







目前使用 Stable Diffusion 进行创作的工具主要有两个:WebUI 和
ComfyUI。而更晚出现的ComfyUI凭借超高的可定制性和复现性迅速火遍全球。有设计师表示SD发布了XL1.0后,ComfyUI用它优秀的底层逻辑率先打击了臃肿不稳定的WebUI1.6,成为更适合“体验”XL的SD生图工具。
本文就来具体介绍一下ComfyUI是什么?为什么好?怎么用?

ComfyUI是一个专为StableDiffusion设计的基于节点的图形用户界面(GUI),简单来说就是将整个图像生成过程分解为多个独立的节点,每个节点都有自己独立的功能,例如加载模型,文本提示,生成图片等等。每个模块通过输入和输出的线连在一起变成一个完整的工作流。
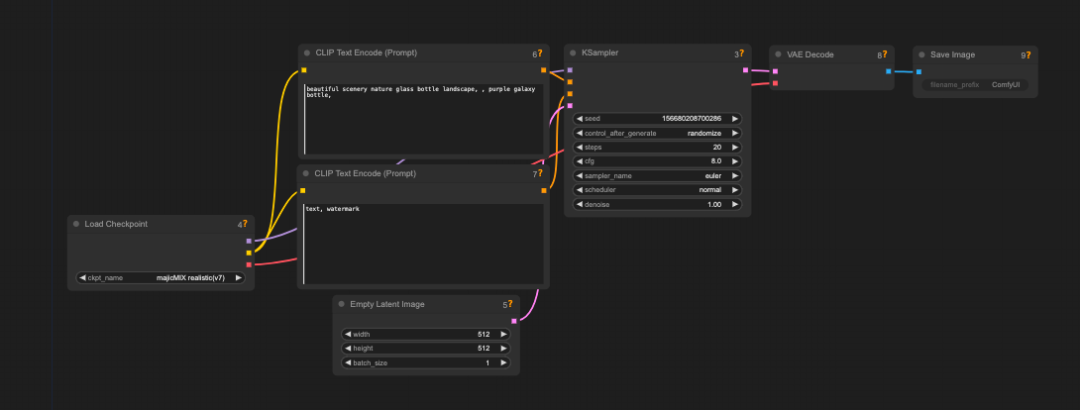
整个过程用户可以灵活的调整和配置不同的功能节点,这就代表整个模型更加自由,控制更加精准。

相比于WebUI,ComfyUI的工作流模式更加贴近Stable
Diffusion的底层运行逻辑,这对于新手来说有一定的学习门槛,但是在完全掌握以后使用ComfyUI将会变得非常轻松,同时在AI盛行的时代,懂得一些底层逻辑也有助于设计师后续的发展。所以本文将结合SD的底层逻辑和大家简单解释ComfyUI的基础节点。
Stable Diffusion之所以叫Stable,是因为公司叫StabilityAI。其基础模型是Latent Diffusion
Model(LDM),翻译为潜在扩散模型,可以理解为主要的图片生成流程都在一个叫「latent space(潜在空间)」的魔法盒子里进行。
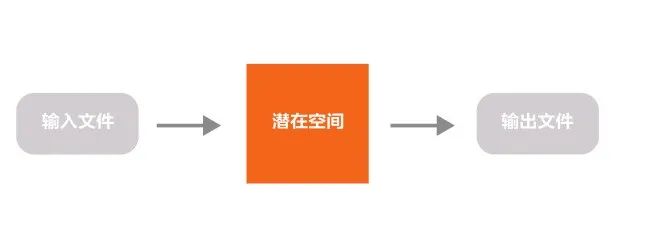
图片在这个空间存在的方式是我们无法识别的向量,我们只需要知道这些我们无法识别的东西所表示的信息和图片相差无几,但是数据尺寸却变得非常小就行,这是一个类似于压缩的过程,所以在这个空间中进行运行可以大大缩小运行内存。
这个过程可以简单理解为,向潜在空间输入文件,数据经过处理生成图片并输出
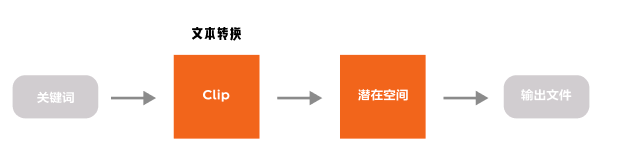
以文本生图为例,我们现在来解释整个流程中包含的节点及作用。
输入文件包含了我们熟知的常规内容:文本和图片,也就对应着Text2Image和Image2Image。但是文本内容计算机是无法理解的,所以我们需要将文本转换为计算机能够理解的信息,这个过程使用了Clip模型。(图片的转换是使用了VAE模型)
熟悉WebUI的朋友可以知道,控制模型实际生成部分的模型是KSampler(采样器),在这其中我们可以控制迭代次数,种子数等等。而这个步骤就发生在潜在空间中。

