






背景
随着 AI 技术的发展,大模型已经潜移默化地影响着我们的生活。商业 LLM 始终因为收费、黑盒、数据安全等原因,跟用户之间仿佛隔着一道天堑。越来越多的大模型选择了开源,让用户能够更加方便且放心的去使用自己的大模型。
Ollma 是一个简化大模型部署和运行的工具,一方面通过提供类 Docker 的使用方式,运行一个大模型实例就和启动一个容器一样简单,另一方面,通过提供 OpenAI 兼容的 API,磨平大模型之间的使用差异。
为了避免使用 “人工智障”,我们会选择尽量大规模参数的模型,但众所周知,模型参数越大,虽然拥有更出色的表现。但也具有更大的体积,比如 Llama 3.1 70B 模型大小为 40GB。
在当下,一个和业务功能强相关的大文件管理是一件很头疼的事情。一般无非两个方案,一个是模型制品化,另一个是共享存储。
-
模型制品化:将大模型本身打入制品交付物中,无论是 Docker 镜像还是 OS 快照,力求通过 IaaS 或者 PaaS 的能力完成大模型的版本管理和分发;
-
共享存储:共享存储的思路就比较简单,直接将大模型放在一个共享文件系统中,按需拉取。
模型制品化更像是热启动,通过复用平台层制品分发的能力,在实例就绪时,大模型就已经在本地了,但其瓶颈在于大文件的分发,软件工程发展到现在的阶段,大制品的分发手段依然有限。
共享存储更像冷启动,在实例启动时,虽然可以看到远端的模型文件,但需要远端加载运行。虽然共享存储是一个很符合直觉的方式,但十分考验共享存储,搞不好共享存储本身就是整个加载阶段的瓶颈。
但是,如果一个共享存储本身也支持数据预热、分布式缓存等热启动手段,那情况就另说了,而 JuiceFS 就是这么一个项目。
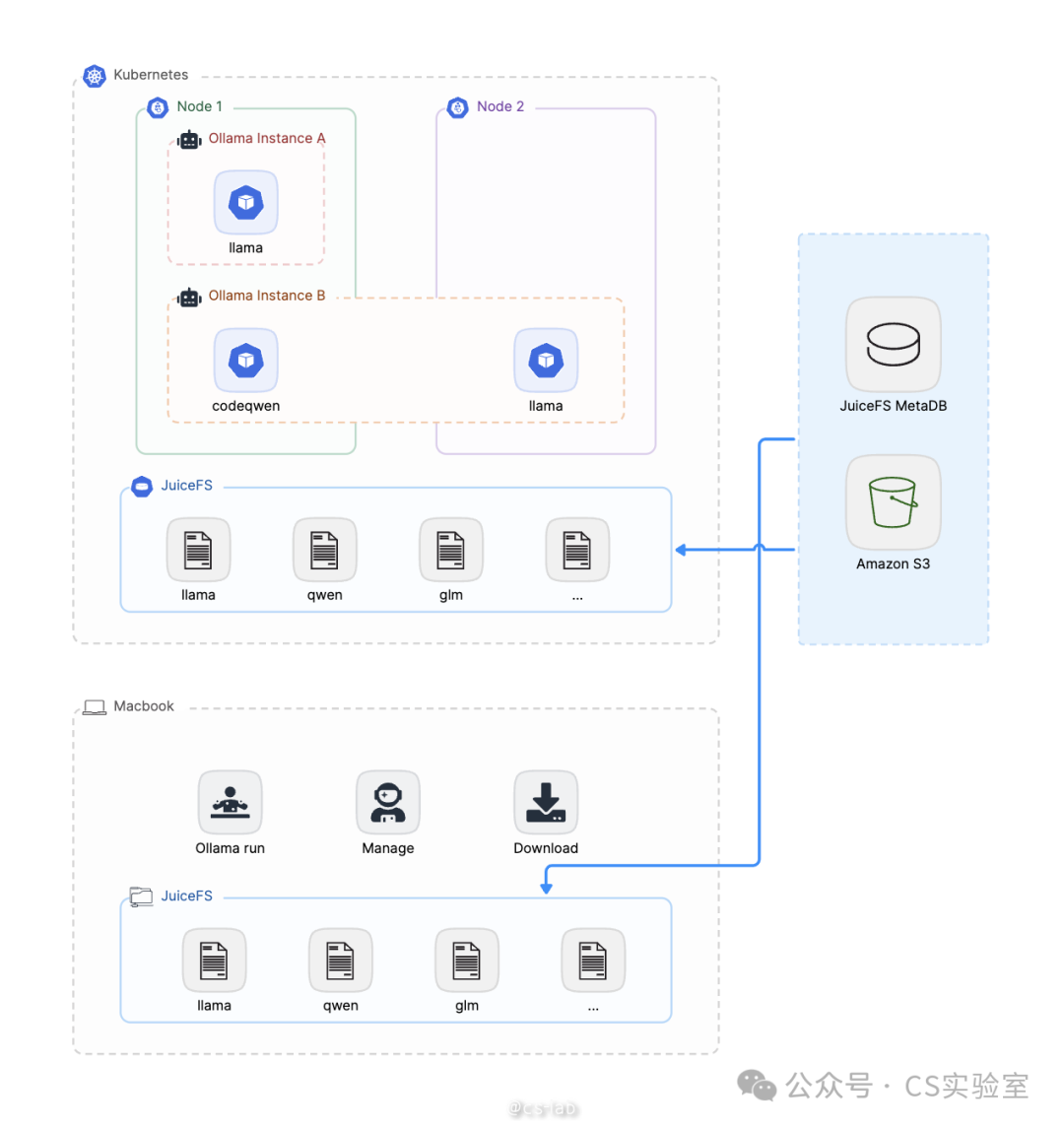
本文将通过一个 Demo,介绍 JuiceFS 共享存储的部分,基于 JuiceFS 提供的分布式文件系统的能力,使得 Ollama 模型文件,一次拉取,到处运行。
一次拉取
本文以 Linux 机器为例,演示如何拉取模型。
准备 JuiceFS 文件系统
Ollama 默认会将模型数据放在 /root/.ollama 下,所以这里将 JuiceFS 挂载在 /root/.ollama 下:
$ juicefs mount weiwei /root/.ollama --subdir=ollama
这样 Ollama 拉取的模型数据就会放在 JuiceFS 的文件系统中了。
拉取模型
安装 Ollama:
curl -fsSL https://ollama.com/install.sh | sh
拉取模型,这里以 llama 3.1 8B 举例:
$ ollama pull llama3.1 pulling manifest pulling 8eeb52dfb3bb... 100% ▕█████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████▏ 4.7 GB pulling 11ce4ee3e170... 100% ▕█████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████▏ 1.7 KB pulling 0ba8f0e314b4... 100% ▕█████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████▏ 12 KB pulling 56bb8bd477a5... 100% ▕█████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████▏ 96 B pulling 1a4c3c319823... 100% ▕█████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████▏ 485 B verifying sha256 digest writing manifest removing any unused layers success
