






垃圾收集算法是内存回收的方法论,垃圾收集器就是内存回收的具体实现:
先列举下常用的垃圾回收器:
Serial收集器
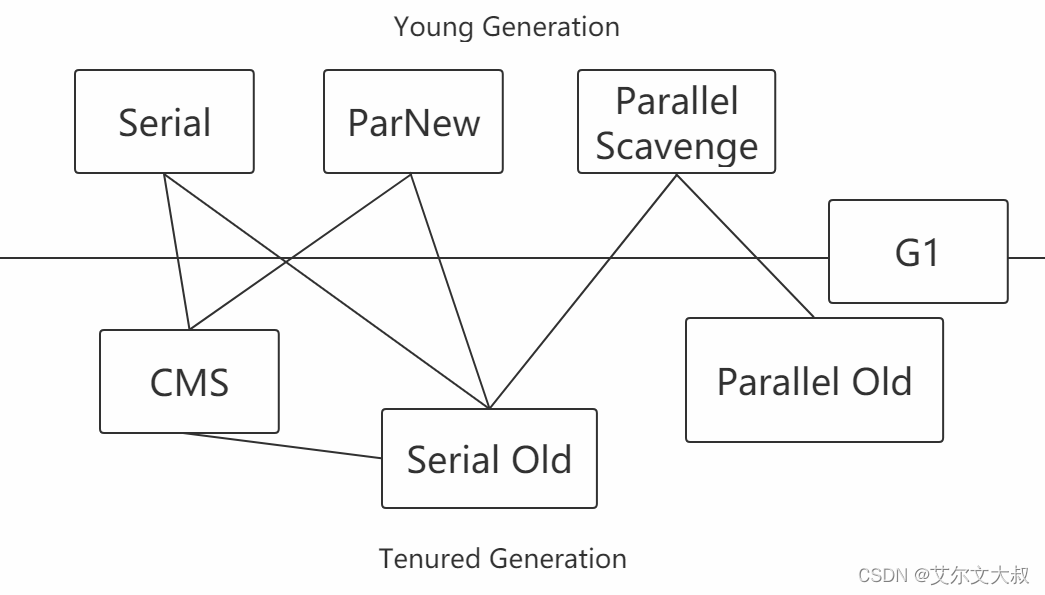
最基本、发展历史最悠久的收集器,曾经(在JDK1.3.1之前)是虚拟机新生代收集的唯一选择。
它是一种单线程收集器,不仅仅意味着它只会使用一个CPU或者一条收集线程去完成垃圾收集工作,更重要的是其在进行垃圾收集的时候需要暂停其他线程。
优点:简单高效,拥有很高的单线程收集效率
缺点:收集过程需要暂停所有线程
算法:复制算法
适用范围:新生代
应用:Client模式下的默认新生代收集器
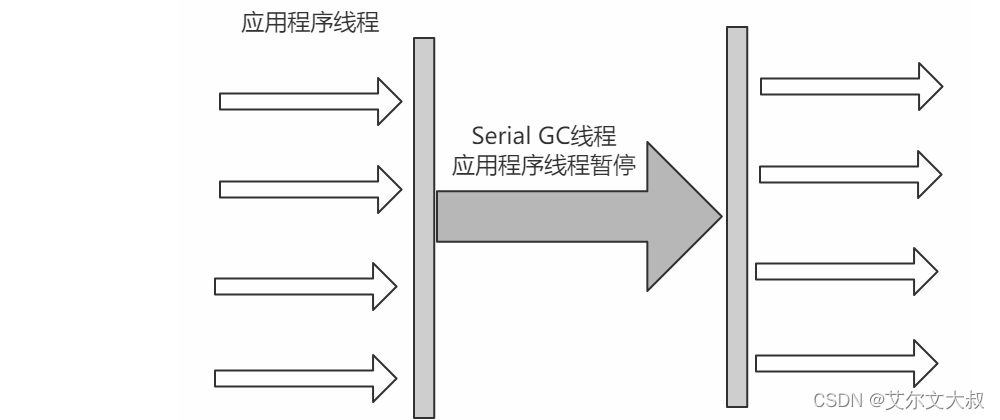
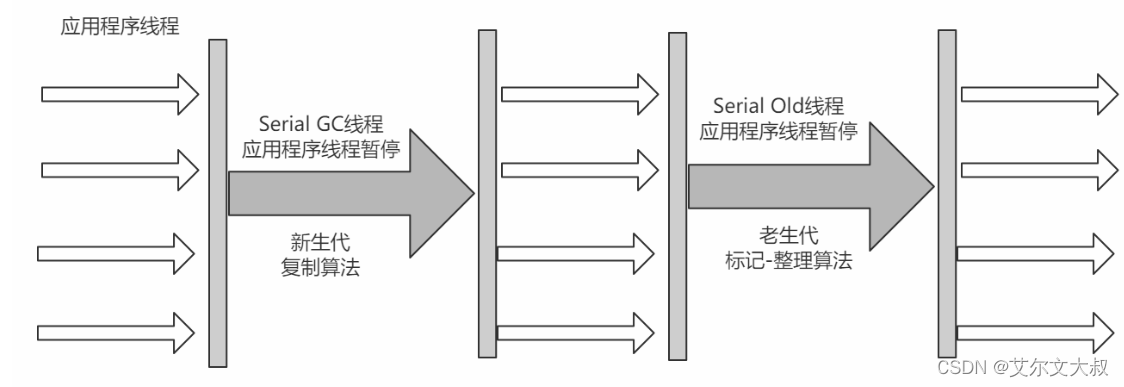
Serial Old收集器
Serial收集器的老年代版本,也是一个单线程收集器,不同的是采用"标记-整理算法",运行过程和Serial收集器一样。
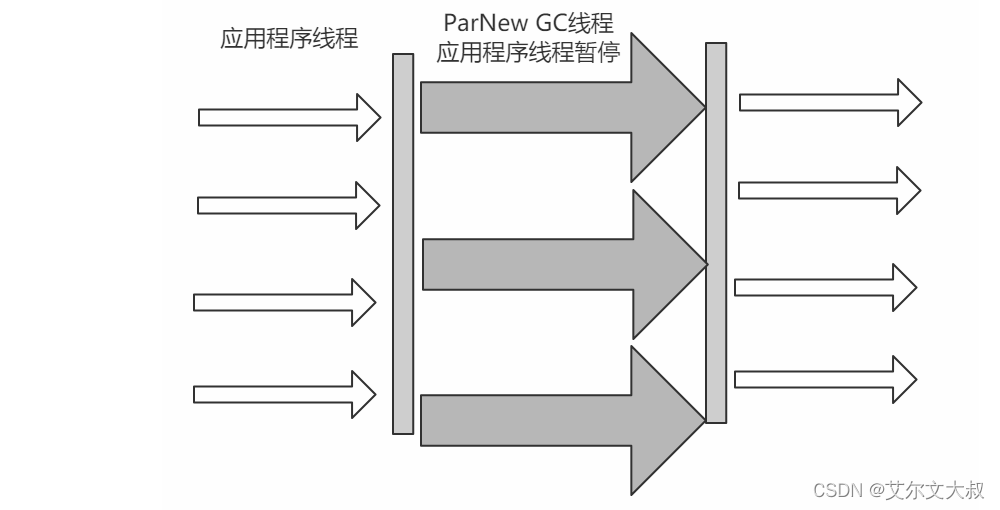
ParNew 可以把这个收集器理解为Serial收集器的多线程版本
优点:在多CPU时,比Serial效率高。
缺点:收集过程暂停所有应用程序线程,单CPU时比Serial效率差。
算法:复制算法
适用范围:新生代