我们在前面的内容可以知道,潜在空间的内容不是人类可以读取的内容,文本的输入需要转换,同样图片的输出也需要转换,这个过程同样使用了VAE模型。
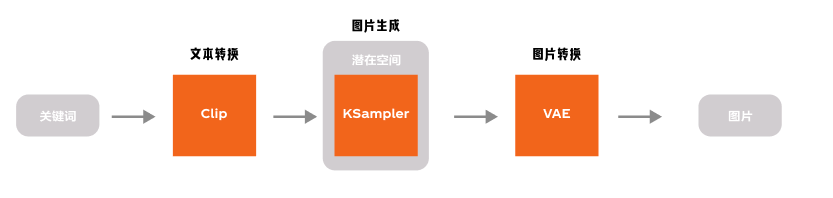
这就是最基础的文生图过程,现在再回看ComfyUI的基础模型是不是会清晰很多。
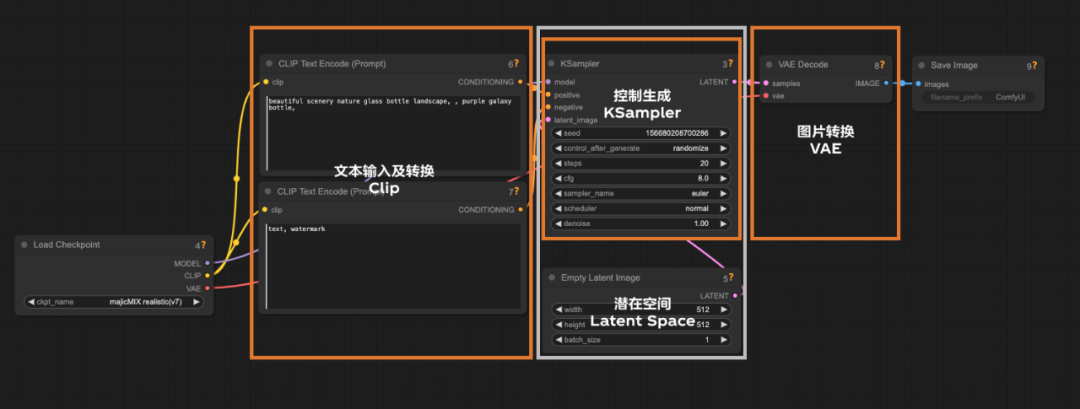
而整个工作流的运行由大模型控制,所以在工作流以CheckPoint节点加载扩散模型为起点,CheckPoint节点还会提供适当的VAE和Clip模型。但这并不影响工作流中使用自己选择的VAE和Clip模型。
到这里我们就已经完全了解了一个最基础的文生图过程和相对应的ComfyUI节点,更多进阶内容大家都可以更加深入的探索。

