






为什么需要分布式ID?分布式ID的可选方案,优缺点?
基础数据类型:
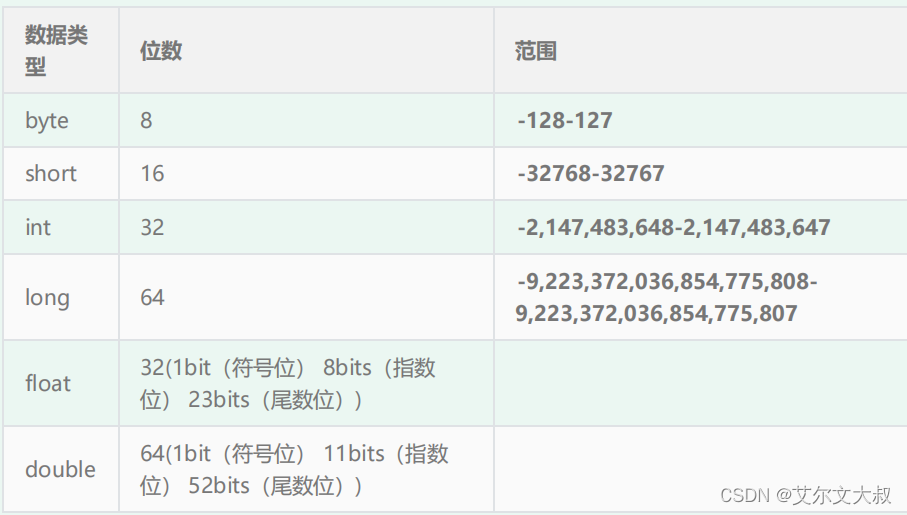
int类型最大值10亿级别(数量级,明显不够用)
float和double,存在不精准运算,有效位数并不大,占用字节最大同long
综合考量:long类型数据规很大,足够应用在ID策略上了
负数如何存储
位运算:&。如果两个对应的二进制位上的数都是1,结果是1,其他都是0

按位或:|。如果两个对应的二进制位上的数都是0,结果是0,其他都是1

按位异或:^。如果两个对应的二进制位上的数字相同,则运算结果为0,其他都是1
左移:<<。把二进制数据在内存空间中向左边移动。左移n相当于乘以2的n次方,但要注意两
点:1-左移带有符号位的,说明每个数据类型左移都有位数限制;2-左移后原来的值不变,移位
后是一个新的值
补码:该数的原码除符号位外各位取反,然后在最后一位加1
-1L去除符号位原码:
取反:
加1:
原理分析
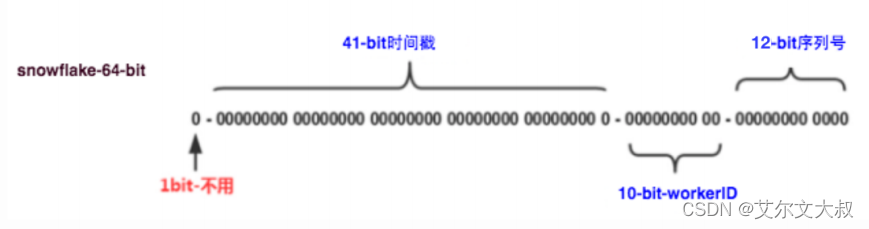
前置条件:单机,机器中心:31机器号吗:31
workID:可认为是机器特征号码,一般由两部分组成:数据中心+机器号,各占用5位。也就是最
大值2^5*2^5=2^10=1024个值(0-1023)
单机情况下,如果不考虑时钟回拨,上图中,workID对于单机固定,12位序列化的变化范围为:
2^12=4096个值(0-4095)
这么分析,单机该种算法,每一毫秒可产生4096个可用不重复的序列号
1s内4096*1000=4096000个。足够很多场景下使用了。
时间部分:

69年都不会重复,既然只能使用69年,我们系统中的时间,是从1970年开始的,所以设计上,设
置一个起始时间,也就是项目开始的时间,目的为了使用更久的时间
代码:
publicsynchronized
long
nextId
(){
long
timestamp
=
timeGen
();
if
(
timestamp
<
lastTimestamp
){
System
.
err
.
printf
(
"clockismovingbackwards.Rejectingrequestsuntil%d."
,
lastTimestamp
);
thrownewRuntimeException
(
String
.format
(
"Clockmovedbackwards.Refusingtogenerate
idfor%dmilliseconds"
,
lastTimestamp
-
timestamp
));
if
(
lastTimestamp
==
timestamp
){
sequence
=
(
sequence
+
1
)
&
sequenceMask
;
if
(
sequence
==
0
){
timestamp
=
tilNextMillis
(
lastTimestamp
);
}
}
else
{
sequence
=
0
;
}
lastTimestamp
=
timestamp
;
return
((
timestamp
-
twepoch
)
<<
timestampLeftShift
)
|
(
datacenterId
<<
datacenterIdShift
)
|
(
workerId
<<
workerIdShift
)
|
sequence
;
}
if (timestamp < lastTimestamp) { //lastTimestamp,上次生成时间,本次生成时间
timestamp ,如果小于,说明时钟回拨
if (lastTimestamp == timestamp) {//说明两次生成ID的时间戳在同一毫秒内,否则,每一s从0
开始生成最后的序列号。
最终如何组成结果:
return ((timestamp - twepoch) << timestampLeftShift) |
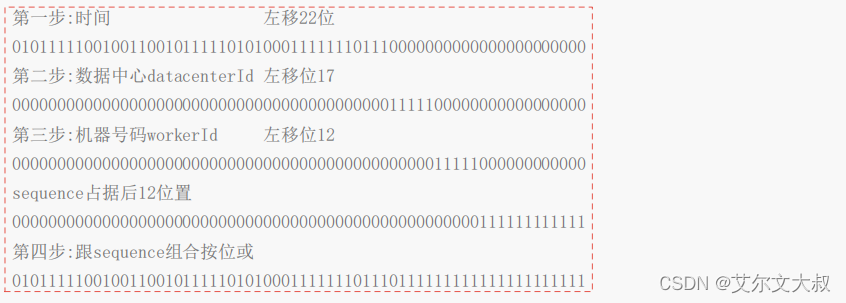
(datacenterId << datacenterIdShift) |
(workerId << workerIdShift) |
sequence;
每一个号段向左移位置,在按位或,如下图:
这里解释了最终结果的构成,非常巧妙,综合了性能,变化点,生成了非常完美,不容易重合的一
个long数字,那么问题只剩下,相同时间如何拿到后边的12位序列了
if(lastTimestamp==timestamp){
//如果等走到这里:说明来给你个问题,第一:肯定生成过一次序列,那么sequence一定不可能从0开始
//sequenceMark=-1L^(-1L<<sequenceBits)经过前面基础知识,可知
//sequenceMask=0000000000000000000000000000000000000000000000000000111111111111
//如果sequence=0,说明:
//sequence+1=0000000000000000000000000000000000000000000000000001000000000000
//sequence= 0000000000000000000000000000000000000000000000000000111111111111
//说明此时sequence=4095,及已经增长到最大值
//初始进入此条件的时候,sequence=
0000000000000000000000000000000000000000000000000000000000000000
//经过sequence=(sequence+1)&sequenceMask;
//sequence=0000000000000000000000000000000000000000000000000000000000000001
sequence=(sequence+1)&sequenceMask;
//如果此处等于零,相当于4095之后,在同一秒内再次需要生成序列,此时根据设计12位,已经不能在生成
了,所以,相当于系统调整了下时间,把当前时间修改到下一秒钟,参考tilNextMillis(lastTimestamp),不难理解了。
if(sequence==0){timestamp=tilNextMillis(lastTimestamp);
}
}
存在的问题:
问题1:
雪花算法的设计等价于单台机器
不变(符号位置)+变化(时间戳)+不变(最大31)+不变(最大31)+变化(0-+4096)
多台机器
不变(符号位置)(不变)+变化(时间戳)(多机会重复)+(不变(最大31)()+不变(最大31))
(组合不变)+变化(0-+4096)(可能重复)
等价于:
不变+不变+(变化)(自由组合)+不变
自由组合:可以分成2段,也可以是云主机一段,每个IP不通即可
问题2:时间回拨
这种设计,严重依赖服务器的时间,但是时间,不仅是哲学家的难题,也是计算机领域的一大难
题,至少linux上,存在时间同步等产生的时间跳跃问题,在分布式环境中,如果事件发生回拨,
则很大概率产生重复的ID。















 145
145











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