应用:运行在Server模式下的虚拟机中首选的新生代收集器
Parallel Scavenge
它是一个新生代收集器,它也是使用复制算法的收集器,又是并行的多线程收集器,看上去和ParNew一样,但是Parallel Scanvenge更关注系统的吞吐量
配置:
-XX:MaxGCPauseMillis控制最大的垃圾收集停顿时间,
-XX:GCRatio直接设置吞吐量的大小。
吞吐量=用户代码运行的时间/(用户代码运行的时间+垃圾回收时间)
如:你的虚拟机一共运行了100分钟,垃圾回收时间用1分钟,那么吞吐量=(100-1)/100=99%。
所以吞吐量越大,说明着垃圾收集的时间越短,那么用户代码可以充分利用CPU资源,更快完成程序的运算任务
Parallel Old
是Parallel Scavenge收集器的老年代版本,使用多线程和标记-整理算法进行垃圾回收,也是更加关注系统的吞吐量
CMS-Concurrent Mark Sweep
它是以获取最短回收停顿时间(STW)为目标的垃圾收集器
优点:并发收集(可以在应用程序运行时并发收集垃圾,减少了应用程序暂停时间,提高了应用程序的响应性能)、低延迟(回收过程中可以尽可能地减少应用程序的暂停时间)、低停顿(每个阶段的暂停时间都较短)、适合大内存(不需要一次性扫描整个堆空间,所以它可以处理非常大的内存空间,适合于大型应用程序使用)
缺点:产生大量空间碎片、并发阶段会降低吞吐量
