







一、前言
这篇来演示如何使用BeautifulSoup模块来从HTML文本中提取我们想要的数据。
update on 2016-12-28:之前忘记给BeautifulSoup的官网了,今天补上,顺便再补点BeautifulSoup的用法。
update on 2017-08-16:很多网友留言说Unsplash网站改版了,很多内容是动态加载的。所以建议动态加载的内容使用PhantomJS而不是Request库进行请求,如果使用PhantomJS请看我的下一篇博客,如果是定位html文档使用的class等名字更改的话,建议大家根据更改后的内容进行定位,学爬虫重要的是爬取数据的逻辑,逻辑掌握了网站怎么变都不重要啦。
二、运行环境
我的运行环境如下:
-
系统版本
Windows10。 -
Python版本
Python3.5,推荐使用Anaconda 这个科学计算版本,主要是因为它自带一个包管理工具,可以解决有些包安装错误的问题。去Anaconda官网,选择Python3.5版本,然后下载安装。 -
IDE
我使用的是PyCharm,是专门为Python开发的IDE。这是JetBrians的产品,点我下载。
三、模块安装
BeautifulSoup 有多个版本,我们使用BeautifulSoup4。详细使用看BeautifuSoup4官方文档。
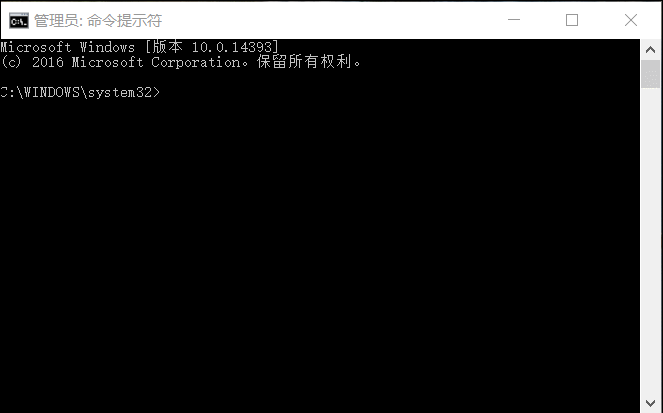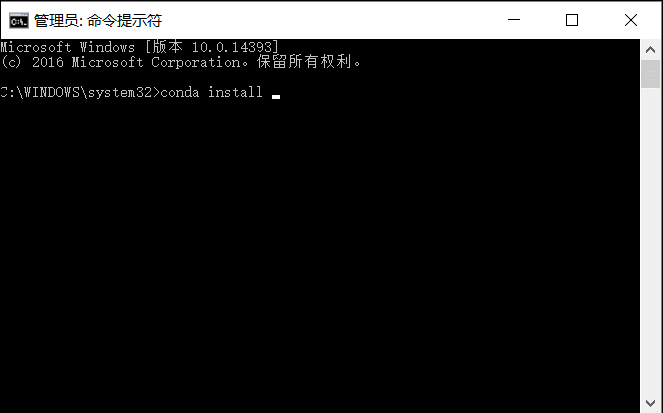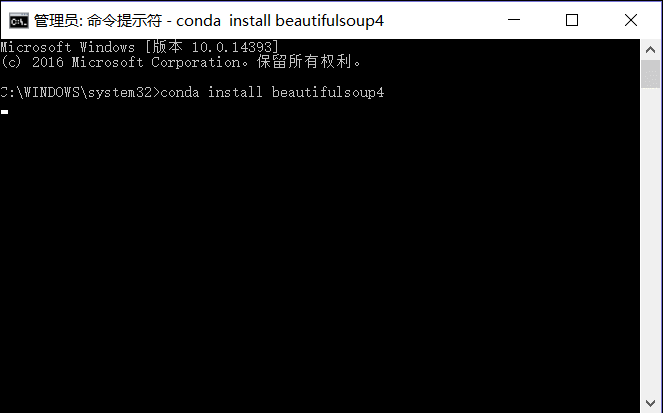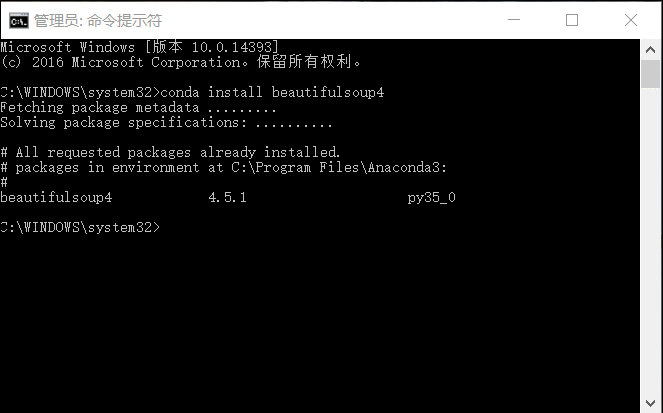
使用管理员权限打开cmd命令窗口,在窗口中输入下面的命令即可安装:conda install beautifulsoup4
直接使用Python3.5 没有使用Anaconda版本的童鞋使用下面命令安装:pip install beautifulsoup4
然后我们安装lxml,这是一个解析器,BeautifulSoup可以使用它来解析HTML,然后提取内容。
Anaconda 使用下面命令安装lxml:conda install lxml
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章















 2296
2296











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