作为现在最火爆的两大创作工具, WebUI
开箱即用,基本功能齐全,社区也有很多的插件支持,入门比较简单,适合新手,但是可定制性稍微差点,很多作品不容易传播复现,使用API进行操作也有一定的难度。
ComfyUI
虽然出来的晚一点,但是它的可定制性很强,可以让创作者搞出各种新奇的玩意,通过工作流的方式,也可以实现更高的自动化水平,创作方法更容易传播复现,发展势头特别迅猛。两者对比有非常多显著的差别。
· ComfyUI对显卡比较友好
即使是GPU小于3G的情况下也能正常工作。它占用的显存更少,在相同显存条件下能够生成更大尺寸的图像。同时,Mac电脑也能顺利运行ComfyUI(建议M1以上的电脑使用),虽然依旧达不到Windos的运行效率,但这也给Mac用户提供了一个可以使用SD生图的机会。而WebUI近乎抛弃了12G显存以下的用户,显存使用效率较低,更不提Mac用户。
· ComfyUI运行效率极大的提高
设计师通过 ComfyUI 和 Automatic1111 WebUI 运行了一批 20 张图像,以查看每张图像的总时间。这些图像基于Stable
Diffusion 1.5模型,分辨率为 512x768。作为参考,使用的是 RTX 3060(12GB VRAM)。最后的结果如下
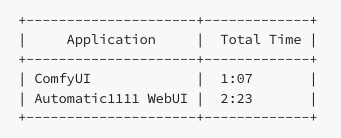
WebUI要花费ComfyUI两倍多的时间,这是一个相当大的的差距。当你使用SD生成视频渲染每一帧时这种时间差异会更加明显。
· ComfyUI可以实现实时预览
用户能够即时看到生成结果。这归功于节点拼接的高自由度,你可以在任何一个位置插入图片生成的功能节点,这样就可以在你想要预览图片的位置实时预览图片生成效果。
· ComfyUI可以完全实现工作流的复用
ComfyUI的工作流可以单独作为Json文件保存,你可以通过下载的工作流文件直接使用理想效果的工作流,也可以在这份文件上进行任意的修改和添加。值得注意的是,通过ComfyUI生成的图片原文件也保留着工作流数据,也就是说,你只要下载社交媒体上设计师上传的图片原文件拖拽放入ComfyUI中,工作流会被立刻复现。
· 与WebUI共通模型
WebUI与ComfyUI本质都是使用Stable
Diffusion大模型进行生图,只是使用方式不同,所以如果你是WebUI的老用户,你可以直接将WebUI中使用的模型与ComfyUI共通,过程非常简单,后面会提到。

