







今天我们分享的主要目的就是通过在 Python 中使用命令行和配置文件来提高代码的效率
Let's go!
我们以机器学习当中的调参过程来进行实践,有三种方式可供选择。第一个选项是使用 argparse,它是一个流行的 Python 模块,专门用于命令行解析;另一种方法是读取 JSON 文件,我们可以在其中放置所有超参数;第三种也是鲜为人知的方法是使用 YAML 文件!好奇吗,让我们开始吧!
先决条件
在下面的代码中,我将使用 Visual Studio Code,这是一个非常高效的集成 Python 开发环境。这个工具的美妙之处在于它通过安装扩展支持每种编程语言,集成终端并允许同时处理大量 Python 脚本和 Jupyter 笔记本
数据集,使用的是 Kaggle 上的共享自行车数据集
使用 argparse
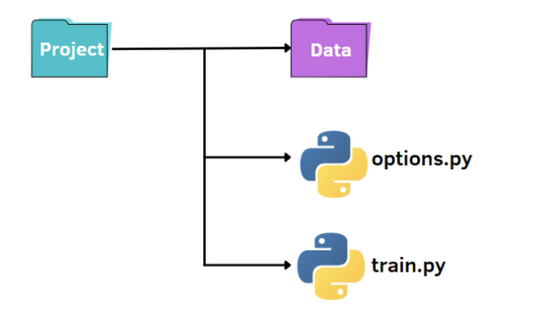
就像上图所示,我们有一个标准的结构来组织我们的小项目:
- 包含我们数据集的名为 data 的文件夹
- train.py 文件
- 用于指定超参数的 options.py 文件
首先,我们可以创建一个文件 train.py,在其中我们有导入数据、在训练数据上训练模型并在测试集上对其进行评估的基本程序:
import pandas as pd import numpy as np from sklearn.ensemble import RandomForestRegres
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章
















 2万+
2万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









