











这两天社区出了混元版的首尾帧,模型效果不错,可以玩起来,显存最低要16G
一、混元首尾帧介绍
今天继续分享混元视频,最近社区有人分享了混元的首尾帧的lora模型,测试下来发现效果很不错,也算补齐了这一个短板。
在人工智能驱动的视频创作领域,Runway 的 Gen-3 Alpha Turbo 和 Kling 等工具展示了基于关键帧的生成的潜力,可实现指定帧之间的平滑过渡。受此方法的启发,推出了Hunyuan Keyframe LoRA ,这是一款基于Hunyuan Video框架构建的开源解决方案。此模型使创作者能够在开源生态系统中定义关键帧并生成无缝视频序列。

相关资料:
这份完整版的AI资料已经上传CSDN,朋友们如果需要可以微信扫描下方CSDN官方认证二维码免费领取【保证100%免费】

今天就来带大家体验一下。
二、相关安装
要体验混元的这个首尾帧,要满足以下条件
插件安装
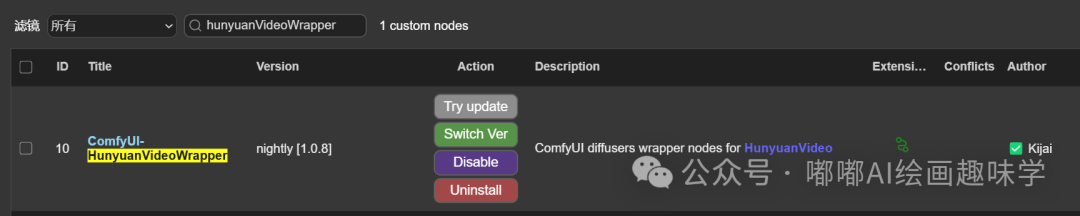
插件地址:https://github.com/kijai/ComfyUI-HunyuanVideoWrapper
用到的插件还是KJ大佬的 ComfyUI-HunyuanVideoWrapper,这个是老演员了,大家更新到最新的即可。
模型安装
-
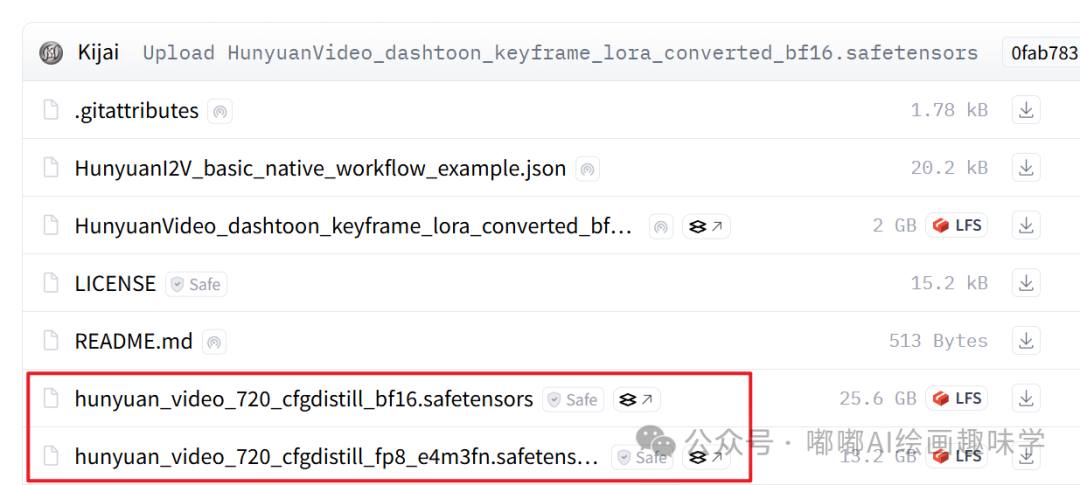
hunyuan_video_720_cfgdistill_bf16.safetensors:视频模型用的是以前文生视频模型,不是最新的图生视频模型。
-
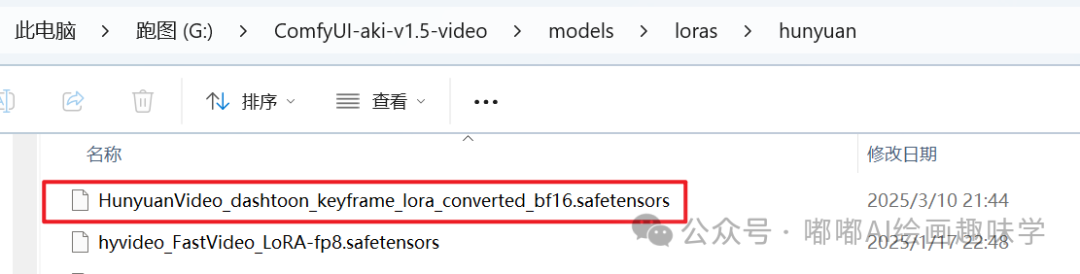
