






一、Parquet文件格式的优势:
1. 列式存储,只读取需要的数据,降低IO数据量,速度快。
2. 压缩比高,占用空间少,由于PARQUET按列存储,可以使用更高效的压缩编码(例如 Run Length Encoding 和 Delta Encoding)进一步节约存储空间。
3. 自带Schema,parquet文件包含了元数据信息(包含schema合structure),可以通过数据 文件,解析出parquet的schema
4. 具备filter push-down特性
二、Parquet文件结构
4-byte magic number "PAR1"
<Column 1 Chunk 1 + Column Metadata>
<Column 2 Chunk 1 + Column Metadata>
...
<Column N Chunk 1 + Column Metadata>
<Column 1 Chunk 2 + Column Metadata>
<Column 2 Chunk 2 + Column Metadata>
...
<Column N Chunk 2 + Column Metadata>
...
<Column 1 Chunk M + Column Metadata>
<Column 2 Chunk M + Column Metadata>
...
<Column N Chunk M + Column Metadata>
File Metadata
4-byte length in bytes of file metadata
4-byte magic number "PAR1"上面的例子中,可以看到,parquet文件的开头和结尾都有一个magic code,均为四个字节,用来标识该文件为parquet格式。
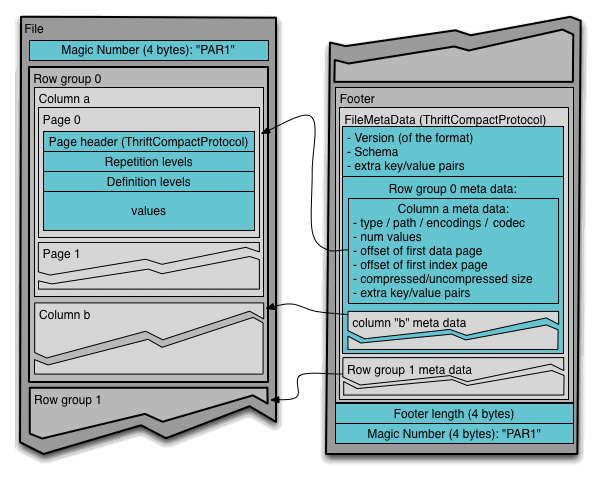
Parquet文件中的数据被切分为不同的Row Group,每个Row Group中包含了一批数据,对应到HDFS的block,每个Row Group分成多个Column Chunk,每个Column Chunk存储每一列的数据,每一个column chunck按照page来进行存储,page按照内容又分为:数据页(datapage),索引页(indexpage),字典页(dictionarypage)三种类型;文件的最后是Footer,里面包含了非常重要的信息,包含文件的schema信息和Row Group元数据信息,Footer length是文件元数据的大小,通过该值和文件长度可以找到元数据Footer的偏移量和起始位置。
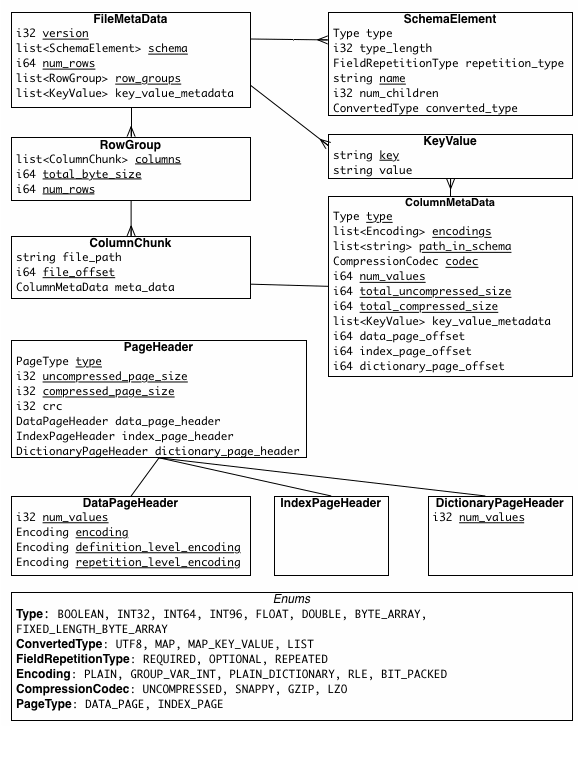
Parquet文件中包含了三种元数据信息,分别为:file metadata, column (chunk) metadata 和 page header metadata
参考文档:















 1万+
1万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