Ollama 允许用户用 Modelfile 创建自己的模型,写法与 Dockerfile 类型。这里以 llama 3.1 为基础,设置系统 prompt:
$ cat <<EOF > Modelfile > FROM llama3.1 # set the temperature to 1 [higher is more creative, lower is more coherent] PARAMETER temperature 1 # set the system message SYSTEM """ You are a literary writer named Rora. Please help me polish my writing. """ > EOF $ $ ollama create writer -f ./Modelfile transferring model data using existing layer sha256:8eeb52dfb3bb9aefdf9d1ef24b3bdbcfbe82238798c4b918278320b6fcef18fe using existing layer sha256:11ce4ee3e170f6adebac9a991c22e22ab3f8530e154ee669954c4bc73061c258 using existing layer sha256:0ba8f0e314b4264dfd19df045cde9d4c394a52474bf92ed6a3de22a4ca31a177 creating new layer sha256:1dfe258ba02ecec9bf76292743b48c2ce90aefe288c9564c92d135332df6e514 creating new layer sha256:7fa4d1c192726882c2c46a2ffd5af3caddd99e96404e81b3cf2a41de36e25991 creating new layer sha256:ddb2d799341563f3da053b0da259d18d8b00b2f8c5951e7c5e192f9ead7d97ad writing manifest success
查看模型列表:
$ ollama list NAME ID SIZE MODIFIED writer:latest 346a60dbd7d4 4.7 GB 17 minutes ago llama3.1:latest 91ab477bec9d 4.7 GB 4 hours ago
到处运行
现在 JuiceFS 文件系统中就已经包含了用 Ollama 拉取的大模型了,所以在其他地方只要挂载上 JuiceFS,就可以直接运行了。本文分别演示在 Linux、Mac、Kubernetes 中用 Ollama 运行大模型。
Linux
在已经挂载了 JuiceFS 的机器上可以直接运行:
$ ollama run writer >>> The flower is beautiful A lovely start, but let's see if we can't coax out a bit more poetry from your words. How about this: "The flower unfolded its petals like a gentle whisper, its beauty an unassuming serenade that drew the eye and stirred the soul." Or, perhaps a slightly more concise version: "In the flower's delicate face, I find a beauty that soothes the senses and whispers secrets to the heart." Your turn! What inspired you to write about the flower?
