







 本文介绍了如何使用Python通过requests和BeautifulSoup库爬取中国金融期货交易所的静态网页,抓取期货法规PDF文件,并存储到本地文件夹。作者详细展示了请求数据、解析HTML和下载文件的过程。
本文介绍了如何使用Python通过requests和BeautifulSoup库爬取中国金融期货交易所的静态网页,抓取期货法规PDF文件,并存储到本地文件夹。作者详细展示了请求数据、解析HTML和下载文件的过程。
一、观察网页
(1)通过谷歌浏览器进入中国金融期货交易所
网页地址:http://www.cffex.com.cn/qhfg/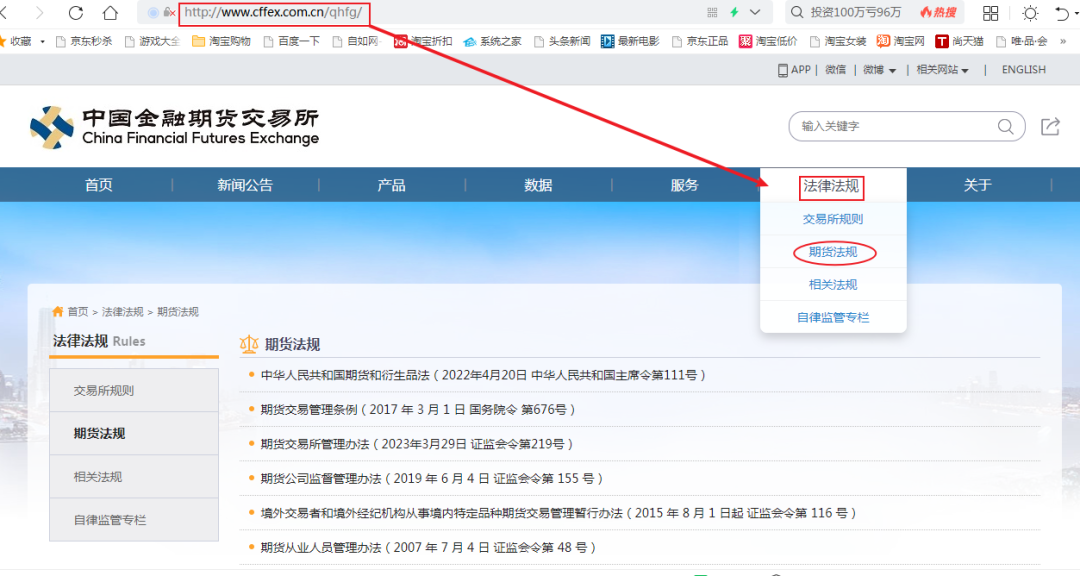
(2)判断所爬取的网页是否为静态网页。判断网页属于静态网页还是动态网页是进行Python数据收集工作的第一步,我们可以看到,在对网页进行翻页时,网址栏的网址发生了变化,说明这是静态网页。
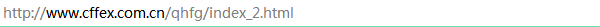
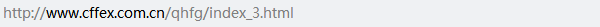
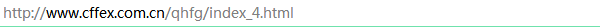
二、引入所需的第三方库
这里我们可以导入os库用来处理文件路径,导入requests库,用于向网络请求数据,导入pandas用于数据处理与分析,导入BeautifulSoup用于解析HTML或XML格式网页数据。
代码如下:
import os import requests import pandas as pd from bs4 import BeautifulSoup
三、请求数据
观察Headers可以发现Request Method为GET,我们可以采用requests库请求数据。
代码如下:
`url = 'http://www.cffex.com.cn/qhfg/&# 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 2534
2534

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