在这里为新手的设计师提供一些你一定会用到的使用技巧
· ComfyUI Manager
ComfyUI是完全通过节点组成,所以下载不同的节点是最开始就会遇到的问题。ComfyUI
Manager作为一个节点,你可以将它看作一个插件,它可以下载几乎所有你能使用到的节点,并且提供了更新、管理自定义节点等等的功能。下载了它几乎等于你不会再通过Github安装节点。
安装完成ComfyUI Manager后,重启ComfyUI,在右边可以找到一个「manager」点击就可以进入插件界面。
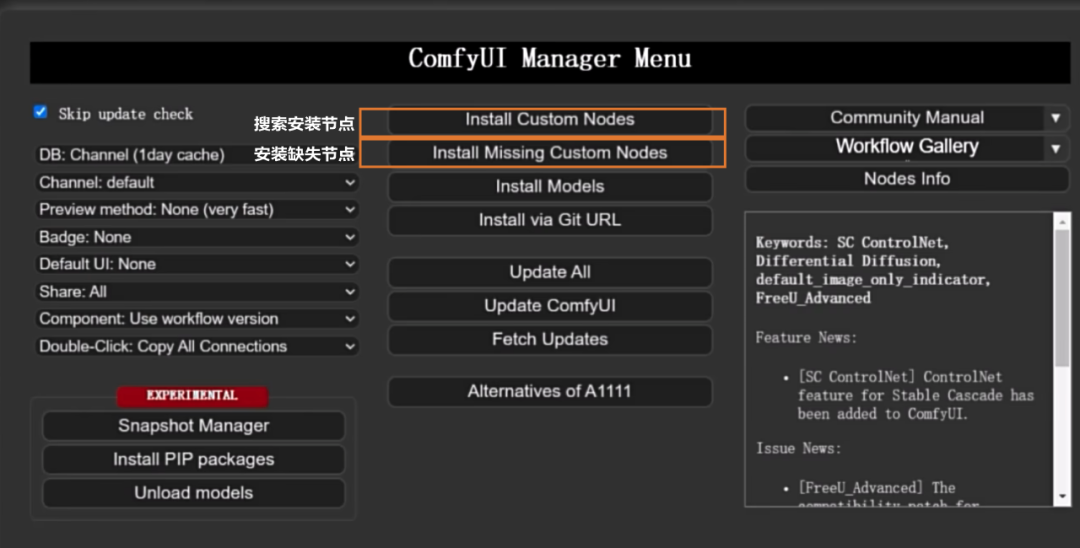
其中有两个最常用的功能就是搜索安装节点和一键安装工作流中的所有缺失节点。
ComfyUI Manager:github.com/ltdrdata/ComfyUI-Manager
· 将WebUI中的模型导入ComfyUI
用过WebUI的设计师应该已经下载了很多自己顺手的模型,这些模型在ComfyUI中也是通用的,所以我们只需要共享这些模型就可以使用
具体流程如下:
1.在ComfyUI目录中,有一个extra_model_paths.yaml.example文件,将其重命名为extra_model_paths.yaml
2.打开该文件,找到base_path:path/to/stable-diffusion-
webui/,将路径替换为你的WebUI的路径,例如base_path:D/StableDiffusion/stable-diffusion-webui/
3.最后重启ComfyUI,你就可以在Load Checkpoint中的Ckpt_name中找到

如果你使用的是Windows平台且为N卡用户,只需要在项目主页的Release页面下载作者提供的“官方整合包”
https://github.com/comfyanonymous/ComfyUI/releases

设计是一门不断发展的艺术和科学。保持对新技术、新方法的好奇心,是我们不停向上走的助力。但尽管AI可以提供很多帮助,设计的核心仍然是人类的情感和体验。确保设计作品能够与用户产生情感共鸣,始终保持人性化的触感。希望我们能够继续发挥创造力和想象力,利用AI和其他新技术,创造出更多美丽、有用且有意义的设计作品。
关于AI绘画技术储备
学好 AI绘画 不论是就业还是做副业赚钱都不错,但要学会 AI绘画 还是要有一个学习规划。最后大家分享一份全套的 AI绘画 学习资料,给那些想学习 AI绘画 的小伙伴们一点帮助!
这份完整版的comfyui整合包已经上传CSDN,朋友们如果需要可以微信扫描下方CSDN官方认证二维码免费领取【保证100%免费】

对于0基础小白入门:
如果你是零基础小白,想快速入门AI绘画是可以考虑的。
一方面是学习时间相对较短,学习内容更全面更集中。
二方面是可以找到适合自己的学习方案
包括:stable diffusion安装包、stable diffusion0基础入门全套PDF,视频学习教程。带你从零基础系统性的学好AI绘画!
零基础AI绘画学习资源介绍
👉stable diffusion新手0基础入门PDF👈
(全套教程文末领取哈)

👉AI绘画必备工具👈

温馨提示:篇幅有限,已打包文件夹,获取方式在:文末
👉AI绘画基础+速成+进阶使用教程👈
观看零基础学习视频,看视频学习是最快捷也是最有效果的方式,跟着视频中老师的思路,从基础到深入,还是很容易入门的。

温馨提示:篇幅有限,已打包文件夹,获取方式在:文末
👉12000+AI关键词大合集👈

这份完整版的comfyui整合包已经上传CSDN,朋友们如果需要可以微信扫描下方CSDN官方认证二维码免费领取【保证100%免费】

















 2456
2456

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









