上案例实战,一步步带你入门stable diffusion,科学有趣才能更方便的学习下去。

3.stable diffusion模型下载
stable diffusion往往一开始使用时图片等无法达到理想的生成效果,这时则需要通过使用大量训练数据,调整模型的超参数(如学习率、训练轮数、模型大小等),可以使得模型更好地适应数据集,并生成更加真实、准确、高质量的图像。

4.stable diffusion提示词
提示词是构建由文本到图像模型解释和理解的单词的过程。可以把它理解为你告诉 AI 模型要画什么而需要说的语言,整个SD学习过程中都离不开这本提示词手册。

5.AIGC视频教程合集
观看全面零基础学习视频,看视频学习是最快捷也是最有效果的方式,跟着视频中老师的思路,从基础到深入,还是很容易入门的。

实战案例
纸上得来终觉浅,要学会跟着视频一起敲,要动手实操,才能将自己的所学运用到实际当中去,这时候可以搞点实战案例来学习。

这份完整版的学习资料已经上传CSDN,朋友们如果需要可以微信扫描下方CSDN官方认证二维码免费领取【保证100%免费】

















 1021
1021

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