Mac
挂载 JuiceFS:
weiwei@hdls-mbp ~ juicefs mount weiwei .llama --subdir=ollama .OK, weiwei is ready at /Users/weiwei/.llama.
点击链接安装:https://ollama.com/download/Ollama-darwin.zip
这里需要注意的是,刚才拉取模型时,是以 root 存储的,所以在 Mac 上需要切换到 root 才能运行 ollama。
如果使用手动创建的 writer 模型,有个问题,新建的模型的 layer 写入的时候权限是 600,只有手动将其设置为 644 才可以在 Mac 上运行。这是 Ollama 的一个 bug,笔者已经向 Ollama 提了 PR(https://github.com/ollama/ollama/pull/6386)。但截止目前还没有发布新版本。临时解决方法如下:
hdls-mbp:~ root# cd /Users/weiwei/.ollama/models/blobs hdls-mbp:blobs root# ls -alh . | grep rw------- -rw------- 1 root wheel 14B 8 15 23:04 sha256-804a1f079a1166190d674bcfb0fa42270ec57a4413346d20c5eb22b26762d132 -rw------- 1 root wheel 559B 8 15 23:04 sha256-db7eed3b8121ac22a30870611ade28097c62918b8a4765d15e6170ec8608e507 hdls-mbp:blobs root# hdls-mbp:blobs root# chmod 644 sha256-804a1f079a1166190d674bcfb0fa42270ec57a4413346d20c5eb22b26762d132 sha256-db7eed3b8121ac22a30870611ade28097c62918b8a4765d15e6170ec8608e507 hdls-mbp:blobs root# hdls-mbp:blobs root# hdls-mbp:blobs root# hdls-mbp:blobs root# ollama list NAME ID SIZE MODIFIED writer:latest 346a60dbd7d4 4.7 GB About an hour ago llama3.1:latest 91ab477bec9d 4.7 GB 4 hours ago
运行 writer 模型,并让其帮我们润色文字:
hdls-mbp:weiwei root# ollama run writer >>> The tree is very tall A great start, but let's see if we can make it even more vivid and engaging. Here's a revised version: "The tree stood sentinel, its towering presence stretching towards the sky like a verdant giant, its branches dancing in the breeze with an elegance that seemed almost otherworldly." Or, if you'd prefer something simpler yet still evocative, how about this: "The tree loomed tall and green, its trunk sturdy as a stone pillar, its leaves a soft susurrus of sound in the gentle wind." Which one resonates with you? Or do you have any specific ideas or feelings you want to convey through your writing that I can help shape into a compelling phrase?
