







1. 准备工作
在本节开始之前,我们需要做好如下的准备工作:
- 安装好 Python3,最低为 3.6 版本,并能成功运行 Python3 程序。
- 了解 Python HTTP 请求库 requests 的基本用法。
- 了解正则表达式的用法和 Python 中正则表达式库 re 的基本用法。
以上内容在前面的章节中均有讲解,如尚未准备好建议先熟悉一下这些内容。
2. 爬取目标
本节我们以一个基本的静态网站作为案例进行爬取,需要爬取的链接为 https://ssr1.scrape.center/ ,这个网站里面包含了一些电影信息,界面如下:

这里首页展示了一个个电影的列表,每部电影包含了它的封面、名称、分类、上映时间、评分等内容,同时列表页还支持翻页,点击相应的页码我们就能进入到对应的新列表页。
如果我们点开其中一部电影,会进入到电影的详情页面,比如我们把第一个电影《霸王别姬》打开,会得到如下的页面:

这里显示的内容更加丰富、包括剧情简介、导演、演员等信息。
我们本节要完成的目标是:
- 用 requests 爬取这个站点每一页的电影列表,顺着列表再爬取每个电影的详情页。
- 用 pyquery 和正则表达式提取每部电影的名称、封面、类别、上映时间、评分、剧情简介等内容。
- 把以上爬取的内容存入 MongoDB 数据库。
- 使用多进程实现爬取的加速。
好,那我们现在就开始吧。
3. 爬取列表页
好,第一步的爬取我们肯定要从列表页入手,我们首先观察一下列表页的结构和翻页规则。在浏览器中访问 https://ssr1.scrape.center/ ,然后打开浏览器开发者工具,我们观察每一个电影信息区块对应的 HTML 以及进入到详情页的 URL 是怎样的,如图所示:
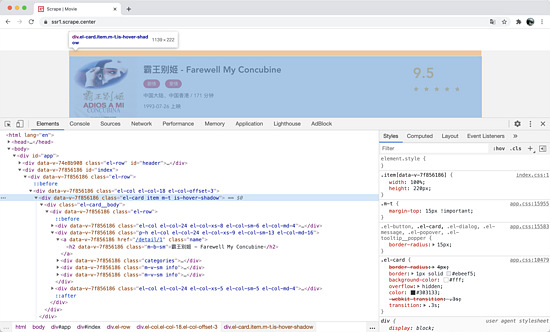
可以看到每部电影对应的区块都是一个 div 节点,它的 class 属性都有 el-card 这个值。每个列表页有 10 个这样的 div 节点,也就对应着 10 部电影的信息。
好,我们再分析下从列表页是怎么进入到详情页的,我们选中电影的名称,看下结果:

可以看到这个名称实际上是一个 h2 节点,其内部的文字就是电影的标题。再看,h2 节点的外面包含了一个 a 节点,这个 a 节点带有 href 属性,这就是一个超链接,其中 href 的值为 /detail/1 ,这是一个相对网站的根 URL https://ssr1.scrape.center/ 的路径,加上网站的根 URL 就构成了 https://ssr1.scrape.center/detail/1 ,也就是这部电影的详情页的 URL。这样我们只需要提取到这个 href 属性就能构造出详情页的 URL 并接着爬取了。
好的,那接下来我们来分析下翻页的逻辑,我们拉到页面的最下方,可以看到分页页码,如图所示:

这里观察到一共有 100 条数据,10 页的内容,因此页码最多是 10。
接着我们点击第二页,如图所示:

可以看到网页的 URL 变成了 https://ssr1.scrape.center/page/2 ,相比根 URL 多了 /page/2 这部分内容。网页的结构还是和原来一模一样,可以和第一页一样处理。
接着我们查看第三页、第四页等内容,可以发现有这么一个规律,其 URL 最后分别变成了 /page/3 、 /page/4 。所以, /page 后面跟的就是列表页的页码,当然第一页也是一样,我们在根 URL 后面加上 /page/1 也是能访问的,只不过网站做了一下处理,默认的页码是 1,所以显示第一页的内容。
好,分析到这里,逻辑基本就清晰了。
所以,我们要完成列表页的爬取,可以这么实现:
- 遍历页码构造 10 页的索引页 URL。
- 从每个索引页分析提取出每个电影的详情页 URL。
好,那么我们写代码来实现一下吧。
首先,我们需要先定义一些基础的变量,并引入一些必要的库,写法如下:
import requests
import logging
import re
from urllib.parse import urljoin
logging.basicConfig(level=logging.INFO,
format='%(asctime)s - %(levelname)s: %(message)s')
BASE_URL = 'https://ssr1.scrape.center'
TOTAL_PAGE = 10
这里我们引入了 requests 用来爬取页面,logging 用来输出信息,re 用来实现正则表达式解析,urljoin 用来做 URL 的拼接。
接着我们定义了下日志输出级别和输出格式,接着定义了 BASE_URL 为当前站点的根 URL,TOTAL_PAGE 为需要爬取的总页码数量。
好,定义好了之后,我们来实现一个页面爬取的方法吧,实现如下:
def scrape_page(url):
logging.info('scraping %s...', url)
try:
response = requests.get(url)
if response.status_code == 200:
return response.text
logging.error('get invalid status code %s while scraping %s', response.status_code, url)
except requests.RequestException:
logging.error('error occurred while scraping %s
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章















 2590
2590











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