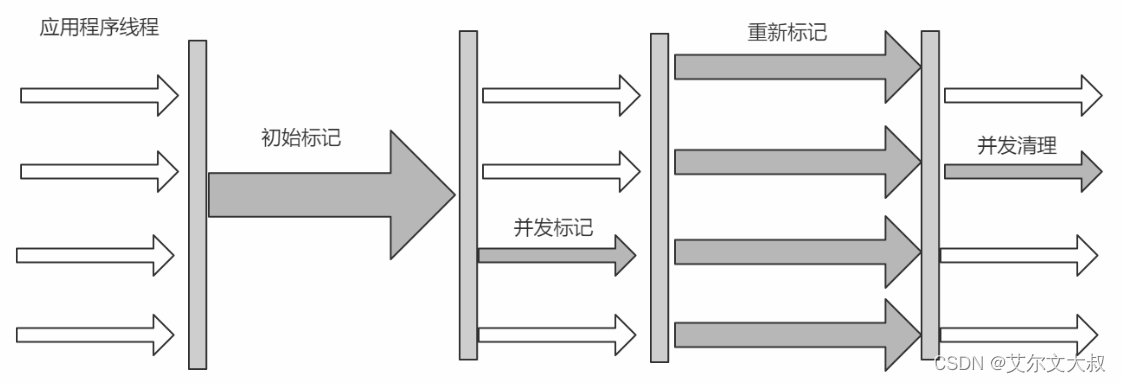
分为4步的"标记-清除算法":
第一步:初始标记 CMS initial mark,标记GC Roots直接关联对象,不需要Tracing,速度快
第二步:并发标记 CMS concurrent mark,进行GC Roots Tracing
第三步:重新标记 CMS remark,修改并发标记因用户程序变动的内容
第四步:并发清除 CMS concurrent sweep,清除不可达对象回收空间,同时也会有新垃圾产生,留着下次清理,称之为浮动垃圾
由于整个过程中,并发标记和并发清除,收集器线程可以与用户线程一起工作,所以总体上来说,CMS收集器的内存回收过程是与用户线程一起并发地执行的。
ZGC
JDK11引入了ZGC收集器,物理上和逻辑上,ZGC中已经不存在新老年代的概念了
它分为一个个的page,当进行GC操作时会对page进行压缩,因此不存在碎片问题
但是它只能在64位的linux上使用,目前用得还比较少。
优点:
1.可以达到10ms以内的停顿时间要求
2.支持TB级别的内存
3.堆内存变大后停顿时间还是在10ms以内
















 1142
1142











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