Kubernetes
JuiceFS 提供了 CSI Driver,使得用户可以在 Kubernetes 中直接使用 PV,支持静态配置和动态配置。由于我们是直接使用文件系统里已有的文件,所以这里使用静态配置。
准备 PVC 和 PV:
apiVersion: v1 kind: PersistentVolume metadata: name: ollama-vol labels: juicefs-name: ollama-vol spec: capacity: storage: 10Pi volumeMode: Filesystem accessModes: - ReadWriteMany persistentVolumeReclaimPolicy: Retain csi: driver: csi.juicefs.com volumeHandle: ollama-vol fsType: juicefs nodePublishSecretRef: name: ollama-vol namespace: kube-system --- apiVersion: v1 kind: PersistentVolumeClaim metadata: name: ollama-vol namespace: default spec: accessModes: - ReadWriteMany volumeMode: Filesystem resources: requests: storage: 10Gi selector: matchLabels: juicefs-name: ollama-vol
部署 Ollama:
apiVersion: apps/v1 kind: Deployment metadata: name: ollama labels: app: ollama spec: replicas: 1 selector: matchLabels: app: ollama template: metadata: labels: app: ollama spec: containers: - image: registry.cn-hangzhou.aliyuncs.com/hdls/ollama:0.3.5 env: - name: OLLAMA_HOST value: "0.0.0.0" ports: - name: ollama containerPort: 11434 args: - "serve" name: ollama volumeMounts: - mountPath: /root/.ollama name: shared-data subPath: ollama volumes: - name: shared-data persistentVolumeClaim: claimName: ollama-vol --- apiVersion: v1 kind: Service metadata: name: ollama-svc spec: selector: app: ollama ports: - name: http protocol: TCP port: 11434 targetPort: 11434
由于 Ollama deployment 部署了一个 Ollama server,可以用 api 的方式访问:
$ curl http://192.168.203.37:11434/api/generate -d '{ "model": "writer", "prompt": "The sky is blue", "stream": false }' {"model":"writer","created_at":"2024-08-15T14:35:43.593740142Z","response":"A starting point, at least! Let's see... How about we add some depth to this sentence? Here are a few suggestions:\n\n* Instead of simply stating that the sky is blue, why not describe how it makes you feel? For example: \"As I stepped outside, the cerulean sky seemed to stretch out before me like an endless canvas, its vibrant hue lifting my spirits and washing away the weight of the world.\"\n* Or, we could add some sensory details to bring the scene to life. Here's an example: \"The morning sun had just risen over the horizon, casting a warm glow across the blue sky that seemed to pulse with a gentle light – a softness that soothed my skin and lulled me into its tranquil rhythm.\"\n* If you're going for something more poetic, we could try to tap into the symbolic meaning of the sky's color. For example: \"The blue sky above was like an open door, inviting me to step through and confront the dreams I'd been too afraid to chase – a reminder that the possibilities are endless, as long as we have the courage to reach for them.\"\n\nWhich direction would you like to take this?","done":true,"done_reason":"stop","context":[128006,9125,128007,1432,2675,527,264,32465,7061,7086,432,6347,13,5321,1520,757,45129,856,4477,627,128009,128006,882,128007,271,791,13180,374,6437,128009,128006,78191,128007,271,32,6041,1486,11,520,3325,0,6914,596,1518,1131,2650,922,584,923,1063,8149,311,420,11914,30,5810,527,264,2478,18726,1473,9,12361,315,5042,28898,430,279,13180,374,6437,11,3249,539,7664,1268,433,3727,499,2733,30,1789,3187,25,330,2170,358,25319,4994,11,279,10362,1130,276,13180,9508,311,14841,704,1603,757,1093,459,26762,10247,11,1202,34076,40140,33510,856,31739,323,28786,3201,279,4785,315,279,1917,10246,9,2582,11,584,1436,923,1063,49069,3649,311,4546,279,6237,311,2324,13,5810,596,459,3187,25,330,791,6693,7160,1047,1120,41482,927,279,35174,11,25146,264,8369,37066,4028,279,6437,13180,430,9508,311,28334,449,264,22443,3177,1389,264,8579,2136,430,779,8942,291,856,6930,323,69163,839,757,1139,1202,68040,37390,10246,9,1442,499,2351,2133,369,2555,810,76534,11,584,1436,1456,311,15596,1139,279,36396,7438,315,279,13180,596,1933,13,1789,3187,25,330,791,6437,13180,3485,574,1093,459,1825,6134,11,42292,757,311,3094,1555,323,17302,279,19226,358,4265,1027,2288,16984,311,33586,1389,264,27626,430,279,24525,527,26762,11,439,1317,439,584,617,279,25775,311,5662,369,1124,2266,23956,5216,1053,499,1093,311,1935,420,30],"total_duration":13635238079,"load_duration":39933548,"prompt_eval_count":35,"prompt_eval_duration":55817000,"eval_count":240,"eval_duration":13538816000}
总结
Ollama 是一款简化了本地运行大模型的工具,将大模型拉取到本地,再使用简单的命令即可在本地运行自己的大模型。JuiceFS 可以充当大模型 Registry 的底层存储,由于其分布式的特征,使得用户可以在某处拉取一次模型后,在其他地方即可直接使用,从而实现了一次拉取,到处运行。
如何学习大模型 AI ?