HunyuanVideo_dashtoon_keyframe_lora_converted_bf16.safetensors:LORA模型存放ComfyUI/models/loras目录下,下载:https://github.com/dashtoon/hunyuan-video-keyframe-control-lora
-
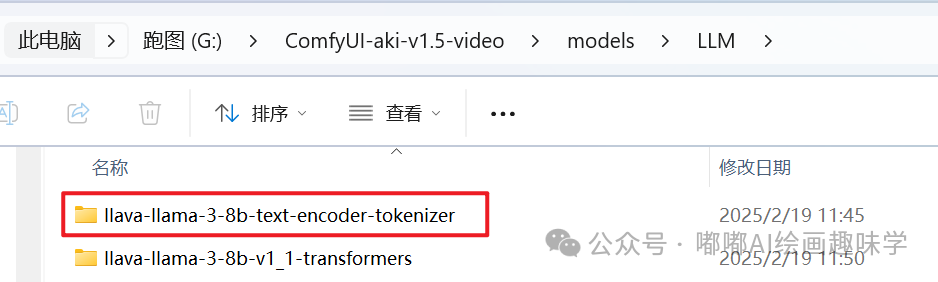
llava-llama-3-8b-text-encoder-tokenizer
-
clip-vit-large-patch14
-
hunyuan_video_vae_bf16.safetensors
这些模型完整路径截图如下,以上就是用到的相关模型,文末网盘都会给出。
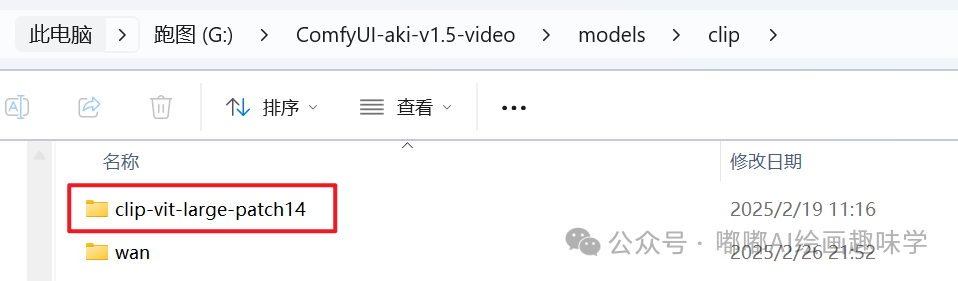
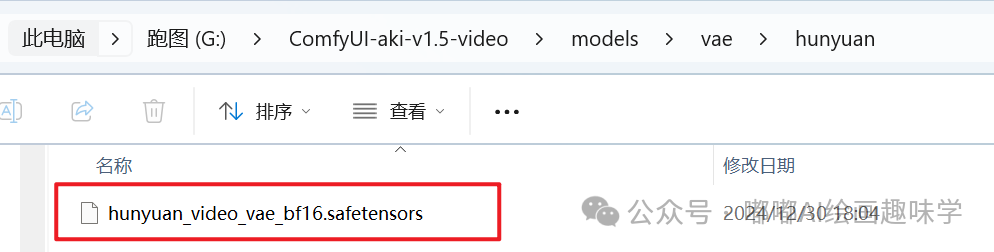
三、使用说明
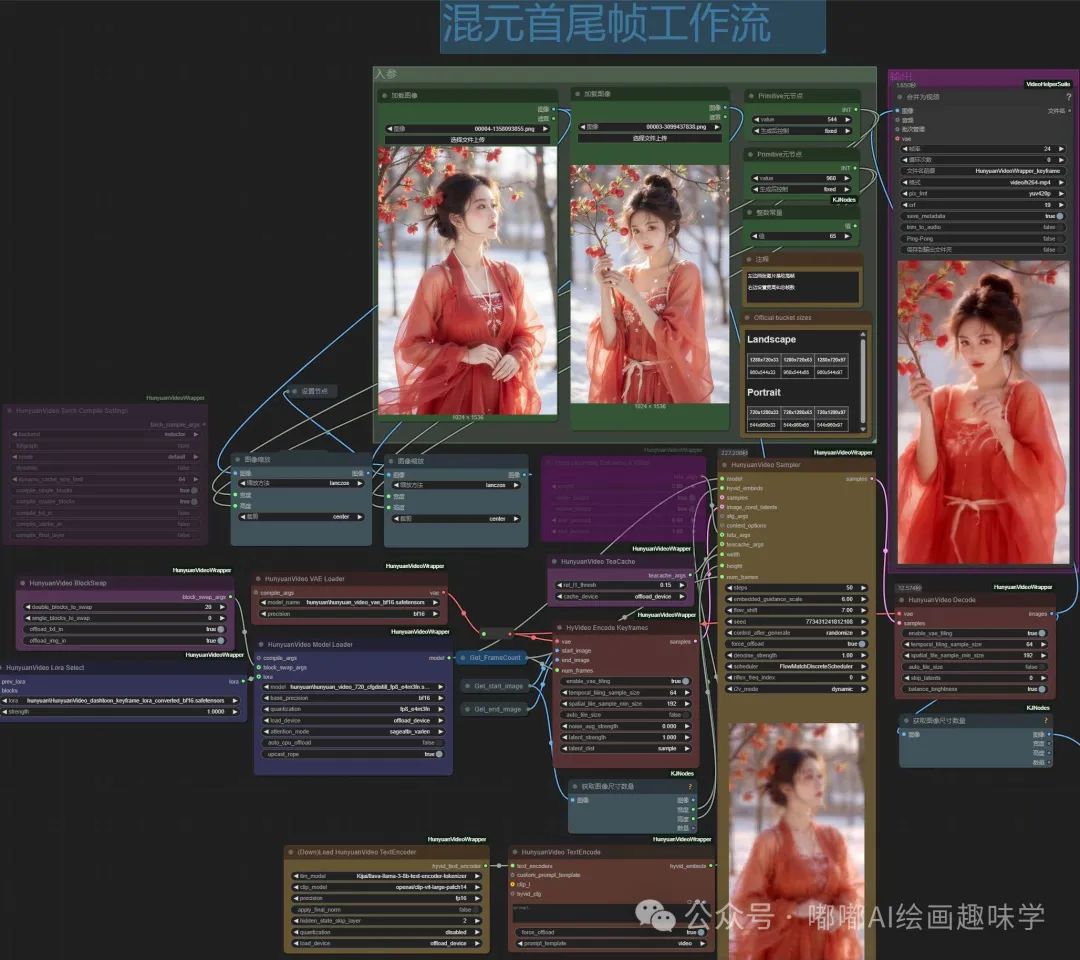
完整工作流如下,已同步各大平台
liblib:https://www.liblib.art/modelinfo/d372d2bf5480465fa6ea92e5ff5864f8
RunningHUB:https://www.runninghub.cn/ai-detail/1899161829959188481?utm_source=kol01-RH024
这是官方的一些推荐:
该模型最适合用于人类受试者。单个受试者的图像效果稍好一些。 960x544使用1280x720图像生成分辨率720x1280 544x960 建议将帧数设置为 33 至 97。也可以设置为 121 帧(但没有进行太多测试)。 提示很有帮助,但即使没有提示也能发挥作用。提示可以简单到只是您想要生成的对象的名称,也可以很详细。 num_inference_steps建议为 50,但为了快速获得结果,您也可以使用 30。不建议小于 30。
-
该模型在人类主体上表现最佳,单主体图像效果稍好。
-
推荐使用以下图像生成分辨率:720x1280、544x960、1280x720、960x544。
-
建议帧数范围设置为33到97帧,最高可扩展至121帧(但未经充分测试)。
-
**提示词(Prompt)**能显著提升效果,但非必需,简单如物体名称或详细描述均可。
-
num_inference_steps参数推荐设置为50,若需快速生成可使用30步,不建议小于30。
我跑了几组效果,发现真不错,我提示词没用,就是单纯的用两张图来跑,尺寸用的是544x960,65帧画了243秒。
下面来看看我跑的几组案例:



对了,这里我没开 Enhance A Video,因为开了效果会差一些。 下面是开了前后的效果对比。左边是开启了EAV,视频图就崩了。

四、云端镜像
大家如果没有本地 ComfyUI 环境,或者本地显卡配置低于 16G 的,可以使用我部署的云镜像,可直接加载使用。后续分享的工作流都会更像到镜像中,一周更新一次,方便大学学习。
这份完整版的AI新手入门资料已经上传CSDN,朋友们如果需要可以微信扫描下方CSDN官方认证二维码免费领取【保证100%免费】

















 143
143

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