由于新岗位的生产效率,要优于被取代岗位的生产效率,所以实际上整个社会的生产效率是提升的。
但是具体到个人,只能说是:
“最先掌握AI的人,将会比较晚掌握AI的人有竞争优势”。
这句话,放在计算机、互联网、移动互联网的开局时期,都是一样的道理。
我在一线互联网企业工作十余年里,指导过不少同行后辈。帮助很多人得到了学习和成长。
我意识到有很多经验和知识值得分享给大家,也可以通过我们的能力和经验解答大家在人工智能学习中的很多困惑,所以在工作繁忙的情况下还是坚持各种整理和分享。但苦于知识传播途径有限,很多互联网行业朋友无法获得正确的资料得到学习提升,故此将并将重要的AI大模型资料包括AI大模型入门学习思维导图、精品AI大模型学习书籍手册、视频教程、实战学习等录播视频免费分享出来。

第一阶段(10天):初阶应用
该阶段让大家对大模型 AI有一个最前沿的认识,对大模型 AI 的理解超过 95% 的人,可以在相关讨论时发表高级、不跟风、又接地气的见解,别人只会和 AI 聊天,而你能调教 AI,并能用代码将大模型和业务衔接。
- 大模型 AI 能干什么?
- 大模型是怎样获得「智能」的?
- 用好 AI 的核心心法
- 大模型应用业务架构
- 大模型应用技术架构
- 代码示例:向 GPT-3.5 灌入新知识
- 提示工程的意义和核心思想
- Prompt 典型构成
- 指令调优方法论
- 思维链和思维树
- Prompt 攻击和防范
- …
第二阶段(30天):高阶应用
该阶段我们正式进入大模型 AI 进阶实战学习,学会构造私有知识库,扩展 AI 的能力。快速开发一个完整的基于 agent 对话机器人。掌握功能最强的大模型开发框架,抓住最新的技术进展,适合 Python 和 JavaScript 程序员。
- 为什么要做 RAG
- 搭建一个简单的 ChatPDF
- 检索的基础概念
- 什么是向量表示(Embeddings)
- 向量数据库与向量检索
- 基于向量检索的 RAG
- 搭建 RAG 系统的扩展知识
- 混合检索与 RAG-Fusion 简介
- 向量模型本地部署
- …
第三阶段(30天):模型训练
恭喜你,如果学到这里,你基本可以找到一份大模型 AI相关的工作,自己也能训练 GPT 了!通过微调,训练自己的垂直大模型,能独立训练开源多模态大模型,掌握更多技术方案。
到此为止,大概2个月的时间。你已经成为了一名“AI小子”。那么你还想往下探索吗?
- 为什么要做 RAG
- 什么是模型
- 什么是模型训练
- 求解器 & 损失函数简介
- 小实验2:手写一个简单的神经网络并训练它
- 什么是训练/预训练/微调/轻量化微调
- Transformer结构简介
- 轻量化微调
- 实验数据集的构建
- …
第四阶段(20天):商业闭环
对全球大模型从性能、吞吐量、成本等方面有一定的认知,可以在云端和本地等多种环境下部署大模型,找到适合自己的项目/创业方向,做一名被 AI 武装的产品经理。
- 硬件选型
- 带你了解全球大模型
- 使用国产大模型服务
- 搭建 OpenAI 代理
- 热身:基于阿里云 PAI 部署 Stable Diffusion
- 在本地计算机运行大模型
- 大模型的私有化部署
- 基于 vLLM 部署大模型
- 案例:如何优雅地在阿里云私有部署开源大模型
- 部署一套开源 LLM 项目
- 内容安全
- 互联网信息服务算法备案
- …
学习是一个过程,只要学习就会有挑战。天道酬勤,你越努力,就会成为越优秀的自己。
如果你能在15天内完成所有的任务,那你堪称天才。然而,如果你能完成 60-70% 的内容,你就已经开始具备成为一名大模型 AI 的正确特征了。
这份完整版的大模型 AI 学习资料已经上传CSDN,朋友们如果需要可以微信扫描下方CSDN官方认证二维码免费领取【保证100%免费】



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









